Computational Linear Algebra
|
|
|
- Brandon Walton
- 5 years ago
- Views:
Transcription
1 Computational Linear Algebra PD Dr. rer. nat. habil. Ralf-Peter Mundani Computation in Engineering / BGU Scientific Computing in Computer Science / INF Winter Term 2018/19
2 Part 4: Iterative Methods PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 2
3 overview definitions splitting methods projection and KRYLOV subspace methods multigrid methods PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 3
 where x 0 is arbitrary and K m and L m represent m-dimensional subspaces of. Here, orthogonality is defined via the EUCLIDEAN dot product x y (x, y) 2 = 0. PD Dr.")
4 basic concept we consider linear systems of type Ax = b (4.2.1) with regular matrix A and right-hand side b Definition 4.18 A projection method for solving (4.2.1) is a technique that computes approximate solutions x m x 0 + K m under consideration of (b Ax m ) L m, (4.2.2) where x 0 is arbitrary and K m and L m represent m-dimensional subspaces of. Here, orthogonality is defined via the EUCLIDEAN dot product x y (x, y) 2 = 0. PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 4
5 basic concept (cont d) observation in case K m = L m, the residual vector r m = b Ax m is perpendicular to K m we obtain an orthogonal projection method and (4.2.2) is called GALERKIN condition in case K m L m, we obtain a skew projection and (4.2.2) is called PETROV-GALERKIN condition splitting methods projection methods computation of approximated solutions x m Rn x m x 0 + K m Rn dim K m = m n computation method x m = Mx m 1 + Nb b Ax m L m Rn dim L m = m n PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 5
6 basic concept (cont d) Definition 4.19 A KRYLOV subspace method is a projection method for solving (4.2.1), where K m represents the KRYLOV subspace with r 0 = b Ax 0. K m = K m (A, r 0 ) = span {r 0, Ar 0,..., A m 1 r 0 } KRYLOV subspace methods are often described as reformulation of a linear system into a minimisation problem well-known methods are conjugate gradients (HESTENES & STIEFEL, 1952) and GMRES (SAAD & SCHULTZ, 1986) both methods compute the optimal approximation x m x 0 + K m w.r.t. (4.2.2) via incrementing the subspace dimension in every iteration by one neglecting round-off errors, both methods would compute the exact solution at latest after n iterations PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 6
7 overview CG method simultaneously consider: Ax = b and A T x = b BiCG method avoid multiplication with A T minimise: GMRES method combination of BiCG and GMRES CGS method avoid oscillations for residual QMR method avoid multiplication with A T BiCGSTAB method TFQMR method PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 7
8 method of steepest descent note: for further considerations, we assume the linear system (4.2.1) to exhibit a symmetric and positive definite (SPD) matrix we further consider functions F : x ½(Ax, x) 2 (b, x) 2 (4.2.3) and will first study some of their properties in order to derive the method Lemma 4.20 Let A be symmetric, positive definite and b given, then for a function F defined via (4.2.3) applies iff x ˆ = arg min F(x) Ax ˆ = b. PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 8
 PD Dr.")

9 method of steepest descent (cont d) PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 9
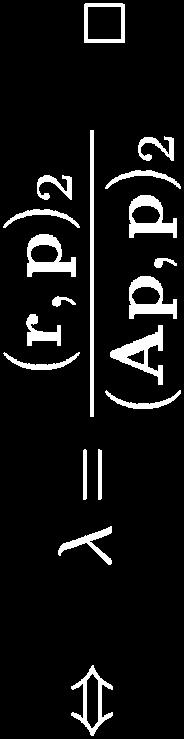
10 method of steepest descent (cont d) idea: we want to achieve a successive minimisation of F based on point x along particular directions p hence, we define for x, p a function f x, p : λ f x, p (λ) := F(x + λp) Lemma and Definition 4.21 Let matrix A be symmetric, positive definite and vectors x, p with p 0 given, hence (r, p) λ opt = λ opt (x, p) := arg min f x, p (λ) = 2 λ (Ap, p) 2 applies with r := b Ax. Vector r is denoted as residual vector and its EUCLIDEAN norm r 2 as residual. PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 10

")



11 method of steepest descent (cont d) PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 11
12 method of steepest descent (cont d) with given sequence {p m } m of search directions out of \ {0}, we can determine a first method basic solver choose x 0 for m = 0, 1,... r m = b Ax m λ m = (r m, p m ) 2 (Ap m, p m ) 2 x m+1 = x m + λ m p m in order to complete our basic solver, we need a method to compute search directions p m PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 12
13 method of steepest descent (cont d) further (w/o loss of generality), we request p m 2 = 1 for x A 1 b we achieve a globally optimal choice via ˆx x p = with x ˆ = A 1 b, xˆ x 2 as hereby follows for definition of λ opt according to 4.21 x = x + λ opt p = x + xˆ x 2 = xˆ (b Ax, xˆ x) 2 xˆ x (b Ax, xˆ x) 2 xˆ x 2 however, this approach requires the knowledge of the exact solution xˆ for computing search directions PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 13
14 method of steepest descent (cont d) restricting to local optimality, search directions can be computed with the negative gradient of F here applies, hence F(x) = ½(A + A T )x b = Ax b = r p := yields the direction of steepest descent function F is due to 2 F(x) = A and SPD matrix A strictly convex it is obvious that x ˆ = A 1 b due to F(x) ˆ = 0 represents the only and global minimum of F PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 14 A sym. r for r 0 r 2 0 for r = 0 (4.2.4)
15 method of steepest descent (cont d) hence, we obtain the method of steepest decent (a.k.a. gradient method) choose x 0 for m = 0, 1,... r m = b Ax m Y r m 0 N λ m = r m 2 2 (Ar m, r m ) 2 λ m = 0 x m+1 = x m + λ m r m for practical applications, r 0 is computed outside the loop and inside with r m+1 = b Ax m+1 = b Ax m λ m Ar m = r m λ m Ar m one matrix-vector multiplication per iteration can be avoided PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 15






16 method of steepest descent (cont d) example: consider Ax = b with A =, b =, x 0 = thus, we get the following convergence m x m,1 method of steepest descent x m,2 ε m := x m A 1 b A e e e e e e e e e e e e e e e 15 PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 16
17 method of steepest descent (cont d) what s happening here? λ 1 = 2, λ 2 = 10 x 2 x 0 x 4 x 2 x 3 x 1 x 1 contour lines of F denote convergence process stretched ellipses due to different large values of diagonal entries of A residual vector always points into the direction of point of origin, but the approximated solution might change its sign in every single iteration motivates further considerations w.r.t. optimality of search directions PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 17
18 method of steepest descent (cont d) some thoughts about optimality Definition 4.22 Let F : be given, then x is called (a) optimal w.r.t. direction p if F(x) F(x + λp) for all λ applies, (b) optimal w.r.t. subspace U if F(x) F(x + ξ) for all ξ U applies. Lemma 4.23 Let F according to (4.2.3) be given, then x U if r = b Ax U applies. is optimal w.r.t. PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 18
19 method of steepest descent (cont d) observation: the gradient method represents in every step a projection method with K = L = span {r m 1 } obviously, optimality of the approximated solution concerning entire subspace U = span {r 0, r 1,..., r m 1 } would be preferable for linearly independent residual vectors hereby at the latest follows x n = A 1 b for the method of steepest descent all approximated solutions x m are optimal concerning r m 1 only due to missing transitivity of condition r p does not (necessarily) follow r m 2 r m from r m 2 r m 1 and r m 1 r m remedy: method of conjugated directions PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 19


20 method of conjugate directions idea: extend optimality of approximated solution x m to entire subspace U = span {p 0,..., p m 1 } with linearly independent search directions p i the following theorem formulates a condition for search directions that assures optimality w.r.t. U m in the (m+1)-st iteration step Theorem 4.24 Let F according to (4.2.3) be given and x be optimal w.r.t. subspace U = span {p 0,..., p m 1 }, then x = x + ξ is optimal w.r.t. U iff applies. Aξ U PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 20
21 method of conjugate directions (cont d) if for search direction p m either Ap m U m = span {p 0,..., p m 1 } or equivalent Ap m p j, j = 0,..., m 1 applies, then the approximated solution x m+1 = x m + λ m p m inherits according to 4.24 optimality from x m w.r.t. U m independent from the choice of scalar weighting factor λ m this degree of freedom λ m will be used further to extend optimality w.r.t. U m+1 = span {p 0,..., p m } PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 21
 Definition 4.")

 A := (Ap i, p j ) 2 = 0 i, j {0,.")



22 method of conjugate directions (cont d) Definition 4.25 Let A, then vectors p 0,..., p m are called pairwise conjugated or A-orthogonal if (p i, p j ) A := (Ap i, p j ) 2 = 0 i, j {0,..., m} and i j. Lemma 4.26 Let A be a symmetric and positive definite matrix and p 0,..., p m 1 \ {0} be pairwise A-orthogonal, then dim span {p 0,..., p m 1 }=m for m = 1,, n applies. PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 22
23 method of conjugate directions (cont d) (4.26) shows one important property of the method that lies within the successive dimensional increment of subspaces {U m } m = 0, 1, let with p 0,..., p m \ {0} pairwise conjugate search directions be given and x m be optimal w.r.t. U m = span {p 0,..., p m 1 }, thus we get optimality of w.r.t. U m+1 if x m+1 = x m + λp m 0 = (b Ax m+1, p j ) 2 = (b Ax m, p j ) 2 λ(ap m, p j ) 2 for j = 0,..., m applies = 0 for j m = 0 for j m PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 23


24 method of conjugate directions (cont d) for λ we yield the following representation and, thus, obtain the method of conjugate directions choose x 0 r 0 = b Ax 0 for m = 0, 1,..., n 1 λ m = (r m, p m ) 2 (Ap m, p m ) 2 x m+1 = x m + λ m p m r m+1 = r m λ m Ap m if search directions are chosen inappropriate, x n can yield the exact solution even x n 1 still has a large error for given search directions the method can only be used as direct one, which leads for large n to huge computational complexity hence, problem-oriented choice of search directions is inevitable PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 24
25 CG: method of conjugate gradients combination of methods of steepest descent and conjugate directions in order to obtain a problem-oriented approach w.r.t. selection of search directions and optimality w.r.t. orthogonality of search directions with residual vectors r 0,..., r m we successively determine search directions for m = 0,..., n 1 according to p 0 = r 0 p m = r m + α j p j (4.2.5) for α j = 0 (j = 0,..., m 1) we achieve an analogous selection of search directions according to method of steepest descent hence, under consideration of already used search directions p 0,..., p m 1 \ {0} exist m degrees of freedom in choosing α j to assure search directions to be conjugated PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 25
 follows 0 = (Ap m, p i ) 2 = (Ar m, p i ) 2 + α j (Ap j, p i ) 2 for i = 0,.")

26 CG: method of conjugate gradients (cont d) from required A-orthogonality constraint using (4.2.5) follows 0 = (Ap m, p i ) 2 = (Ar m, p i ) 2 + α j (Ap j, p i ) 2 for i = 0,..., m 1 hence, with (Ap j, p i ) 2 = 0 for i, j {0,..., m 1} and i j we obtain the wanted algorithm to compute coefficients α i = (4.2.6) (Ar m, p i ) 2 (Ap i, p i ) 2 PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 26
 2 (Ap m, p m ) 2 x m+1 = x m + λ m p m r m+1 = r m λ m Ap m p m+1 = r m+1 (Ar m+1, p j ) 2 (Ap j, p j ) 2 p j PD Dr.")
27 CG: method of conjugate gradients (cont d) thus we obtain the preliminary method of conjugate gradients choose x 0 p 0 = r 0 = b Ax 0 for m = 0, 1,..., n 1 λ m = (r m, p m ) 2 (Ap m, p m ) 2 x m+1 = x m + λ m p m r m+1 = r m λ m Ap m p m+1 = r m+1 (Ar m+1, p j ) 2 (Ap j, p j ) 2 p j PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 27
 are necessary due to p m+1 = r m+1 (Ar m+1, p j ) 2 (Ap j, p j ) 2 p j in case method does not stop before computation of p k for k > 0, then (a) p m is conjugated to all p j with 0 j < m k")
28 CG: method of conjugate gradients (cont d) problem: for computation of p m+1 all p j (j = 0,..., m) are necessary due to p m+1 = r m+1 (Ar m+1, p j ) 2 (Ap j, p j ) 2 p j in case method does not stop before computation of p k for k > 0, then (a) p m is conjugated to all p j with 0 j < m k due to (4.2.5) and (4.2.6), (b) U m+1 = span {p 0,, p m }=span {r 0,, r m } with dim U m+1 = m + 1 for m = 0,, k 1, (c) r m U m for m = 1,, k, (d) x k = A 1 b r k = 0 p k = 0, (e) U m+1 = span {r 0,, A m r 0 } for m = 0,, k 1, (f) r m is conjugated to all p j with 0 j < m 1 < k 1. (Proof is lengthy ) PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 28
29 CG: method of conjugate gradients (cont d) w.r.t. (f): for 0 j < m 1 k 1 follows p j U m 1, hence Ap j U m applies and we get A symm. (Ar m, p j ) 2 = (r m, Ap j ) 2 = 0 from (f) follows (Ar m, p j ) 2 (Ar m, p m 1 ) 2 p m = r m p j = r m p (Ap m 1 (4.2.7) j, p j ) 2 (Ap m 1, p m 1 ) 2 (c) furthermore, the method can stop in the k+1-st iteration if p k = 0, i.e. according to (d) the solution x k = A 1 b has been found p k to be used as termination criteria in the final algorithm, as termination criteria w/o further computation the residual will be used PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 29

 for r m+1")


 reveals thus")
 follows (r m, r")
 2 for λ m 0,")



30 CG: method of conjugate gradients (cont d) from (c) for r m+1 = r m λ m Ap m follows (r m λ m Ap m, r m ) 2 = 0, hence (4.2.8) using (4.2.7) reveals thus with (4.2.8) follows (r m, r m ) 2 = (r m, p m ) 2 for λ m 0, from preliminary method follows Ap m = (r m+1 r m ), thus A sym. (b), (c) PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 30
31 CG: method of conjugate gradients (cont d) hence, only one matrix-vector multiplication per iteration necessary choose x 0 2 p 0 = r 0 = b Ax 0, α 0 = r 0 2 for m = 0, 1,..., n 1 Y α m 0 N v m = Ap m, λ m = α m (v m, p m ) 2 x m+1 = x m + λ m p m STOP r m+1 = r m λ m v m α r m+1 2 m+1 = 2 p m+1 = r m+1 + α m+1 α m p m PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 31

32 source: sciencecartoonsplus.com ( S. Harris) PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 32




33 preliminary consideration with {v 1,, v j } let some orthogonal basis of K j = span {r 0,, A j 1 r 0 } for j = 1,, m be given due to AK m = span {Ar 0,, A m r 0 } K m+1 the idea rises to write v m+1 as v m+1 = Av m + ξ with ξ span {v 1,, v m }=K m with ξ = follows (v m+1, v j ) 2 = (Av m, v j ) 2 α j (v j, v j ) 2 whereby due to orthogonality condition for j = 1,, m applies in case of normed base vectors, computation simplifies to α j = (Av m, v j ) 2 PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 33
")


 2 w j = Av j h j+1, j")


34 preliminary consideration (cont d) for r 0 0 follows the ARNOLDI algorithm v 1 = (4.2.9) for j = 1,..., m for i = 1,..., j h ij = (v i, Av j ) 2 w j = Av j h j+1, j = Y v j+1 = h j+1, j 0 v j+1 = 0 STOP N PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 34
35 preliminary consideration (cont d) provided that ARNOLDI does not halt before computation of v m 0, then V j ={v 1,, v j } represents an orthonormal basis of the j-th KRYLOV subspace K j for j = 1,, m using V m = (v 1 v m ) we get with an upper HESSENBERG matrix, for which applies (H m ) ij = h ij from ARNOLDI algorithm for i j for i > j + 1 provided that ARNOLDI does not halt before computation of v m+1, then AV m = V m+1 H m applies with H m given by H m = H m 0 0 h m+1, m (4.2.10) PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 35
 Lemma 4.27 Let A be regular and b given, then for function F defined via (4.2.11) applies iff Ax ˆ = b. x ˆ = arg min F(x) PD Dr.")
36 GMRES: generalised minimal residual in contrast to CG method, GMRES works for arbitrary regular matrices conforms to projection method with PETROV-GALERKIN condition L m = AK m we define function F : (4.2.11) Lemma 4.27 Let A be regular and b given, then for function F defined via (4.2.11) applies iff Ax ˆ = b. x ˆ = arg min F(x) PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 36
 be given and x 0 be arbitrary.")
 PD Dr.")
37 GMRES: generalised minimal residual (cont d) Lemma 4.28 Let F : according to (4.2.11) be given and x 0 be arbitrary. Then follows iff (4.2.12) applies. (Proof is very lengthy ) PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 37
, hence any x m x 0 + K m can be written as x m = x 0 + V m α m with α m with J m : the minimisation problem (4.2.")

38 GMRES: generalised minimal residual (cont d) GMRES based on ARNOLDI for computation of ONB {v 1,, v m } of K m let V m = (v 1 v m ), hence any x m x 0 + K m can be written as x m = x 0 + V m α m with α m with J m : the minimisation problem (4.2.12) is equivalent to α m = arg min J m (α) x m = x 0 + V m α m hence, two central objectives are to find a simple computation of α m and to compute α m only in case b Ax m 2 ε for given ε > 0 PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 38
39 GMRES: generalised minimal residual (cont d) with r 0 = b Ax 0 and e 1 = (1, 0,, 0) T follows J m (α) = b A(x 0 + V m α) 2 = r 0 AV m α 2 (4.2.9) = r 0 2 v 1 AV m α 2 (4.2.10) = r 0 2 v 1 V m+1 H m α 2 = V m+1 ( r 0 2 e 1 H m α) 2 where H m represents matrix (4.2.13) H m = H m 0 0 h m+1, m with right upper HESSENBERG matrix H m PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 39




40 GMRES: generalised minimal residual (cont d) advantage: due to structure of matrix H m computation of minimal error w/o explicit calculation of x m (i.e. computation only if b Ax m 2 ε) Lemma 4.29 Provided that the ARNOLDI algorithm does not terminate before computation of v m+1 and matrices G i+1, i for i = 1,, m via are given with c i and s i defined as PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 40
 (Lemma 4.")
 i, i and")
 i+1, i, then Q m = G m+1, m")

 PD Dr.")

41 GMRES: generalised minimal residual (cont d) (Lemma 4.29 cont d) and with a = (G i, i 1 G 3,2 G 2,1 H m ) i, i and b = (G i, i 1 G 3,2 G 2,1 H m ) i+1, i, then Q m = G m+1, m G 2,1 is an orthogonal matrix for which Q m H m = R m with applies and R m being regular. (Proof is lengthy ) PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 41
42 GMRES: generalised minimal residual (cont d) with Q m and e 1 = (1, 0,, 0) T follows g m = r 0 2 Q m e 1 = (γ 1,, γ m, γ m+1 ) T = (gt m, γ m+1 ) T (4.2.14) hence, with (4.2.13) in case of v m+1 0 follows min J m (α) = min V m+1 ( r 0 2 e 1 H m α) 2 = min r 0 2 e 1 H m α 2 = min Q m ( r 0 2 e 1 H m α) 2 Lemma 4.29 = min g m R m α 2 = min due to regularity of R m follows min J m (α) = γ m+1 PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 42
43 GMRES: generalised minimal residual (cont d) some observations i. in case v m+1 = 0 follows min J m (α) = min V m ( r 0 2 e 1 H m α) 2 = min g m R m α 2 = 0 hence, in case min J m (α) = γ m+1 =0 the algorithm can terminate and the exact solution has been found ii. with γ 1,, γ m+1 according to (4.2.14) follows r j 2 = γ j+1 γ j = r j 1 2 for j = 1,, m finally, we get the GMRES algorithm PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 43












44 choose x 0 and compute r 0 = b Ax 0 v 1 =, γ 1 = r 0 2 for j = 1,, n h ij = (v i, Av j ) 2 for i = 1,, j GMRES algorithm c j γ j w j = Av j h ij v i, h j+1, j = w j 2 for i = 1,, j 1 β =, s j =, c j =, h jj = β γ j+1 = s j γ j, γ j = γj+1 = 0 Y for i = j,, 1 N STOP PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 44
45 overview definitions splitting methods projection and KRYLOV subspace methods multigrid methods PD Dr. Ralf-Peter Mundani Computational Linear Algebra Winter Term 2018/19 45
Computational Linear Algebra
 Computational Linear Algebra PD Dr. rer. nat. habil. Ralf Peter Mundani Computation in Engineering / BGU Scientific Computing in Computer Science / INF Winter Term 2017/18 Part 3: Iterative Methods PD
Computational Linear Algebra PD Dr. rer. nat. habil. Ralf Peter Mundani Computation in Engineering / BGU Scientific Computing in Computer Science / INF Winter Term 2017/18 Part 3: Iterative Methods PD
Computational Linear Algebra
 Computational Linear Algebra PD Dr. rer. nat. habil. Ralf Peter Mundani Computation in Engineering / BGU Scientific Computing in Computer Science / INF Winter Term 2017/18 Part 3: Iterative Methods PD
Computational Linear Algebra PD Dr. rer. nat. habil. Ralf Peter Mundani Computation in Engineering / BGU Scientific Computing in Computer Science / INF Winter Term 2017/18 Part 3: Iterative Methods PD
Computational Linear Algebra
 Computational Linear Algebra PD Dr. rer. nat. habil. Ralf Peter Mundani Computation in Engineering / BGU Scientific Computing in Computer Science / INF Winter Term 2017/18 Part 2: Direct Methods PD Dr.
Computational Linear Algebra PD Dr. rer. nat. habil. Ralf Peter Mundani Computation in Engineering / BGU Scientific Computing in Computer Science / INF Winter Term 2017/18 Part 2: Direct Methods PD Dr.
Summary of Iterative Methods for Non-symmetric Linear Equations That Are Related to the Conjugate Gradient (CG) Method
 Method") Summary of Iterative Methods for Non-symmetric Linear Equations That Are Related to the Conjugate Gradient (CG) Method Leslie Foster 11-5-2012 We will discuss the FOM (full orthogonalization method), CG,
Summary of Iterative Methods for Non-symmetric Linear Equations That Are Related to the Conjugate Gradient (CG) Method Leslie Foster 11-5-2012 We will discuss the FOM (full orthogonalization method), CG,
M.A. Botchev. September 5, 2014
 Rome-Moscow school of Matrix Methods and Applied Linear Algebra 2014 A short introduction to Krylov subspaces for linear systems, matrix functions and inexact Newton methods. Plan and exercises. M.A. Botchev
Rome-Moscow school of Matrix Methods and Applied Linear Algebra 2014 A short introduction to Krylov subspaces for linear systems, matrix functions and inexact Newton methods. Plan and exercises. M.A. Botchev
Computational Linear Algebra
 Computational Linear Algebra PD Dr. rer. nat. habil. Ralf-Peter Mundani Computation in Engineering / BGU Scientific Computing in Computer Science / INF Winter Term 2018/19 Part 4: Iterative Methods PD
Computational Linear Algebra PD Dr. rer. nat. habil. Ralf-Peter Mundani Computation in Engineering / BGU Scientific Computing in Computer Science / INF Winter Term 2018/19 Part 4: Iterative Methods PD
Iterative methods for Linear System
 Iterative methods for Linear System JASS 2009 Student: Rishi Patil Advisor: Prof. Thomas Huckle Outline Basics: Matrices and their properties Eigenvalues, Condition Number Iterative Methods Direct and
Iterative methods for Linear System JASS 2009 Student: Rishi Patil Advisor: Prof. Thomas Huckle Outline Basics: Matrices and their properties Eigenvalues, Condition Number Iterative Methods Direct and
4.8 Arnoldi Iteration, Krylov Subspaces and GMRES
 48 Arnoldi Iteration, Krylov Subspaces and GMRES We start with the problem of using a similarity transformation to convert an n n matrix A to upper Hessenberg form H, ie, A = QHQ, (30) with an appropriate
48 Arnoldi Iteration, Krylov Subspaces and GMRES We start with the problem of using a similarity transformation to convert an n n matrix A to upper Hessenberg form H, ie, A = QHQ, (30) with an appropriate
FEM and sparse linear system solving
 FEM & sparse linear system solving, Lecture 9, Nov 19, 2017 1/36 Lecture 9, Nov 17, 2017: Krylov space methods http://people.inf.ethz.ch/arbenz/fem17 Peter Arbenz Computer Science Department, ETH Zürich
FEM & sparse linear system solving, Lecture 9, Nov 19, 2017 1/36 Lecture 9, Nov 17, 2017: Krylov space methods http://people.inf.ethz.ch/arbenz/fem17 Peter Arbenz Computer Science Department, ETH Zürich
AMS526: Numerical Analysis I (Numerical Linear Algebra)
") AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 23: GMRES and Other Krylov Subspace Methods Xiangmin Jiao SUNY Stony Brook Xiangmin Jiao Numerical Analysis I 1 / 9 Minimizing Residual CG
AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 23: GMRES and Other Krylov Subspace Methods Xiangmin Jiao SUNY Stony Brook Xiangmin Jiao Numerical Analysis I 1 / 9 Minimizing Residual CG
Lecture 17 Methods for System of Linear Equations: Part 2. Songting Luo. Department of Mathematics Iowa State University
 Lecture 17 Methods for System of Linear Equations: Part 2 Songting Luo Department of Mathematics Iowa State University MATH 481 Numerical Methods for Differential Equations Songting Luo ( Department of
Lecture 17 Methods for System of Linear Equations: Part 2 Songting Luo Department of Mathematics Iowa State University MATH 481 Numerical Methods for Differential Equations Songting Luo ( Department of
Topics. The CG Algorithm Algorithmic Options CG s Two Main Convergence Theorems
 Topics The CG Algorithm Algorithmic Options CG s Two Main Convergence Theorems What about non-spd systems? Methods requiring small history Methods requiring large history Summary of solvers 1 / 52 Conjugate
Topics The CG Algorithm Algorithmic Options CG s Two Main Convergence Theorems What about non-spd systems? Methods requiring small history Methods requiring large history Summary of solvers 1 / 52 Conjugate
Conjugate gradient method. Descent method. Conjugate search direction. Conjugate Gradient Algorithm (294)
") Conjugate gradient method Descent method Hestenes, Stiefel 1952 For A N N SPD In exact arithmetic, solves in N steps In real arithmetic No guaranteed stopping Often converges in many fewer than N steps
Conjugate gradient method Descent method Hestenes, Stiefel 1952 For A N N SPD In exact arithmetic, solves in N steps In real arithmetic No guaranteed stopping Often converges in many fewer than N steps
AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 23: GMRES and Other Krylov Subspace Methods; Preconditioning
 Lecture 23: GMRES and Other Krylov Subspace Methods; Preconditioning") AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 23: GMRES and Other Krylov Subspace Methods; Preconditioning Xiangmin Jiao SUNY Stony Brook Xiangmin Jiao Numerical Analysis I 1 / 18 Outline
AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 23: GMRES and Other Krylov Subspace Methods; Preconditioning Xiangmin Jiao SUNY Stony Brook Xiangmin Jiao Numerical Analysis I 1 / 18 Outline
Chapter 7 Iterative Techniques in Matrix Algebra
 Chapter 7 Iterative Techniques in Matrix Algebra Per-Olof Persson persson@berkeley.edu Department of Mathematics University of California, Berkeley Math 128B Numerical Analysis Vector Norms Definition
Chapter 7 Iterative Techniques in Matrix Algebra Per-Olof Persson persson@berkeley.edu Department of Mathematics University of California, Berkeley Math 128B Numerical Analysis Vector Norms Definition
Iterative methods for Linear System of Equations. Joint Advanced Student School (JASS-2009)
") Iterative methods for Linear System of Equations Joint Advanced Student School (JASS-2009) Course #2: Numerical Simulation - from Models to Software Introduction In numerical simulation, Partial Differential
Iterative methods for Linear System of Equations Joint Advanced Student School (JASS-2009) Course #2: Numerical Simulation - from Models to Software Introduction In numerical simulation, Partial Differential
Notes on Some Methods for Solving Linear Systems
 Notes on Some Methods for Solving Linear Systems Dianne P. O Leary, 1983 and 1999 and 2007 September 25, 2007 When the matrix A is symmetric and positive definite, we have a whole new class of algorithms
Notes on Some Methods for Solving Linear Systems Dianne P. O Leary, 1983 and 1999 and 2007 September 25, 2007 When the matrix A is symmetric and positive definite, we have a whole new class of algorithms
Linear Solvers. Andrew Hazel
 Linear Solvers Andrew Hazel Introduction Thus far we have talked about the formulation and discretisation of physical problems...... and stopped when we got to a discrete linear system of equations. Introduction
Linear Solvers Andrew Hazel Introduction Thus far we have talked about the formulation and discretisation of physical problems...... and stopped when we got to a discrete linear system of equations. Introduction
EECS 275 Matrix Computation
 EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 20 1 / 20 Overview
EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 20 1 / 20 Overview
Conjugate Gradient algorithm. Storage: fixed, independent of number of steps.
 Conjugate Gradient algorithm Need: A symmetric positive definite; Cost: 1 matrix-vector product per step; Storage: fixed, independent of number of steps. The CG method minimizes the A norm of the error,
Conjugate Gradient algorithm Need: A symmetric positive definite; Cost: 1 matrix-vector product per step; Storage: fixed, independent of number of steps. The CG method minimizes the A norm of the error,
Algorithms that use the Arnoldi Basis
 AMSC 600 /CMSC 760 Advanced Linear Numerical Analysis Fall 2007 Arnoldi Methods Dianne P. O Leary c 2006, 2007 Algorithms that use the Arnoldi Basis Reference: Chapter 6 of Saad The Arnoldi Basis How to
AMSC 600 /CMSC 760 Advanced Linear Numerical Analysis Fall 2007 Arnoldi Methods Dianne P. O Leary c 2006, 2007 Algorithms that use the Arnoldi Basis Reference: Chapter 6 of Saad The Arnoldi Basis How to
A short course on: Preconditioned Krylov subspace methods. Yousef Saad University of Minnesota Dept. of Computer Science and Engineering
 A short course on: Preconditioned Krylov subspace methods Yousef Saad University of Minnesota Dept. of Computer Science and Engineering Universite du Littoral, Jan 19-3, 25 Outline Part 1 Introd., discretization
A short course on: Preconditioned Krylov subspace methods Yousef Saad University of Minnesota Dept. of Computer Science and Engineering Universite du Littoral, Jan 19-3, 25 Outline Part 1 Introd., discretization
The amount of work to construct each new guess from the previous one should be a small multiple of the number of nonzeros in A.
 AMSC/CMSC 661 Scientific Computing II Spring 2005 Solution of Sparse Linear Systems Part 2: Iterative methods Dianne P. O Leary c 2005 Solving Sparse Linear Systems: Iterative methods The plan: Iterative
AMSC/CMSC 661 Scientific Computing II Spring 2005 Solution of Sparse Linear Systems Part 2: Iterative methods Dianne P. O Leary c 2005 Solving Sparse Linear Systems: Iterative methods The plan: Iterative
Introduction to Iterative Solvers of Linear Systems
 Introduction to Iterative Solvers of Linear Systems SFB Training Event January 2012 Prof. Dr. Andreas Frommer Typeset by Lukas Krämer, Simon-Wolfgang Mages and Rudolf Rödl 1 Classes of Matrices and their
Introduction to Iterative Solvers of Linear Systems SFB Training Event January 2012 Prof. Dr. Andreas Frommer Typeset by Lukas Krämer, Simon-Wolfgang Mages and Rudolf Rödl 1 Classes of Matrices and their
PROJECTED GMRES AND ITS VARIANTS
 PROJECTED GMRES AND ITS VARIANTS Reinaldo Astudillo Brígida Molina rastudillo@kuaimare.ciens.ucv.ve bmolina@kuaimare.ciens.ucv.ve Centro de Cálculo Científico y Tecnológico (CCCT), Facultad de Ciencias,
PROJECTED GMRES AND ITS VARIANTS Reinaldo Astudillo Brígida Molina rastudillo@kuaimare.ciens.ucv.ve bmolina@kuaimare.ciens.ucv.ve Centro de Cálculo Científico y Tecnológico (CCCT), Facultad de Ciencias,
The Lanczos and conjugate gradient algorithms
 The Lanczos and conjugate gradient algorithms Gérard MEURANT October, 2008 1 The Lanczos algorithm 2 The Lanczos algorithm in finite precision 3 The nonsymmetric Lanczos algorithm 4 The Golub Kahan bidiagonalization
The Lanczos and conjugate gradient algorithms Gérard MEURANT October, 2008 1 The Lanczos algorithm 2 The Lanczos algorithm in finite precision 3 The nonsymmetric Lanczos algorithm 4 The Golub Kahan bidiagonalization
6.4 Krylov Subspaces and Conjugate Gradients
 6.4 Krylov Subspaces and Conjugate Gradients Our original equation is Ax = b. The preconditioned equation is P Ax = P b. When we write P, we never intend that an inverse will be explicitly computed. P
6.4 Krylov Subspaces and Conjugate Gradients Our original equation is Ax = b. The preconditioned equation is P Ax = P b. When we write P, we never intend that an inverse will be explicitly computed. P
Course Notes: Week 1
 Course Notes: Week 1 Math 270C: Applied Numerical Linear Algebra 1 Lecture 1: Introduction (3/28/11) We will focus on iterative methods for solving linear systems of equations (and some discussion of eigenvalues
Course Notes: Week 1 Math 270C: Applied Numerical Linear Algebra 1 Lecture 1: Introduction (3/28/11) We will focus on iterative methods for solving linear systems of equations (and some discussion of eigenvalues
Applied Mathematics 205. Unit V: Eigenvalue Problems. Lecturer: Dr. David Knezevic
 Applied Mathematics 205 Unit V: Eigenvalue Problems Lecturer: Dr. David Knezevic Unit V: Eigenvalue Problems Chapter V.4: Krylov Subspace Methods 2 / 51 Krylov Subspace Methods In this chapter we give
Applied Mathematics 205 Unit V: Eigenvalue Problems Lecturer: Dr. David Knezevic Unit V: Eigenvalue Problems Chapter V.4: Krylov Subspace Methods 2 / 51 Krylov Subspace Methods In this chapter we give
CME342 Parallel Methods in Numerical Analysis. Matrix Computation: Iterative Methods II. Sparse Matrix-vector Multiplication.
 CME342 Parallel Methods in Numerical Analysis Matrix Computation: Iterative Methods II Outline: CG & its parallelization. Sparse Matrix-vector Multiplication. 1 Basic iterative methods: Ax = b r = b Ax
CME342 Parallel Methods in Numerical Analysis Matrix Computation: Iterative Methods II Outline: CG & its parallelization. Sparse Matrix-vector Multiplication. 1 Basic iterative methods: Ax = b r = b Ax
The Conjugate Gradient Method
 The Conjugate Gradient Method The minimization problem We are given a symmetric positive definite matrix R n n and a right hand side vector b R n We want to solve the linear system Find u R n such that
The Conjugate Gradient Method The minimization problem We are given a symmetric positive definite matrix R n n and a right hand side vector b R n We want to solve the linear system Find u R n such that
Iterative Methods for Linear Systems of Equations
 Iterative Methods for Linear Systems of Equations Projection methods (3) ITMAN PhD-course DTU 20-10-08 till 24-10-08 Martin van Gijzen 1 Delft University of Technology Overview day 4 Bi-Lanczos method
Iterative Methods for Linear Systems of Equations Projection methods (3) ITMAN PhD-course DTU 20-10-08 till 24-10-08 Martin van Gijzen 1 Delft University of Technology Overview day 4 Bi-Lanczos method
Course Notes: Week 4
 Course Notes: Week 4 Math 270C: Applied Numerical Linear Algebra 1 Lecture 9: Steepest Descent (4/18/11) The connection with Lanczos iteration and the CG was not originally known. CG was originally derived
Course Notes: Week 4 Math 270C: Applied Numerical Linear Algebra 1 Lecture 9: Steepest Descent (4/18/11) The connection with Lanczos iteration and the CG was not originally known. CG was originally derived
Iterative Methods for Solving A x = b
 Iterative Methods for Solving A x = b A good (free) online source for iterative methods for solving A x = b is given in the description of a set of iterative solvers called templates found at netlib: http
Iterative Methods for Solving A x = b A good (free) online source for iterative methods for solving A x = b is given in the description of a set of iterative solvers called templates found at netlib: http
Simple iteration procedure
 Simple iteration procedure Solve Known approximate solution Preconditionning: Jacobi Gauss-Seidel Lower triangle residue use of pre-conditionner correction residue use of pre-conditionner Convergence Spectral
Simple iteration procedure Solve Known approximate solution Preconditionning: Jacobi Gauss-Seidel Lower triangle residue use of pre-conditionner correction residue use of pre-conditionner Convergence Spectral
The Conjugate Gradient Method
 The Conjugate Gradient Method Classical Iterations We have a problem, We assume that the matrix comes from a discretization of a PDE. The best and most popular model problem is, The matrix will be as large
The Conjugate Gradient Method Classical Iterations We have a problem, We assume that the matrix comes from a discretization of a PDE. The best and most popular model problem is, The matrix will be as large
Krylov Space Solvers
 Seminar for Applied Mathematics ETH Zurich International Symposium on Frontiers of Computational Science Nagoya, 12/13 Dec. 2005 Sparse Matrices Large sparse linear systems of equations or large sparse
Seminar for Applied Mathematics ETH Zurich International Symposium on Frontiers of Computational Science Nagoya, 12/13 Dec. 2005 Sparse Matrices Large sparse linear systems of equations or large sparse
Parallel Numerics, WT 2016/ Iterative Methods for Sparse Linear Systems of Equations. page 1 of 1
 Parallel Numerics, WT 2016/2017 5 Iterative Methods for Sparse Linear Systems of Equations page 1 of 1 Contents 1 Introduction 1.1 Computer Science Aspects 1.2 Numerical Problems 1.3 Graphs 1.4 Loop Manipulations
Parallel Numerics, WT 2016/2017 5 Iterative Methods for Sparse Linear Systems of Equations page 1 of 1 Contents 1 Introduction 1.1 Computer Science Aspects 1.2 Numerical Problems 1.3 Graphs 1.4 Loop Manipulations
1 Conjugate gradients
 Notes for 2016-11-18 1 Conjugate gradients We now turn to the method of conjugate gradients (CG), perhaps the best known of the Krylov subspace solvers. The CG iteration can be characterized as the iteration
Notes for 2016-11-18 1 Conjugate gradients We now turn to the method of conjugate gradients (CG), perhaps the best known of the Krylov subspace solvers. The CG iteration can be characterized as the iteration
Computational Linear Algebra
 Computational Linear Algebra PD Dr. rer. nat. habil. Ralf-Peter Mundani Computation in Engineering / BGU Scientific Computing in Computer Science / INF Winter Term 2018/19 Part 6: Some Other Stuff PD Dr.
Computational Linear Algebra PD Dr. rer. nat. habil. Ralf-Peter Mundani Computation in Engineering / BGU Scientific Computing in Computer Science / INF Winter Term 2018/19 Part 6: Some Other Stuff PD Dr.
SOLVING SPARSE LINEAR SYSTEMS OF EQUATIONS. Chao Yang Computational Research Division Lawrence Berkeley National Laboratory Berkeley, CA, USA
 1 SOLVING SPARSE LINEAR SYSTEMS OF EQUATIONS Chao Yang Computational Research Division Lawrence Berkeley National Laboratory Berkeley, CA, USA 2 OUTLINE Sparse matrix storage format Basic factorization
1 SOLVING SPARSE LINEAR SYSTEMS OF EQUATIONS Chao Yang Computational Research Division Lawrence Berkeley National Laboratory Berkeley, CA, USA 2 OUTLINE Sparse matrix storage format Basic factorization
AMS526: Numerical Analysis I (Numerical Linear Algebra)
") AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 21: Sensitivity of Eigenvalues and Eigenvectors; Conjugate Gradient Method Xiangmin Jiao Stony Brook University Xiangmin Jiao Numerical Analysis
AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 21: Sensitivity of Eigenvalues and Eigenvectors; Conjugate Gradient Method Xiangmin Jiao Stony Brook University Xiangmin Jiao Numerical Analysis
Krylov Subspace Methods that Are Based on the Minimization of the Residual
 Chapter 5 Krylov Subspace Methods that Are Based on the Minimization of the Residual Remark 51 Goal he goal of these methods consists in determining x k x 0 +K k r 0,A such that the corresponding Euclidean
Chapter 5 Krylov Subspace Methods that Are Based on the Minimization of the Residual Remark 51 Goal he goal of these methods consists in determining x k x 0 +K k r 0,A such that the corresponding Euclidean
Contents. Preface... xi. Introduction...
 Contents Preface... xi Introduction... xv Chapter 1. Computer Architectures... 1 1.1. Different types of parallelism... 1 1.1.1. Overlap, concurrency and parallelism... 1 1.1.2. Temporal and spatial parallelism
Contents Preface... xi Introduction... xv Chapter 1. Computer Architectures... 1 1.1. Different types of parallelism... 1 1.1.1. Overlap, concurrency and parallelism... 1 1.1.2. Temporal and spatial parallelism
ANY FINITE CONVERGENCE CURVE IS POSSIBLE IN THE INITIAL ITERATIONS OF RESTARTED FOM
 Electronic Transactions on Numerical Analysis. Volume 45, pp. 133 145, 2016. Copyright c 2016,. ISSN 1068 9613. ETNA ANY FINITE CONVERGENCE CURVE IS POSSIBLE IN THE INITIAL ITERATIONS OF RESTARTED FOM
Electronic Transactions on Numerical Analysis. Volume 45, pp. 133 145, 2016. Copyright c 2016,. ISSN 1068 9613. ETNA ANY FINITE CONVERGENCE CURVE IS POSSIBLE IN THE INITIAL ITERATIONS OF RESTARTED FOM
Lab 1: Iterative Methods for Solving Linear Systems
 Lab 1: Iterative Methods for Solving Linear Systems January 22, 2017 Introduction Many real world applications require the solution to very large and sparse linear systems where direct methods such as
Lab 1: Iterative Methods for Solving Linear Systems January 22, 2017 Introduction Many real world applications require the solution to very large and sparse linear systems where direct methods such as
Convex Optimization. Problem set 2. Due Monday April 26th
 Convex Optimization Problem set 2 Due Monday April 26th 1 Gradient Decent without Line-search In this problem we will consider gradient descent with predetermined step sizes. That is, instead of determining
Convex Optimization Problem set 2 Due Monday April 26th 1 Gradient Decent without Line-search In this problem we will consider gradient descent with predetermined step sizes. That is, instead of determining
IDR(s) as a projection method
 as a projection method") Delft University of Technology Faculty of Electrical Engineering, Mathematics and Computer Science Delft Institute of Applied Mathematics IDR(s) as a projection method A thesis submitted to the Delft Institute
Delft University of Technology Faculty of Electrical Engineering, Mathematics and Computer Science Delft Institute of Applied Mathematics IDR(s) as a projection method A thesis submitted to the Delft Institute
KRYLOV SUBSPACE ITERATION
 KRYLOV SUBSPACE ITERATION Presented by: Nab Raj Roshyara Master and Ph.D. Student Supervisors: Prof. Dr. Peter Benner, Department of Mathematics, TU Chemnitz and Dipl.-Geophys. Thomas Günther 1. Februar
KRYLOV SUBSPACE ITERATION Presented by: Nab Raj Roshyara Master and Ph.D. Student Supervisors: Prof. Dr. Peter Benner, Department of Mathematics, TU Chemnitz and Dipl.-Geophys. Thomas Günther 1. Februar
A DISSERTATION. Extensions of the Conjugate Residual Method. by Tomohiro Sogabe. Presented to
 A DISSERTATION Extensions of the Conjugate Residual Method ( ) by Tomohiro Sogabe Presented to Department of Applied Physics, The University of Tokyo Contents 1 Introduction 1 2 Krylov subspace methods
A DISSERTATION Extensions of the Conjugate Residual Method ( ) by Tomohiro Sogabe Presented to Department of Applied Physics, The University of Tokyo Contents 1 Introduction 1 2 Krylov subspace methods
MATH 20F: LINEAR ALGEBRA LECTURE B00 (T. KEMP)
") MATH 20F: LINEAR ALGEBRA LECTURE B00 (T KEMP) Definition 01 If T (x) = Ax is a linear transformation from R n to R m then Nul (T ) = {x R n : T (x) = 0} = Nul (A) Ran (T ) = {Ax R m : x R n } = {b R m
MATH 20F: LINEAR ALGEBRA LECTURE B00 (T KEMP) Definition 01 If T (x) = Ax is a linear transformation from R n to R m then Nul (T ) = {x R n : T (x) = 0} = Nul (A) Ran (T ) = {Ax R m : x R n } = {b R m
PETROV-GALERKIN METHODS
 Chapter 7 PETROV-GALERKIN METHODS 7.1 Energy Norm Minimization 7.2 Residual Norm Minimization 7.3 General Projection Methods 7.1 Energy Norm Minimization Saad, Sections 5.3.1, 5.2.1a. 7.1.1 Methods based
Chapter 7 PETROV-GALERKIN METHODS 7.1 Energy Norm Minimization 7.2 Residual Norm Minimization 7.3 General Projection Methods 7.1 Energy Norm Minimization Saad, Sections 5.3.1, 5.2.1a. 7.1.1 Methods based
4.6 Iterative Solvers for Linear Systems
 4.6 Iterative Solvers for Linear Systems Why use iterative methods? Virtually all direct methods for solving Ax = b require O(n 3 ) floating point operations. In practical applications the matrix A often
4.6 Iterative Solvers for Linear Systems Why use iterative methods? Virtually all direct methods for solving Ax = b require O(n 3 ) floating point operations. In practical applications the matrix A often
The Conjugate Gradient Method
 The Conjugate Gradient Method Jason E. Hicken Aerospace Design Lab Department of Aeronautics & Astronautics Stanford University 14 July 2011 Lecture Objectives describe when CG can be used to solve Ax
The Conjugate Gradient Method Jason E. Hicken Aerospace Design Lab Department of Aeronautics & Astronautics Stanford University 14 July 2011 Lecture Objectives describe when CG can be used to solve Ax
Solutions and Notes to Selected Problems In: Numerical Optimzation by Jorge Nocedal and Stephen J. Wright.
 Solutions and Notes to Selected Problems In: Numerical Optimzation by Jorge Nocedal and Stephen J. Wright. John L. Weatherwax July 7, 2010 wax@alum.mit.edu 1 Chapter 5 (Conjugate Gradient Methods) Notes
Solutions and Notes to Selected Problems In: Numerical Optimzation by Jorge Nocedal and Stephen J. Wright. John L. Weatherwax July 7, 2010 wax@alum.mit.edu 1 Chapter 5 (Conjugate Gradient Methods) Notes
ITERATIVE METHODS BASED ON KRYLOV SUBSPACES
 ITERATIVE METHODS BASED ON KRYLOV SUBSPACES LONG CHEN We shall present iterative methods for solving linear algebraic equation Au = b based on Krylov subspaces We derive conjugate gradient (CG) method
ITERATIVE METHODS BASED ON KRYLOV SUBSPACES LONG CHEN We shall present iterative methods for solving linear algebraic equation Au = b based on Krylov subspaces We derive conjugate gradient (CG) method
OUTLINE ffl CFD: elliptic pde's! Ax = b ffl Basic iterative methods ffl Krylov subspace methods ffl Preconditioning techniques: Iterative methods ILU
 Preconditioning Techniques for Solving Large Sparse Linear Systems Arnold Reusken Institut für Geometrie und Praktische Mathematik RWTH-Aachen OUTLINE ffl CFD: elliptic pde's! Ax = b ffl Basic iterative
Preconditioning Techniques for Solving Large Sparse Linear Systems Arnold Reusken Institut für Geometrie und Praktische Mathematik RWTH-Aachen OUTLINE ffl CFD: elliptic pde's! Ax = b ffl Basic iterative
Conjugate Gradient Method
 Conjugate Gradient Method Tsung-Ming Huang Department of Mathematics National Taiwan Normal University October 10, 2011 T.M. Huang (NTNU) Conjugate Gradient Method October 10, 2011 1 / 36 Outline 1 Steepest
Conjugate Gradient Method Tsung-Ming Huang Department of Mathematics National Taiwan Normal University October 10, 2011 T.M. Huang (NTNU) Conjugate Gradient Method October 10, 2011 1 / 36 Outline 1 Steepest
Contribution of Wo¹niakowski, Strako²,... The conjugate gradient method in nite precision computa
 Contribution of Wo¹niakowski, Strako²,... The conjugate gradient method in nite precision computations ªaw University of Technology Institute of Mathematics and Computer Science Warsaw, October 7, 2006
Contribution of Wo¹niakowski, Strako²,... The conjugate gradient method in nite precision computations ªaw University of Technology Institute of Mathematics and Computer Science Warsaw, October 7, 2006
Review of Linear Algebra
 Review of Linear Algebra Definitions An m n (read "m by n") matrix, is a rectangular array of entries, where m is the number of rows and n the number of columns. 2 Definitions (Con t) A is square if m=
Review of Linear Algebra Definitions An m n (read "m by n") matrix, is a rectangular array of entries, where m is the number of rows and n the number of columns. 2 Definitions (Con t) A is square if m=
Numerical Methods for Large-Scale Nonlinear Systems
 Numerical Methods for Large-Scale Nonlinear Systems Handouts by Ronald H.W. Hoppe following the monograph P. Deuflhard Newton Methods for Nonlinear Problems Springer, Berlin-Heidelberg-New York, 2004 Num.
Numerical Methods for Large-Scale Nonlinear Systems Handouts by Ronald H.W. Hoppe following the monograph P. Deuflhard Newton Methods for Nonlinear Problems Springer, Berlin-Heidelberg-New York, 2004 Num.
7.3 The Jacobi and Gauss-Siedel Iterative Techniques. Problem: To solve Ax = b for A R n n. Methodology: Iteratively approximate solution x. No GEPP.
 7.3 The Jacobi and Gauss-Siedel Iterative Techniques Problem: To solve Ax = b for A R n n. Methodology: Iteratively approximate solution x. No GEPP. 7.3 The Jacobi and Gauss-Siedel Iterative Techniques
7.3 The Jacobi and Gauss-Siedel Iterative Techniques Problem: To solve Ax = b for A R n n. Methodology: Iteratively approximate solution x. No GEPP. 7.3 The Jacobi and Gauss-Siedel Iterative Techniques
9.1 Preconditioned Krylov Subspace Methods
 Chapter 9 PRECONDITIONING 9.1 Preconditioned Krylov Subspace Methods 9.2 Preconditioned Conjugate Gradient 9.3 Preconditioned Generalized Minimal Residual 9.4 Relaxation Method Preconditioners 9.5 Incomplete
Chapter 9 PRECONDITIONING 9.1 Preconditioned Krylov Subspace Methods 9.2 Preconditioned Conjugate Gradient 9.3 Preconditioned Generalized Minimal Residual 9.4 Relaxation Method Preconditioners 9.5 Incomplete
Solving Sparse Linear Systems: Iterative methods
 Scientific Computing with Case Studies SIAM Press, 2009 http://www.cs.umd.edu/users/oleary/sccs Lecture Notes for Unit VII Sparse Matrix Computations Part 2: Iterative Methods Dianne P. O Leary c 2008,2010
Scientific Computing with Case Studies SIAM Press, 2009 http://www.cs.umd.edu/users/oleary/sccs Lecture Notes for Unit VII Sparse Matrix Computations Part 2: Iterative Methods Dianne P. O Leary c 2008,2010
Solving Sparse Linear Systems: Iterative methods
 Scientific Computing with Case Studies SIAM Press, 2009 http://www.cs.umd.edu/users/oleary/sccswebpage Lecture Notes for Unit VII Sparse Matrix Computations Part 2: Iterative Methods Dianne P. O Leary
Scientific Computing with Case Studies SIAM Press, 2009 http://www.cs.umd.edu/users/oleary/sccswebpage Lecture Notes for Unit VII Sparse Matrix Computations Part 2: Iterative Methods Dianne P. O Leary
Iterative Methods and Multigrid
 Iterative Methods and Multigrid Part 3: Preconditioning 2 Eric de Sturler Preconditioning The general idea behind preconditioning is that convergence of some method for the linear system Ax = b can be
Iterative Methods and Multigrid Part 3: Preconditioning 2 Eric de Sturler Preconditioning The general idea behind preconditioning is that convergence of some method for the linear system Ax = b can be
The Conjugate Gradient Method for Solving Linear Systems of Equations
 The Conjugate Gradient Method for Solving Linear Systems of Equations Mike Rambo Mentor: Hans de Moor May 2016 Department of Mathematics, Saint Mary s College of California Contents 1 Introduction 2 2
The Conjugate Gradient Method for Solving Linear Systems of Equations Mike Rambo Mentor: Hans de Moor May 2016 Department of Mathematics, Saint Mary s College of California Contents 1 Introduction 2 2
Linear Algebra Massoud Malek
 CSUEB Linear Algebra Massoud Malek Inner Product and Normed Space In all that follows, the n n identity matrix is denoted by I n, the n n zero matrix by Z n, and the zero vector by θ n An inner product
CSUEB Linear Algebra Massoud Malek Inner Product and Normed Space In all that follows, the n n identity matrix is denoted by I n, the n n zero matrix by Z n, and the zero vector by θ n An inner product
Numerical Methods I Non-Square and Sparse Linear Systems
 Numerical Methods I Non-Square and Sparse Linear Systems Aleksandar Donev Courant Institute, NYU 1 donev@courant.nyu.edu 1 MATH-GA 2011.003 / CSCI-GA 2945.003, Fall 2014 September 25th, 2014 A. Donev (Courant
Numerical Methods I Non-Square and Sparse Linear Systems Aleksandar Donev Courant Institute, NYU 1 donev@courant.nyu.edu 1 MATH-GA 2011.003 / CSCI-GA 2945.003, Fall 2014 September 25th, 2014 A. Donev (Courant
Conjugate Gradient (CG) Method
 Method") Conjugate Gradient (CG) Method by K. Ozawa 1 Introduction In the series of this lecture, I will introduce the conjugate gradient method, which solves efficiently large scale sparse linear simultaneous
Conjugate Gradient (CG) Method by K. Ozawa 1 Introduction In the series of this lecture, I will introduce the conjugate gradient method, which solves efficiently large scale sparse linear simultaneous
Iterative Methods for Sparse Linear Systems
 Iterative Methods for Sparse Linear Systems Luca Bergamaschi e-mail: berga@dmsa.unipd.it - http://www.dmsa.unipd.it/ berga Department of Mathematical Methods and Models for Scientific Applications University
Iterative Methods for Sparse Linear Systems Luca Bergamaschi e-mail: berga@dmsa.unipd.it - http://www.dmsa.unipd.it/ berga Department of Mathematical Methods and Models for Scientific Applications University
RESIDUAL SMOOTHING AND PEAK/PLATEAU BEHAVIOR IN KRYLOV SUBSPACE METHODS
 RESIDUAL SMOOTHING AND PEAK/PLATEAU BEHAVIOR IN KRYLOV SUBSPACE METHODS HOMER F. WALKER Abstract. Recent results on residual smoothing are reviewed, and it is observed that certain of these are equivalent
RESIDUAL SMOOTHING AND PEAK/PLATEAU BEHAVIOR IN KRYLOV SUBSPACE METHODS HOMER F. WALKER Abstract. Recent results on residual smoothing are reviewed, and it is observed that certain of these are equivalent
Stabilization and Acceleration of Algebraic Multigrid Method
 Stabilization and Acceleration of Algebraic Multigrid Method Recursive Projection Algorithm A. Jemcov J.P. Maruszewski Fluent Inc. October 24, 2006 Outline 1 Need for Algorithm Stabilization and Acceleration
Stabilization and Acceleration of Algebraic Multigrid Method Recursive Projection Algorithm A. Jemcov J.P. Maruszewski Fluent Inc. October 24, 2006 Outline 1 Need for Algorithm Stabilization and Acceleration
MATH Linear Algebra
 MATH 304 - Linear Algebra In the previous note we learned an important algorithm to produce orthogonal sequences of vectors called the Gramm-Schmidt orthogonalization process. Gramm-Schmidt orthogonalization
MATH 304 - Linear Algebra In the previous note we learned an important algorithm to produce orthogonal sequences of vectors called the Gramm-Schmidt orthogonalization process. Gramm-Schmidt orthogonalization
Eigenvalue Problems CHAPTER 1 : PRELIMINARIES
 Eigenvalue Problems CHAPTER 1 : PRELIMINARIES Heinrich Voss voss@tu-harburg.de Hamburg University of Technology Institute of Mathematics TUHH Heinrich Voss Preliminaries Eigenvalue problems 2012 1 / 14
Eigenvalue Problems CHAPTER 1 : PRELIMINARIES Heinrich Voss voss@tu-harburg.de Hamburg University of Technology Institute of Mathematics TUHH Heinrich Voss Preliminaries Eigenvalue problems 2012 1 / 14
IDR(s) Master s thesis Goushani Kisoensingh. Supervisor: Gerard L.G. Sleijpen Department of Mathematics Universiteit Utrecht
 Master s thesis Goushani Kisoensingh. Supervisor: Gerard L.G. Sleijpen Department of Mathematics Universiteit Utrecht") IDR(s) Master s thesis Goushani Kisoensingh Supervisor: Gerard L.G. Sleijpen Department of Mathematics Universiteit Utrecht Contents 1 Introduction 2 2 The background of Bi-CGSTAB 3 3 IDR(s) 4 3.1 IDR.............................................
IDR(s) Master s thesis Goushani Kisoensingh Supervisor: Gerard L.G. Sleijpen Department of Mathematics Universiteit Utrecht Contents 1 Introduction 2 2 The background of Bi-CGSTAB 3 3 IDR(s) 4 3.1 IDR.............................................
Krylov Space Methods. Nonstationary sounds good. Radu Trîmbiţaş ( Babeş-Bolyai University) Krylov Space Methods 1 / 17
 Krylov Space Methods 1 / 17") Krylov Space Methods Nonstationary sounds good Radu Trîmbiţaş Babeş-Bolyai University Radu Trîmbiţaş ( Babeş-Bolyai University) Krylov Space Methods 1 / 17 Introduction These methods are used both to solve
Krylov Space Methods Nonstationary sounds good Radu Trîmbiţaş Babeş-Bolyai University Radu Trîmbiţaş ( Babeş-Bolyai University) Krylov Space Methods 1 / 17 Introduction These methods are used both to solve
Efficient Estimation of the A-norm of the Error in the Preconditioned Conjugate Gradient Method
 Efficient Estimation of the A-norm of the Error in the Preconditioned Conjugate Gradient Method Zdeněk Strakoš and Petr Tichý Institute of Computer Science AS CR, Technical University of Berlin. International
Efficient Estimation of the A-norm of the Error in the Preconditioned Conjugate Gradient Method Zdeněk Strakoš and Petr Tichý Institute of Computer Science AS CR, Technical University of Berlin. International
ON ORTHOGONAL REDUCTION TO HESSENBERG FORM WITH SMALL BANDWIDTH
 ON ORTHOGONAL REDUCTION TO HESSENBERG FORM WITH SMALL BANDWIDTH V. FABER, J. LIESEN, AND P. TICHÝ Abstract. Numerous algorithms in numerical linear algebra are based on the reduction of a given matrix
ON ORTHOGONAL REDUCTION TO HESSENBERG FORM WITH SMALL BANDWIDTH V. FABER, J. LIESEN, AND P. TICHÝ Abstract. Numerous algorithms in numerical linear algebra are based on the reduction of a given matrix
The quadratic eigenvalue problem (QEP) is to find scalars λ and nonzero vectors u satisfying
 is to find scalars λ and nonzero vectors u satisfying") I.2 Quadratic Eigenvalue Problems 1 Introduction The quadratic eigenvalue problem QEP is to find scalars λ and nonzero vectors u satisfying where Qλx = 0, 1.1 Qλ = λ 2 M + λd + K, M, D and K are given
I.2 Quadratic Eigenvalue Problems 1 Introduction The quadratic eigenvalue problem QEP is to find scalars λ and nonzero vectors u satisfying where Qλx = 0, 1.1 Qλ = λ 2 M + λd + K, M, D and K are given
Lecture 11: CMSC 878R/AMSC698R. Iterative Methods An introduction. Outline. Inverse, LU decomposition, Cholesky, SVD, etc.
 Lecture 11: CMSC 878R/AMSC698R Iterative Methods An introduction Outline Direct Solution of Linear Systems Inverse, LU decomposition, Cholesky, SVD, etc. Iterative methods for linear systems Why? Matrix
Lecture 11: CMSC 878R/AMSC698R Iterative Methods An introduction Outline Direct Solution of Linear Systems Inverse, LU decomposition, Cholesky, SVD, etc. Iterative methods for linear systems Why? Matrix
Algebra C Numerical Linear Algebra Sample Exam Problems
 Algebra C Numerical Linear Algebra Sample Exam Problems Notation. Denote by V a finite-dimensional Hilbert space with inner product (, ) and corresponding norm. The abbreviation SPD is used for symmetric
Algebra C Numerical Linear Algebra Sample Exam Problems Notation. Denote by V a finite-dimensional Hilbert space with inner product (, ) and corresponding norm. The abbreviation SPD is used for symmetric
Some minimization problems
 Week 13: Wednesday, Nov 14 Some minimization problems Last time, we sketched the following two-step strategy for approximating the solution to linear systems via Krylov subspaces: 1. Build a sequence of
Week 13: Wednesday, Nov 14 Some minimization problems Last time, we sketched the following two-step strategy for approximating the solution to linear systems via Krylov subspaces: 1. Build a sequence of
Efficient Estimation of the A-norm of the Error in the Preconditioned Conjugate Gradient Method
 Efficient Estimation of the A-norm of the Error in the Preconditioned Conjugate Gradient Method Zdeněk Strakoš and Petr Tichý Institute of Computer Science AS CR, Technical University of Berlin. Emory
Efficient Estimation of the A-norm of the Error in the Preconditioned Conjugate Gradient Method Zdeněk Strakoš and Petr Tichý Institute of Computer Science AS CR, Technical University of Berlin. Emory
Definition 1. A set V is a vector space over the scalar field F {R, C} iff. there are two operations defined on V, called vector addition
 6 Vector Spaces with Inned Product Basis and Dimension Section Objective(s): Vector Spaces and Subspaces Linear (In)dependence Basis and Dimension Inner Product 6 Vector Spaces and Subspaces Definition
6 Vector Spaces with Inned Product Basis and Dimension Section Objective(s): Vector Spaces and Subspaces Linear (In)dependence Basis and Dimension Inner Product 6 Vector Spaces and Subspaces Definition
GMRES: Generalized Minimal Residual Algorithm for Solving Nonsymmetric Linear Systems
 GMRES: Generalized Minimal Residual Algorithm for Solving Nonsymmetric Linear Systems Tsung-Ming Huang Department of Mathematics National Taiwan Normal University December 4, 2011 T.-M. Huang (NTNU) GMRES
GMRES: Generalized Minimal Residual Algorithm for Solving Nonsymmetric Linear Systems Tsung-Ming Huang Department of Mathematics National Taiwan Normal University December 4, 2011 T.-M. Huang (NTNU) GMRES
Conjugate Gradient Tutorial
 Conjugate Gradient Tutorial Prof. Chung-Kuan Cheng Computer Science and Engineering Department University of California, San Diego ckcheng@ucsd.edu December 1, 2015 Prof. Chung-Kuan Cheng (UC San Diego)
Conjugate Gradient Tutorial Prof. Chung-Kuan Cheng Computer Science and Engineering Department University of California, San Diego ckcheng@ucsd.edu December 1, 2015 Prof. Chung-Kuan Cheng (UC San Diego)
7.2 Steepest Descent and Preconditioning
 7.2 Steepest Descent and Preconditioning Descent methods are a broad class of iterative methods for finding solutions of the linear system Ax = b for symmetric positive definite matrix A R n n. Consider
7.2 Steepest Descent and Preconditioning Descent methods are a broad class of iterative methods for finding solutions of the linear system Ax = b for symmetric positive definite matrix A R n n. Consider
DS-GA 1002 Lecture notes 0 Fall Linear Algebra. These notes provide a review of basic concepts in linear algebra.
 DS-GA 1002 Lecture notes 0 Fall 2016 Linear Algebra These notes provide a review of basic concepts in linear algebra. 1 Vector spaces You are no doubt familiar with vectors in R 2 or R 3, i.e. [ ] 1.1
DS-GA 1002 Lecture notes 0 Fall 2016 Linear Algebra These notes provide a review of basic concepts in linear algebra. 1 Vector spaces You are no doubt familiar with vectors in R 2 or R 3, i.e. [ ] 1.1
Research Article Some Generalizations and Modifications of Iterative Methods for Solving Large Sparse Symmetric Indefinite Linear Systems
 Abstract and Applied Analysis Article ID 237808 pages http://dxdoiorg/055/204/237808 Research Article Some Generalizations and Modifications of Iterative Methods for Solving Large Sparse Symmetric Indefinite
Abstract and Applied Analysis Article ID 237808 pages http://dxdoiorg/055/204/237808 Research Article Some Generalizations and Modifications of Iterative Methods for Solving Large Sparse Symmetric Indefinite
AMSC 600 /CMSC 760 Advanced Linear Numerical Analysis Fall 2007 Krylov Minimization and Projection (KMP) Dianne P. O Leary c 2006, 2007.
 Dianne P. O Leary c 2006, 2007.") AMSC 600 /CMSC 760 Advanced Linear Numerical Analysis Fall 2007 Krylov Minimization and Projection (KMP) Dianne P. O Leary c 2006, 2007 This unit: So far: A survey of iterative methods for solving linear
AMSC 600 /CMSC 760 Advanced Linear Numerical Analysis Fall 2007 Krylov Minimization and Projection (KMP) Dianne P. O Leary c 2006, 2007 This unit: So far: A survey of iterative methods for solving linear
Linear Algebra Review. Vectors
 Linear Algebra Review 9/4/7 Linear Algebra Review By Tim K. Marks UCSD Borrows heavily from: Jana Kosecka http://cs.gmu.edu/~kosecka/cs682.html Virginia de Sa (UCSD) Cogsci 8F Linear Algebra review Vectors
Linear Algebra Review 9/4/7 Linear Algebra Review By Tim K. Marks UCSD Borrows heavily from: Jana Kosecka http://cs.gmu.edu/~kosecka/cs682.html Virginia de Sa (UCSD) Cogsci 8F Linear Algebra review Vectors
MATH 23a, FALL 2002 THEORETICAL LINEAR ALGEBRA AND MULTIVARIABLE CALCULUS Solutions to Final Exam (in-class portion) January 22, 2003
 January 22, 2003") MATH 23a, FALL 2002 THEORETICAL LINEAR ALGEBRA AND MULTIVARIABLE CALCULUS Solutions to Final Exam (in-class portion) January 22, 2003 1. True or False (28 points, 2 each) T or F If V is a vector space
MATH 23a, FALL 2002 THEORETICAL LINEAR ALGEBRA AND MULTIVARIABLE CALCULUS Solutions to Final Exam (in-class portion) January 22, 2003 1. True or False (28 points, 2 each) T or F If V is a vector space
Chapter 7. Iterative methods for large sparse linear systems. 7.1 Sparse matrix algebra. Large sparse matrices
 Chapter 7 Iterative methods for large sparse linear systems In this chapter we revisit the problem of solving linear systems of equations, but now in the context of large sparse systems. The price to pay
Chapter 7 Iterative methods for large sparse linear systems In this chapter we revisit the problem of solving linear systems of equations, but now in the context of large sparse systems. The price to pay
Preliminary/Qualifying Exam in Numerical Analysis (Math 502a) Spring 2012
 Spring 2012") Instructions Preliminary/Qualifying Exam in Numerical Analysis (Math 502a) Spring 2012 The exam consists of four problems, each having multiple parts. You should attempt to solve all four problems. 1.
Instructions Preliminary/Qualifying Exam in Numerical Analysis (Math 502a) Spring 2012 The exam consists of four problems, each having multiple parts. You should attempt to solve all four problems. 1.
The Conjugate Gradient Algorithm
 Optimization over a Subspace Conjugate Direction Methods Conjugate Gradient Algorithm Non-Quadratic Conjugate Gradient Algorithm Optimization over a Subspace Consider the problem min f (x) subject to x
Optimization over a Subspace Conjugate Direction Methods Conjugate Gradient Algorithm Non-Quadratic Conjugate Gradient Algorithm Optimization over a Subspace Consider the problem min f (x) subject to x
Iterative methods for positive definite linear systems with a complex shift
 Iterative methods for positive definite linear systems with a complex shift William McLean, University of New South Wales Vidar Thomée, Chalmers University November 4, 2011 Outline 1. Numerical solution
Iterative methods for positive definite linear systems with a complex shift William McLean, University of New South Wales Vidar Thomée, Chalmers University November 4, 2011 Outline 1. Numerical solution
Introduction to Scientific Computing
 (Lecture 5: Linear system of equations / Matrix Splitting) Bojana Rosić, Thilo Moshagen Institute of Scientific Computing Motivation Let us resolve the problem scheme by using Kirchhoff s laws: the algebraic
(Lecture 5: Linear system of equations / Matrix Splitting) Bojana Rosić, Thilo Moshagen Institute of Scientific Computing Motivation Let us resolve the problem scheme by using Kirchhoff s laws: the algebraic
Math Linear Algebra II. 1. Inner Products and Norms
 Math 342 - Linear Algebra II Notes 1. Inner Products and Norms One knows from a basic introduction to vectors in R n Math 254 at OSU) that the length of a vector x = x 1 x 2... x n ) T R n, denoted x,
Math 342 - Linear Algebra II Notes 1. Inner Products and Norms One knows from a basic introduction to vectors in R n Math 254 at OSU) that the length of a vector x = x 1 x 2... x n ) T R n, denoted x,
On the influence of eigenvalues on Bi-CG residual norms
 On the influence of eigenvalues on Bi-CG residual norms Jurjen Duintjer Tebbens Institute of Computer Science Academy of Sciences of the Czech Republic duintjertebbens@cs.cas.cz Gérard Meurant 30, rue
On the influence of eigenvalues on Bi-CG residual norms Jurjen Duintjer Tebbens Institute of Computer Science Academy of Sciences of the Czech Republic duintjertebbens@cs.cas.cz Gérard Meurant 30, rue