PROBABILISTIC REASONING OVER TIME
|
|
|
- Giles Gaines
- 5 years ago
- Views:
Transcription
1 PROBABILISTIC REASONING OVER TIME In which we try to interpret the present, understand the past, and perhaps predict the future, even when very little is crystal clear.
2 Outline Time and uncertainty Inference: filtering, prediction, smoothing Hidden Markov models Kalman filters (a brief mention) Dynamic Bayesian networks Particle filtering Chapter 15, Sections 1 5 2
3 Time and uncertainty The world changes; we need to track and predict it Diabetes management vs vehicle diagnosis Basic idea: copy state and evidence variables for each time step X t =setofunobservablestatevariablesattimet e.g., BloodSugar t, StomachContents t,etc. E t =setofobservableevidencevariablesattimet e.g., MeasuredBloodSugar t, PulseRate t, FoodEaten t This assumes discrete time; step size depends on problem Notation: X a:b = X a, X a+1,...,x b 1, X b Chapter 15, Sections 1 5 3
4
5 Markov processes (Markov chains) Construct a Bayes net from these variables: parents? Markov assumption: X t depends on bounded subset of X 0:t 1 First-order Markov process: P(X t X 0:t 1 )=P(X t X t 1 ) Second-order Markov process: P(X t X 0:t 1 )=P(X t X t 2, X t 1 ) First order X t 2 X t 1 X t X t +1 X t +2 Second order X t 2 X t 1 X t X t +1 X t +2 Sensor Markov assumption: P(E t X 0:t, E 0:t 1 )=P(E t X t ) Stationary process: transition model P(X t X t 1 ) and sensor model P(E t X t ) fixed for all t Chapter 15, Sections 1 5 4
6 Example Rain t 1 R t 1 t f P(R t ) Rain t Rain t +1 Rt t f P(U t ) Umbrella t 1 Umbrella t Umbrella t +1 First-order Markov assumption not exactly true in real world! Possible fixes: 1. Increase order of Markov process 2. Augment state, e.g.,addt emp t, Pressure t Example: robot motion. Augment position and velocity with Battery t Chapter 15, Sections 1 5 5
7
8
9 Inference tasks Filtering: P(X t e 1:t ) belief state input to the decision process of a rational agent Prediction: P(X t+k e 1:t ) for k>0 evaluation of possible action sequences; like filtering without the evidence Smoothing: P(X k e 1:t ) for 0 k<t better estimate of past states, essential for learning Most likely explanation: arg max x1:t P (x 1:t e 1:t ) speech recognition, decoding with a noisy channel Chapter 15, Sections 1 5 6
10 Filtering Aim: devise a recursive state estimation algorithm: P(X t+1 e 1:t+1 )=f(e t+1, P(X t e 1:t )) P(X t+1 e 1:t+1 )=P(X t+1 e 1:t, e t+1 ) = αp(e t+1 X t+1, e 1:t )P(X t+1 e 1:t ) = αp(e t+1 X t+1 )P(X t+1 e 1:t ) I.e.,prediction + estimation. PredictionbysummingoutX t : P(X t+1 e 1:t+1 )=αp(e t+1 X t+1 )Σ xt P(X t+1 x t, e 1:t )P (x t e 1:t ) = αp(e t+1 X t+1 )Σ xt P(X t+1 x t )P (x t e 1:t ) f 1:t+1 = Forward(f 1:t, e t+1 ) where f 1:t = P(X t e 1:t ) Time and space constant (independent of t) Chapter 15, Sections 1 5 7
11 Filtering example True False Rain 0 Rain 1 Rain 2 Umbrella 1 Umbrella 2 Chapter 15, Sections 1 5 8
12 Filtering example True False Rain 0 Rain 1 Rain 2 Umbrella 1 Umbrella 2 Chapter 15, Sections 1 5 8
13 Filtering example True False Rain 0 Rain 1 Rain 2 Umbrella 1 Umbrella 2 Chapter 15, Sections 1 5 8
14
15 Smoothing example True False forward smoothed backward Rain 0 Rain 1 Rain 2 Umbrella 1 Umbrella 2 Forward backward algorithm: cache forward messages along the way Time linear in t (polytree inference), space O(t f ) Chapter 15, Sections
16 Smoothing example True False forward smoothed backward Rain 0 Rain 1 Rain 2 Umbrella 1 Umbrella 2 Forward backward algorithm: cache forward messages along the way Time linear in t (polytree inference), space O(t f ) Chapter 15, Sections
17 Most likely explanation Most likely sequence sequence of most likely states!!!! Most likely path to each x t+1 =mostlikelypathtosome x t plus one more step max P(x x 1...x 1,...,x t, X t+1 e 1:t+1 ) t = P(e t+1 X t+1 )max P(Xt+1 x x t ) max P (x t x 1...x 1,...,x t 1, x t e 1:t ) t 1 Identical to filtering, except f 1:t replaced by m 1:t = max P(x x 1...x 1,...,x t 1, X t e 1:t ), t 1 I.e., m 1:t (i) gives the probability of the most likely path to state i. Update has sum replaced by max, giving the Viterbi algorithm: m 1:t+1 = P(e t+1 X t+1 )max x t (P(X t+1 x t )m 1:t ) Chapter 15, Sections
18 Viterbi example Rain 1 Rain 2 Rain 3 Rain 4 Rain 5 state space paths true false true false true false true false true false umbrella true true false true true most likely paths m 1:1 m 1:2 m 1:3 m 1:4 m 1:5 Chapter 15, Sections
19
20 Hidden Markov models X t is a single, discrete variable (usually E t is too) Domain of X t is {1,...,S} Transition matrix T ij = P (X t = j X t 1 = i), e.g., Sensor matrix O t for each time step, diagonal elements P (e t X t = i) e.g., with U 1 = true, O 1 = Forward and backward messages as column vectors: f 1:t+1 = αo t+1 T f 1:t b k+1:t = TO k+1 b k+2:t Forward-backward algorithm needs time O(S 2 t) and space O(St) Chapter 15, Sections
21 Hidden Markov models X t is a single, discrete variable (usually E t is too) Domain of X t is {1,...,S} Transition matrix T ij = P (X t = j X t 1 = i), e.g., Sensor matrix O t for each time step, diagonal elements P (e t X t = i) e.g., with U 1 = true, O 1 = Forward and backward messages as column vectors: f 1:t+1 = αo t+1 T f 1:t b k+1:t = TO k+1 b k+2:t Forward-backward algorithm needs time O(S 2 t) and space O(St) Chapter 15, Sections
22 Hidden Markov models X t is a single, discrete variable (usually E t is too) Domain of X t is {1,...,S} Transition matrix T ij = P (X t = j X t 1 = i), e.g., Sensor matrix O t for each time step, diagonal elements P (e t X t = i) e.g., with U 1 = true, O 1 = Forward and backward messages as column vectors: f 1:t+1 = αo t+1 T f 1:t b k+1:t = TO k+1 b k+2:t Forward-backward algorithm needs time O(S 2 t) and space O(St) Chapter 15, Sections
23
24 Country dance algorithm Can avoid storing all forward messages in smoothing by running forward algorithm backwards: f 1:t+1 = αo t+1 T f 1:t O 1 t+1f 1:t+1 = αt f 1:t α (T ) 1 O 1 t+1f 1:t+1 = f 1:t Algorithm: forward pass computes f t,backwardpassdoesf i, b i Chapter 15, Sections
25 Country dance algorithm Can avoid storing all forward messages in smoothing by running forward algorithm backwards: f 1:t+1 = αo t+1 T f 1:t O 1 t+1f 1:t+1 = αt f 1:t α (T ) 1 O 1 t+1f 1:t+1 = f 1:t Algorithm: forward pass computes f t,backwardpassdoesf i, b i Chapter 15, Sections
26 Country dance algorithm Can avoid storing all forward messages in smoothing by running forward algorithm backwards: f 1:t+1 = αo t+1 T f 1:t O 1 t+1f 1:t+1 = αt f 1:t α (T ) 1 O 1 t+1f 1:t+1 = f 1:t Algorithm: forward pass computes f t,backwardpassdoesf i, b i Chapter 15, Sections
27 Country dance algorithm Can avoid storing all forward messages in smoothing by running forward algorithm backwards: f 1:t+1 = αo t+1 T f 1:t O 1 t+1f 1:t+1 = αt f 1:t α (T ) 1 O 1 t+1f 1:t+1 = f 1:t Algorithm: forward pass computes f t,backwardpassdoesf i, b i Chapter 15, Sections
28 Country dance algorithm Can avoid storing all forward messages in smoothing by running forward algorithm backwards: f 1:t+1 = αo t+1 T f 1:t O 1 t+1f 1:t+1 = αt f 1:t α (T ) 1 O 1 t+1f 1:t+1 = f 1:t Algorithm: forward pass computes f t,backwardpassdoesf i, b i Chapter 15, Sections
29 Country dance algorithm Can avoid storing all forward messages in smoothing by running forward algorithm backwards: f 1:t+1 = αo t+1 T f 1:t O 1 t+1f 1:t+1 = αt f 1:t α (T ) 1 O 1 t+1f 1:t+1 = f 1:t Algorithm: forward pass computes f t,backwardpassdoesf i, b i Chapter 15, Sections
30 Country dance algorithm Can avoid storing all forward messages in smoothing by running forward algorithm backwards: f 1:t+1 = αo t+1 T f 1:t O 1 t+1f 1:t+1 = αt f 1:t α (T ) 1 O 1 t+1f 1:t+1 = f 1:t Algorithm: forward pass computes f t,backwardpassdoesf i, b i Chapter 15, Sections
31 Country dance algorithm Can avoid storing all forward messages in smoothing by running forward algorithm backwards: f 1:t+1 = αo t+1 T f 1:t O 1 t+1f 1:t+1 = αt f 1:t α (T ) 1 O 1 t+1f 1:t+1 = f 1:t Algorithm: forward pass computes f t,backwardpassdoesf i, b i Chapter 15, Sections
32 Country dance algorithm Can avoid storing all forward messages in smoothing by running forward algorithm backwards: f 1:t+1 = αo t+1 T f 1:t O 1 t+1f 1:t+1 = αt f 1:t α (T ) 1 O 1 t+1f 1:t+1 = f 1:t Algorithm: forward pass computes f t,backwardpassdoesf i, b i Chapter 15, Sections
33 Country dance algorithm Can avoid storing all forward messages in smoothing by running forward algorithm backwards: f 1:t+1 = αo t+1 T f 1:t O 1 t+1f 1:t+1 = αt f 1:t α (T ) 1 O 1 t+1f 1:t+1 = f 1:t Algorithm: forward pass computes f t,backwardpassdoesf i, b i Chapter 15, Sections
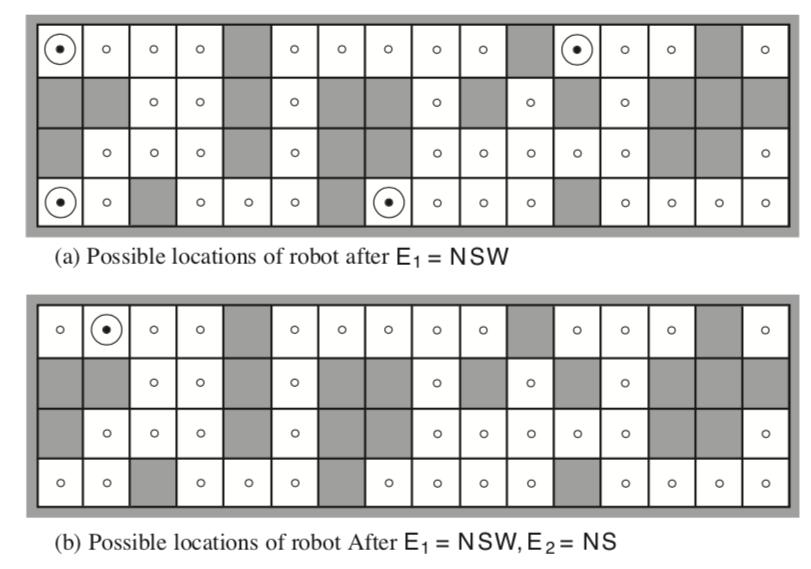
34
35
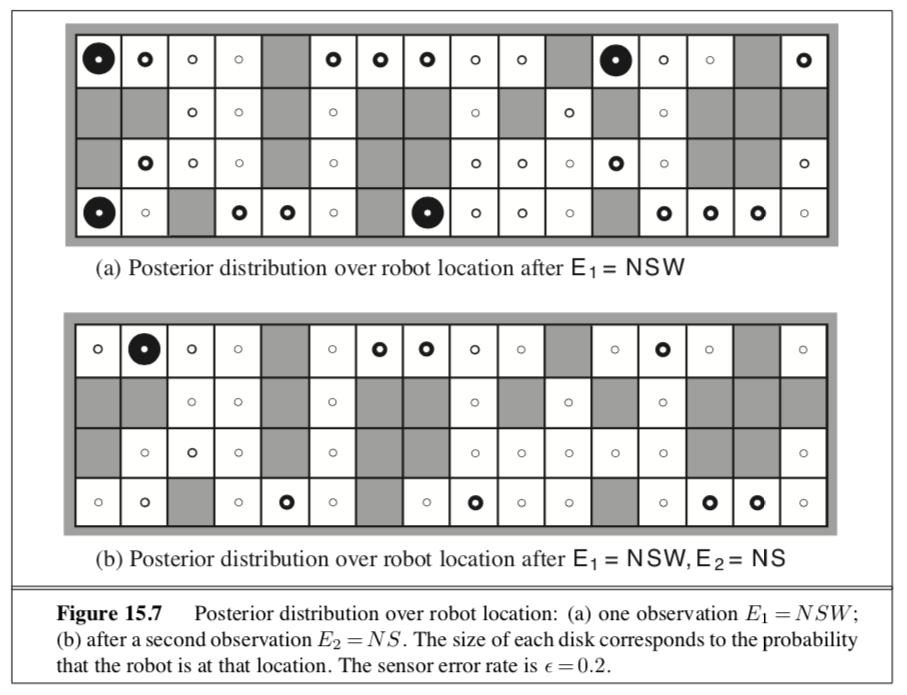
36
37
38 Kalman filters Modelling systems described by a set of continuous variables, e.g., tracking a bird flying X t = X, Y, Z, Ẋ,Ẏ,Ż. Airplanes, robots, ecosystems, economies, chemical plants, planets,... Xt Xt+1 Xt Xt+1 Zt Zt+1 Gaussian prior, linear Gaussian transition model and sensor model Chapter 15, Sections
39 Updating Gaussian distributions Prediction step: if P(X t e 1:t ) is Gaussian, then prediction P(X t+1 e 1:t )= x t P(X t+1 x t )P (x t e 1:t ) dx t is Gaussian. If P(X t+1 e 1:t ) is Gaussian, then the updated distribution P(X t+1 e 1:t+1 )=αp(e t+1 X t+1 )P(X t+1 e 1:t ) is Gaussian Hence P(X t e 1:t ) is multivariate Gaussian N(µ t, Σ t ) for all t General (nonlinear, non-gaussian) process: description of posterior grows unboundedly as t Chapter 15, Sections
40 Simple 1-D example Gaussian random walk on X axis, s.d. σ x,sensors.d.σ z µ t+1 = (σ2 t + σ 2 x)z t+1 + σ 2 zµ t σ 2 t + σ 2 x + σ 2 z σ 2 t+1 = (σ2 t + σ 2 x)σ 2 z σ 2 t + σ 2 x + σ 2 z P(X) P(x1 z1=2.5) 0.25 P(x0) P(x1) *z X position Chapter 15, Sections
41 Transition and sensor models: General Kalman update P (x t+1 x t )=N(Fx t, Σ x )(x t+1 ) P (z t x t )=N(Hx t, Σ z )(z t ) F is the matrix for the transition; Σ x the transition noise covariance H is the matrix for the sensors; Σ z the sensor noise covariance Filter computes the following update: µ t+1 = Fµ t + K t+1 (z t+1 HFµ t ) Σ t+1 =(I K t+1 )(FΣ t F + Σ x ) where K t+1 =(FΣ t F + Σ x )H (H(FΣ t F + Σ x )H + Σ z ) 1 is the Kalman gain matrix Σ t and K t are independent of observation sequence, so compute offline Chapter 15, Sections
42 2-D tracking example: filtering 12 2D filtering 11 true observed filtered 10 Y X Chapter 15, Sections
43 2-D tracking example: smoothing 12 2D smoothing 11 true observed smoothed 10 Y X Chapter 15, Sections
44 Where it breaks Cannot be applied if the transition model is nonlinear Extended Kalman Filter models transition as locally linear around x t = µ t Fails if systems is locally unsmooth Chapter 15, Sections
45 Dynamic Bayesian networks X t, E t contain arbitrarily many variables in a replicated Bayes net BMeter 1 P(R ) R 0 t f P(R 1) Battery 0 Battery 1 Rain 0 Rain 1 R 1 t f P(U 1) X 0 X 1 Umbrella 1 txx 0 X 1 Z 1 Chapter 15, Sections
46 DBNs vs. HMMs Every HMM is a single-variable DBN; every discrete DBN is an HMM X t X t+1 Y t Yt+1 Z t Z t+1 Sparse dependencies exponentially fewer parameters; e.g., 20 state variables, three parents each DBN has =160 parameters, HMM has Chapter 15, Sections
47 DBNs vs Kalman filters Every Kalman filter model is a DBN, but few DBNs are KFs; real world requires non-gaussian posteriors E.g., where are bin Laden and my keys? What s the battery charge? BMBroken0 BMBroken1 BMeter 1 Battery 0 Battery 1 5 E(Battery ) 4 E(Battery ) X 0 txx 0 X 1 X 1 E(Battery) P(BMBroken ) 0 P(BMBroken ) Z Time step Chapter 15, Sections
48 Exact inference in DBNs Naive method: unroll the network and run any exact algorithm P(R 0) 0.7 Rain 0 R 0 t f P(R 1) Rain 1 P(R 0) 0.7 Rain 0 R 0 t f P(R 1) Rain 1 R 0 t f P(R 1) Rain 2 R 0 t f P(R 1) Rain 3 R 0 t f P(R 1) Rain 4 R 0 t f P(R 1) Rain 5 R 0 t f P(R 1) Rain 6 R 0 t f P(R 1) Rain 7 R 1 t f P(U 1) R 1 t f P(U 1) R 1 t f P(U 1) R 1 t f P(U 1) R 1 t f P(U 1) R 1 t f P(U 1) R 1 t f P(U 1) R 1 t f P(U 1) Umbrella 1 Umbrella 1 Umbrella 2 Umbrella 3 Umbrella 4 Umbrella 5 Umbrella 6 Umbrella 7 Problem: inference cost for each update grows with t Rollup filtering: add slice t +1, sum out slice t using variable elimination Largest factor is O(d n+1 ), update cost O(d n+2 ) (cf. HMM update cost O(d 2n )) Chapter 15, Sections
49 Likelihood weighting for DBNs Set of weighted samples approximates the belief state Rain 0 Rain 1 Rain 2 Rain 3 Rain 4 Rain 5 Umbrella 1 Umbrella 2 Umbrella 3 Umbrella 4 Umbrella 5 LW samples pay no attention to the evidence! fraction agreeing falls exponentially with t number of samples required grows exponentially with t LW(10) LW(100) LW(1000) LW(10000) RMS error Time step Chapter 15, Sections
50 Particle filtering Basic idea: ensure that the population of samples ( particles ) tracks the high-likelihood regions of the state-space Replicate particles proportional to likelihood for e t true Rain t Rain t +1 Rain t +1 Rain t +1 false (a) Propagate (b) Weight (c) Resample Widely used for tracking nonlinear systems, esp. in vision Also used for simultaneous localization and mapping in mobile robots dimensional state space Chapter 15, Sections
51 Particle filtering contd. Assume consistent at time t: N(x t e 1:t )/N = P (x t e 1:t ) Propagate forward: populations of x t+1 are N(x t+1 e 1:t )=Σ xt P (x t+1 x t )N(x t e 1:t ) Weight samples by their likelihood for e t+1 : W (x t+1 e 1:t+1 )=P (e t+1 x t+1 )N(x t+1 e 1:t ) Resample to obtain populations proportional to W : N(x t+1 e 1:t+1 )/N = αw (x t+1 e 1:t+1 )=αp (e t+1 x t+1 )N(x t+1 e 1:t ) = αp (e t+1 x t+1 )Σ xt P (x t+1 x t )N(x t e 1:t ) = α P (e t+1 x t+1 )Σ xt P (x t+1 x t )P (x t e 1:t ) = P (x t+1 e 1:t+1 ) Chapter 15, Sections
52 Particle filtering performance Approximation error of particle filtering remains bounded over time, at least empirically theoretical analysis is difficult Avg absolute error LW(25) LW(100) LW(1000) LW(10000) ER/SOF(25) Time step Chapter 15, Sections
53 Summary Temporal models use state and sensor variables replicated over time Markov assumptions and stationarity assumption, so we need transition modelp(x t X t 1 ) sensor model P(E t X t ) Tasks are filtering, prediction, smoothing, most likely sequence; all done recursively with constant cost per time step Hidden Markov models have a single discrete state variable; used for speech recognition Kalman filters allow n state variables, linear Gaussian, O(n 3 ) update Dynamic Bayes nets subsume HMMs, Kalman filters; exact update intractable Particle filtering is a good approximate filtering algorithm for DBNs Chapter 15, Sections
54
55
56
57
58
59
60
61
62
Temporal probability models. Chapter 15, Sections 1 5 1
 Temporal probability models Chapter 15, Sections 1 5 Chapter 15, Sections 1 5 1 Outline Time and uncertainty Inference: filtering, prediction, smoothing Hidden Markov models Kalman filters (a brief mention)
Temporal probability models Chapter 15, Sections 1 5 Chapter 15, Sections 1 5 1 Outline Time and uncertainty Inference: filtering, prediction, smoothing Hidden Markov models Kalman filters (a brief mention)
Hidden Markov models 1
 Hidden Markov models 1 Outline Time and uncertainty Markov process Hidden Markov models Inference: filtering, prediction, smoothing Most likely explanation: Viterbi 2 Time and uncertainty The world changes;
Hidden Markov models 1 Outline Time and uncertainty Markov process Hidden Markov models Inference: filtering, prediction, smoothing Most likely explanation: Viterbi 2 Time and uncertainty The world changes;
Temporal probability models. Chapter 15
 Temporal probability models Chapter 15 Outline Time and uncertainty Inference: filtering, prediction, smoothing Hidden Markov models Kalman filters (a brief mention) Dynamic Bayesian networks Particle
Temporal probability models Chapter 15 Outline Time and uncertainty Inference: filtering, prediction, smoothing Hidden Markov models Kalman filters (a brief mention) Dynamic Bayesian networks Particle
Hidden Markov Models. AIMA Chapter 15, Sections 1 5. AIMA Chapter 15, Sections 1 5 1
 Hidden Markov Models AIMA Chapter 15, Sections 1 5 AIMA Chapter 15, Sections 1 5 1 Consider a target tracking problem Time and uncertainty X t = set of unobservable state variables at time t e.g., Position
Hidden Markov Models AIMA Chapter 15, Sections 1 5 AIMA Chapter 15, Sections 1 5 1 Consider a target tracking problem Time and uncertainty X t = set of unobservable state variables at time t e.g., Position
Dynamic Bayesian Networks and Hidden Markov Models Decision Trees
 Lecture 11 Dynamic Bayesian Networks and Hidden Markov Models Decision Trees Marco Chiarandini Deptartment of Mathematics & Computer Science University of Southern Denmark Slides by Stuart Russell and
Lecture 11 Dynamic Bayesian Networks and Hidden Markov Models Decision Trees Marco Chiarandini Deptartment of Mathematics & Computer Science University of Southern Denmark Slides by Stuart Russell and
Temporal probability models. Chapter 15, Sections 1 5 1
 Temporal probabiliy models Chaper 15, Secions 1 5 Chaper 15, Secions 1 5 1 Ouline Time and uncerainy Inerence: ilering, predicion, smoohing Hidden Markov models Kalman ilers (a brie menion) Dynamic Bayesian
Temporal probabiliy models Chaper 15, Secions 1 5 Chaper 15, Secions 1 5 1 Ouline Time and uncerainy Inerence: ilering, predicion, smoohing Hidden Markov models Kalman ilers (a brie menion) Dynamic Bayesian
Temporal probability models
 Temporal probabiliy models CS194-10 Fall 2011 Lecure 25 CS194-10 Fall 2011 Lecure 25 1 Ouline Hidden variables Inerence: ilering, predicion, smoohing Hidden Markov models Kalman ilers (a brie menion) Dynamic
Temporal probabiliy models CS194-10 Fall 2011 Lecure 25 CS194-10 Fall 2011 Lecure 25 1 Ouline Hidden variables Inerence: ilering, predicion, smoohing Hidden Markov models Kalman ilers (a brie menion) Dynamic
Course Overview. Summary. Performance of approximation algorithms
 Course Overview Lecture 11 Dynamic ayesian Networks and Hidden Markov Models Decision Trees Marco Chiarandini Deptartment of Mathematics & Computer Science University of Southern Denmark Slides by Stuart
Course Overview Lecture 11 Dynamic ayesian Networks and Hidden Markov Models Decision Trees Marco Chiarandini Deptartment of Mathematics & Computer Science University of Southern Denmark Slides by Stuart
Artificial Intelligence
 Artificial Intelligence Roman Barták Department of Theoretical Computer Science and Mathematical Logic Summary of last lecture We know how to do probabilistic reasoning over time transition model P(X t
Artificial Intelligence Roman Barták Department of Theoretical Computer Science and Mathematical Logic Summary of last lecture We know how to do probabilistic reasoning over time transition model P(X t
Extensions of Bayesian Networks. Outline. Bayesian Network. Reasoning under Uncertainty. Features of Bayesian Networks.
 Extensions of Bayesian Networks Outline Ethan Howe, James Lenfestey, Tom Temple Intro to Dynamic Bayesian Nets (Tom Exact inference in DBNs with demo (Ethan Approximate inference and learning (Tom Probabilistic
Extensions of Bayesian Networks Outline Ethan Howe, James Lenfestey, Tom Temple Intro to Dynamic Bayesian Nets (Tom Exact inference in DBNs with demo (Ethan Approximate inference and learning (Tom Probabilistic
Kalman Filters, Dynamic Bayesian Networks
 Course 16:198:520: Introduction To Artificial Intelligence Lecture 12 Kalman Filters, Dynamic Bayesian Networks Abdeslam Boularias Monday, November 16, 2015 1 / 40 Example: Tracking the trajectory of a
Course 16:198:520: Introduction To Artificial Intelligence Lecture 12 Kalman Filters, Dynamic Bayesian Networks Abdeslam Boularias Monday, November 16, 2015 1 / 40 Example: Tracking the trajectory of a
CSCI 360 Introduc/on to Ar/ficial Intelligence Week 2: Problem Solving and Op/miza/on. Professor Wei-Min Shen Week 8.1 and 8.2
 CSCI 360 Introduc/on to Ar/ficial Intelligence Week 2: Problem Solving and Op/miza/on Professor Wei-Min Shen Week 8.1 and 8.2 Status Check Projects Project 2 Midterm is coming, please do your homework!
CSCI 360 Introduc/on to Ar/ficial Intelligence Week 2: Problem Solving and Op/miza/on Professor Wei-Min Shen Week 8.1 and 8.2 Status Check Projects Project 2 Midterm is coming, please do your homework!
Hidden Markov Models (recap BNs)
") Probabilistic reasoning over time - Hidden Markov Models (recap BNs) Applied artificial intelligence (EDA132) Lecture 10 2016-02-17 Elin A. Topp Material based on course book, chapter 15 1 A robot s view
Probabilistic reasoning over time - Hidden Markov Models (recap BNs) Applied artificial intelligence (EDA132) Lecture 10 2016-02-17 Elin A. Topp Material based on course book, chapter 15 1 A robot s view
CS 7180: Behavioral Modeling and Decision- making in AI
 CS 7180: Behavioral Modeling and Decision- making in AI Bayesian Networks for Dynamic and/or Relational Domains Prof. Amy Sliva October 12, 2012 World is not only uncertain, it is dynamic Beliefs, observations,
CS 7180: Behavioral Modeling and Decision- making in AI Bayesian Networks for Dynamic and/or Relational Domains Prof. Amy Sliva October 12, 2012 World is not only uncertain, it is dynamic Beliefs, observations,
CS532, Winter 2010 Hidden Markov Models
 CS532, Winter 2010 Hidden Markov Models Dr. Alan Fern, afern@eecs.oregonstate.edu March 8, 2010 1 Hidden Markov Models The world is dynamic and evolves over time. An intelligent agent in such a world needs
CS532, Winter 2010 Hidden Markov Models Dr. Alan Fern, afern@eecs.oregonstate.edu March 8, 2010 1 Hidden Markov Models The world is dynamic and evolves over time. An intelligent agent in such a world needs
Bayesian Networks BY: MOHAMAD ALSABBAGH
 Bayesian Networks BY: MOHAMAD ALSABBAGH Outlines Introduction Bayes Rule Bayesian Networks (BN) Representation Size of a Bayesian Network Inference via BN BN Learning Dynamic BN Introduction Conditional
Bayesian Networks BY: MOHAMAD ALSABBAGH Outlines Introduction Bayes Rule Bayesian Networks (BN) Representation Size of a Bayesian Network Inference via BN BN Learning Dynamic BN Introduction Conditional
Linear Dynamical Systems
 Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
CS 343: Artificial Intelligence
 CS 343: Artificial Intelligence Particle Filters and Applications of HMMs Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro
CS 343: Artificial Intelligence Particle Filters and Applications of HMMs Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro
CSEP 573: Artificial Intelligence
 CSEP 573: Artificial Intelligence Hidden Markov Models Luke Zettlemoyer Many slides over the course adapted from either Dan Klein, Stuart Russell, Andrew Moore, Ali Farhadi, or Dan Weld 1 Outline Probabilistic
CSEP 573: Artificial Intelligence Hidden Markov Models Luke Zettlemoyer Many slides over the course adapted from either Dan Klein, Stuart Russell, Andrew Moore, Ali Farhadi, or Dan Weld 1 Outline Probabilistic
Hidden Markov Models. Hal Daumé III. Computer Science University of Maryland CS 421: Introduction to Artificial Intelligence 19 Apr 2012
 Hidden Markov Models Hal Daumé III Computer Science University of Maryland me@hal3.name CS 421: Introduction to Artificial Intelligence 19 Apr 2012 Many slides courtesy of Dan Klein, Stuart Russell, or
Hidden Markov Models Hal Daumé III Computer Science University of Maryland me@hal3.name CS 421: Introduction to Artificial Intelligence 19 Apr 2012 Many slides courtesy of Dan Klein, Stuart Russell, or
CSE 473: Artificial Intelligence
 CSE 473: Artificial Intelligence Hidden Markov Models Dieter Fox --- University of Washington [Most slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188 materials
CSE 473: Artificial Intelligence Hidden Markov Models Dieter Fox --- University of Washington [Most slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188 materials
CS 343: Artificial Intelligence
 CS 343: Artificial Intelligence Particle Filters and Applications of HMMs Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro
CS 343: Artificial Intelligence Particle Filters and Applications of HMMs Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro
Markov Models. CS 188: Artificial Intelligence Fall Example. Mini-Forward Algorithm. Stationary Distributions.
 CS 88: Artificial Intelligence Fall 27 Lecture 2: HMMs /6/27 Markov Models A Markov model is a chain-structured BN Each node is identically distributed (stationarity) Value of X at a given time is called
CS 88: Artificial Intelligence Fall 27 Lecture 2: HMMs /6/27 Markov Models A Markov model is a chain-structured BN Each node is identically distributed (stationarity) Value of X at a given time is called
PROBABILISTIC REASONING Outline
 PROBABILISTIC REASONING Outline Danica Kragic Uncertainty Probability Syntax and Semantics Inference Independence and Bayes Rule September 23, 2005 Uncertainty - Let action A t = leave for airport t minutes
PROBABILISTIC REASONING Outline Danica Kragic Uncertainty Probability Syntax and Semantics Inference Independence and Bayes Rule September 23, 2005 Uncertainty - Let action A t = leave for airport t minutes
Bayesian Methods in Artificial Intelligence
 WDS'10 Proceedings of Contributed Papers, Part I, 25 30, 2010. ISBN 978-80-7378-139-2 MATFYZPRESS Bayesian Methods in Artificial Intelligence M. Kukačka Charles University, Faculty of Mathematics and Physics,
WDS'10 Proceedings of Contributed Papers, Part I, 25 30, 2010. ISBN 978-80-7378-139-2 MATFYZPRESS Bayesian Methods in Artificial Intelligence M. Kukačka Charles University, Faculty of Mathematics and Physics,
Human-Oriented Robotics. Temporal Reasoning. Kai Arras Social Robotics Lab, University of Freiburg
 Temporal Reasoning Kai Arras, University of Freiburg 1 Temporal Reasoning Contents Introduction Temporal Reasoning Hidden Markov Models Linear Dynamical Systems (LDS) Kalman Filter 2 Temporal Reasoning
Temporal Reasoning Kai Arras, University of Freiburg 1 Temporal Reasoning Contents Introduction Temporal Reasoning Hidden Markov Models Linear Dynamical Systems (LDS) Kalman Filter 2 Temporal Reasoning
Probabilistic Graphical Models
 Probabilistic Graphical Models Lecture 12 Dynamical Models CS/CNS/EE 155 Andreas Krause Homework 3 out tonight Start early!! Announcements Project milestones due today Please email to TAs 2 Parameter learning
Probabilistic Graphical Models Lecture 12 Dynamical Models CS/CNS/EE 155 Andreas Krause Homework 3 out tonight Start early!! Announcements Project milestones due today Please email to TAs 2 Parameter learning
Reasoning Under Uncertainty Over Time. CS 486/686: Introduction to Artificial Intelligence
 Reasoning Under Uncertainty Over Time CS 486/686: Introduction to Artificial Intelligence 1 Outline Reasoning under uncertainty over time Hidden Markov Models Dynamic Bayes Nets 2 Introduction So far we
Reasoning Under Uncertainty Over Time CS 486/686: Introduction to Artificial Intelligence 1 Outline Reasoning under uncertainty over time Hidden Markov Models Dynamic Bayes Nets 2 Introduction So far we
Linear Dynamical Systems (Kalman filter)
") Linear Dynamical Systems (Kalman filter) (a) Overview of HMMs (b) From HMMs to Linear Dynamical Systems (LDS) 1 Markov Chains with Discrete Random Variables x 1 x 2 x 3 x T Let s assume we have discrete
Linear Dynamical Systems (Kalman filter) (a) Overview of HMMs (b) From HMMs to Linear Dynamical Systems (LDS) 1 Markov Chains with Discrete Random Variables x 1 x 2 x 3 x T Let s assume we have discrete
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
Approximate Inference
 Approximate Inference Simulation has a name: sampling Sampling is a hot topic in machine learning, and it s really simple Basic idea: Draw N samples from a sampling distribution S Compute an approximate
Approximate Inference Simulation has a name: sampling Sampling is a hot topic in machine learning, and it s really simple Basic idea: Draw N samples from a sampling distribution S Compute an approximate
Kalman filtering and friends: Inference in time series models. Herke van Hoof slides mostly by Michael Rubinstein
 Kalman filtering and friends: Inference in time series models Herke van Hoof slides mostly by Michael Rubinstein Problem overview Goal Estimate most probable state at time k using measurement up to time
Kalman filtering and friends: Inference in time series models Herke van Hoof slides mostly by Michael Rubinstein Problem overview Goal Estimate most probable state at time k using measurement up to time
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation. Volker Tresp Summer 2014
 Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2014 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2014 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
CS 5522: Artificial Intelligence II
 CS 5522: Artificial Intelligence II Particle Filters and Applications of HMMs Instructor: Wei Xu Ohio State University [These slides were adapted from CS188 Intro to AI at UC Berkeley.] Recap: Reasoning
CS 5522: Artificial Intelligence II Particle Filters and Applications of HMMs Instructor: Wei Xu Ohio State University [These slides were adapted from CS188 Intro to AI at UC Berkeley.] Recap: Reasoning
CS 5522: Artificial Intelligence II
 CS 5522: Artificial Intelligence II Particle Filters and Applications of HMMs Instructor: Alan Ritter Ohio State University [These slides were adapted from CS188 Intro to AI at UC Berkeley. All materials
CS 5522: Artificial Intelligence II Particle Filters and Applications of HMMs Instructor: Alan Ritter Ohio State University [These slides were adapted from CS188 Intro to AI at UC Berkeley. All materials
CS 7180: Behavioral Modeling and Decision- making in AI
 CS 7180: Behavioral Modeling and Decision- making in AI Hidden Markov Models Prof. Amy Sliva October 26, 2012 Par?ally observable temporal domains POMDPs represented uncertainty about the state Belief
CS 7180: Behavioral Modeling and Decision- making in AI Hidden Markov Models Prof. Amy Sliva October 26, 2012 Par?ally observable temporal domains POMDPs represented uncertainty about the state Belief
Announcements. CS 188: Artificial Intelligence Fall VPI Example. VPI Properties. Reasoning over Time. Markov Models. Lecture 19: HMMs 11/4/2008
 CS 88: Artificial Intelligence Fall 28 Lecture 9: HMMs /4/28 Announcements Midterm solutions up, submit regrade requests within a week Midterm course evaluation up on web, please fill out! Dan Klein UC
CS 88: Artificial Intelligence Fall 28 Lecture 9: HMMs /4/28 Announcements Midterm solutions up, submit regrade requests within a week Midterm course evaluation up on web, please fill out! Dan Klein UC
Hidden Markov Models. Vibhav Gogate The University of Texas at Dallas
 Hidden Markov Models Vibhav Gogate The University of Texas at Dallas Intro to AI (CS 4365) Many slides over the course adapted from either Dan Klein, Luke Zettlemoyer, Stuart Russell or Andrew Moore 1
Hidden Markov Models Vibhav Gogate The University of Texas at Dallas Intro to AI (CS 4365) Many slides over the course adapted from either Dan Klein, Luke Zettlemoyer, Stuart Russell or Andrew Moore 1
Hidden Markov Models,99,100! Markov, here I come!
 Hidden Markov Models,99,100! Markov, here I come! 16.410/413 Principles of Autonomy and Decision-Making Pedro Santana (psantana@mit.edu) October 7 th, 2015. Based on material by Brian Williams and Emilio
Hidden Markov Models,99,100! Markov, here I come! 16.410/413 Principles of Autonomy and Decision-Making Pedro Santana (psantana@mit.edu) October 7 th, 2015. Based on material by Brian Williams and Emilio
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation. Volker Tresp Summer 2016
 Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2016 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2016 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Markov Models and Hidden Markov Models
 Markov Models and Hidden Markov Models Robert Platt Northeastern University Some images and slides are used from: 1. CS188 UC Berkeley 2. RN, AIMA Markov Models We have already seen that an MDP provides
Markov Models and Hidden Markov Models Robert Platt Northeastern University Some images and slides are used from: 1. CS188 UC Berkeley 2. RN, AIMA Markov Models We have already seen that an MDP provides
Markov Chains and Hidden Markov Models
 Markov Chains and Hidden Markov Models CE417: Introduction to Artificial Intelligence Sharif University of Technology Spring 2018 Soleymani Slides are based on Klein and Abdeel, CS188, UC Berkeley. Reasoning
Markov Chains and Hidden Markov Models CE417: Introduction to Artificial Intelligence Sharif University of Technology Spring 2018 Soleymani Slides are based on Klein and Abdeel, CS188, UC Berkeley. Reasoning
CS 343: Artificial Intelligence
 CS 343: Artificial Intelligence Hidden Markov Models Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
CS 343: Artificial Intelligence Hidden Markov Models Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
CS 188: Artificial Intelligence Spring 2009
 CS 188: Artificial Intelligence Spring 2009 Lecture 21: Hidden Markov Models 4/7/2009 John DeNero UC Berkeley Slides adapted from Dan Klein Announcements Written 3 deadline extended! Posted last Friday
CS 188: Artificial Intelligence Spring 2009 Lecture 21: Hidden Markov Models 4/7/2009 John DeNero UC Berkeley Slides adapted from Dan Klein Announcements Written 3 deadline extended! Posted last Friday
Hidden Markov Models. Aarti Singh Slides courtesy: Eric Xing. Machine Learning / Nov 8, 2010
 Hidden Markov Models Aarti Singh Slides courtesy: Eric Xing Machine Learning 10-701/15-781 Nov 8, 2010 i.i.d to sequential data So far we assumed independent, identically distributed data Sequential data
Hidden Markov Models Aarti Singh Slides courtesy: Eric Xing Machine Learning 10-701/15-781 Nov 8, 2010 i.i.d to sequential data So far we assumed independent, identically distributed data Sequential data
CS 5522: Artificial Intelligence II
 CS 5522: Artificial Intelligence II Hidden Markov Models Instructor: Wei Xu Ohio State University [These slides were adapted from CS188 Intro to AI at UC Berkeley.] Pacman Sonar (P4) [Demo: Pacman Sonar
CS 5522: Artificial Intelligence II Hidden Markov Models Instructor: Wei Xu Ohio State University [These slides were adapted from CS188 Intro to AI at UC Berkeley.] Pacman Sonar (P4) [Demo: Pacman Sonar
CS 188: Artificial Intelligence Fall 2011
 CS 188: Artificial Intelligence Fall 2011 Lecture 20: HMMs / Speech / ML 11/8/2011 Dan Klein UC Berkeley Today HMMs Demo bonanza! Most likely explanation queries Speech recognition A massive HMM! Details
CS 188: Artificial Intelligence Fall 2011 Lecture 20: HMMs / Speech / ML 11/8/2011 Dan Klein UC Berkeley Today HMMs Demo bonanza! Most likely explanation queries Speech recognition A massive HMM! Details
CS 5522: Artificial Intelligence II
 CS 5522: Artificial Intelligence II Hidden Markov Models Instructor: Alan Ritter Ohio State University [These slides were adapted from CS188 Intro to AI at UC Berkeley. All materials available at http://ai.berkeley.edu.]
CS 5522: Artificial Intelligence II Hidden Markov Models Instructor: Alan Ritter Ohio State University [These slides were adapted from CS188 Intro to AI at UC Berkeley. All materials available at http://ai.berkeley.edu.]
CS 188: Artificial Intelligence Spring Announcements
 CS 188: Artificial Intelligence Spring 2011 Lecture 18: HMMs and Particle Filtering 4/4/2011 Pieter Abbeel --- UC Berkeley Many slides over this course adapted from Dan Klein, Stuart Russell, Andrew Moore
CS 188: Artificial Intelligence Spring 2011 Lecture 18: HMMs and Particle Filtering 4/4/2011 Pieter Abbeel --- UC Berkeley Many slides over this course adapted from Dan Klein, Stuart Russell, Andrew Moore
1/30/2012. Reasoning with uncertainty III
 Reasoning with uncertainty III 1 Temporal Models Assumptions 2 Example First-order: From d-separation, X t+1 is conditionally independent of X t-1 given X t No independence of measurements Yt Alternate
Reasoning with uncertainty III 1 Temporal Models Assumptions 2 Example First-order: From d-separation, X t+1 is conditionally independent of X t-1 given X t No independence of measurements Yt Alternate
Introduction to Artificial Intelligence (AI)
") Introduction to Artificial Intelligence (AI) Computer Science cpsc502, Lecture 10 Oct, 13, 2011 CPSC 502, Lecture 10 Slide 1 Today Oct 13 Inference in HMMs More on Robot Localization CPSC 502, Lecture
Introduction to Artificial Intelligence (AI) Computer Science cpsc502, Lecture 10 Oct, 13, 2011 CPSC 502, Lecture 10 Slide 1 Today Oct 13 Inference in HMMs More on Robot Localization CPSC 502, Lecture
Hidden Markov Models. By Parisa Abedi. Slides courtesy: Eric Xing
 Hidden Markov Models By Parisa Abedi Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed data Sequential (non i.i.d.) data Time-series data E.g. Speech
Hidden Markov Models By Parisa Abedi Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed data Sequential (non i.i.d.) data Time-series data E.g. Speech
Lecture 6: Bayesian Inference in SDE Models
 Lecture 6: Bayesian Inference in SDE Models Bayesian Filtering and Smoothing Point of View Simo Särkkä Aalto University Simo Särkkä (Aalto) Lecture 6: Bayesian Inference in SDEs 1 / 45 Contents 1 SDEs
Lecture 6: Bayesian Inference in SDE Models Bayesian Filtering and Smoothing Point of View Simo Särkkä Aalto University Simo Särkkä (Aalto) Lecture 6: Bayesian Inference in SDEs 1 / 45 Contents 1 SDEs
Announcements. CS 188: Artificial Intelligence Fall Markov Models. Example: Markov Chain. Mini-Forward Algorithm. Example
 CS 88: Artificial Intelligence Fall 29 Lecture 9: Hidden Markov Models /3/29 Announcements Written 3 is up! Due on /2 (i.e. under two weeks) Project 4 up very soon! Due on /9 (i.e. a little over two weeks)
CS 88: Artificial Intelligence Fall 29 Lecture 9: Hidden Markov Models /3/29 Announcements Written 3 is up! Due on /2 (i.e. under two weeks) Project 4 up very soon! Due on /9 (i.e. a little over two weeks)
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 13: SEQUENTIAL DATA
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 13: SEQUENTIAL DATA Contents in latter part Linear Dynamical Systems What is different from HMM? Kalman filter Its strength and limitation Particle Filter
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 13: SEQUENTIAL DATA Contents in latter part Linear Dynamical Systems What is different from HMM? Kalman filter Its strength and limitation Particle Filter
Markov localization uses an explicit, discrete representation for the probability of all position in the state space.
 Markov Kalman Filter Localization Markov localization localization starting from any unknown position recovers from ambiguous situation. However, to update the probability of all positions within the whole
Markov Kalman Filter Localization Markov localization localization starting from any unknown position recovers from ambiguous situation. However, to update the probability of all positions within the whole
Lecture 2: From Linear Regression to Kalman Filter and Beyond
 Lecture 2: From Linear Regression to Kalman Filter and Beyond January 18, 2017 Contents 1 Batch and Recursive Estimation 2 Towards Bayesian Filtering 3 Kalman Filter and Bayesian Filtering and Smoothing
Lecture 2: From Linear Regression to Kalman Filter and Beyond January 18, 2017 Contents 1 Batch and Recursive Estimation 2 Towards Bayesian Filtering 3 Kalman Filter and Bayesian Filtering and Smoothing
Why do we care? Measurements. Handling uncertainty over time: predicting, estimating, recognizing, learning. Dealing with time
 Handling uncertainty over time: predicting, estimating, recognizing, learning Chris Atkeson 2004 Why do we care? Speech recognition makes use of dependence of words and phonemes across time. Knowing where
Handling uncertainty over time: predicting, estimating, recognizing, learning Chris Atkeson 2004 Why do we care? Speech recognition makes use of dependence of words and phonemes across time. Knowing where
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 Hidden Markov Models Barnabás Póczos & Aarti Singh Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed
Introduction to Machine Learning CMU-10701 Hidden Markov Models Barnabás Póczos & Aarti Singh Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed
9 Forward-backward algorithm, sum-product on factor graphs
 Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.438 Algorithms For Inference Fall 2014 9 Forward-backward algorithm, sum-product on factor graphs The previous
Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.438 Algorithms For Inference Fall 2014 9 Forward-backward algorithm, sum-product on factor graphs The previous
Probability, Markov models and HMMs. Vibhav Gogate The University of Texas at Dallas
 Probability, Markov models and HMMs Vibhav Gogate The University of Texas at Dallas CS 6364 Many slides over the course adapted from either Dan Klein, Luke Zettlemoyer, Stuart Russell and Andrew Moore
Probability, Markov models and HMMs Vibhav Gogate The University of Texas at Dallas CS 6364 Many slides over the course adapted from either Dan Klein, Luke Zettlemoyer, Stuart Russell and Andrew Moore
Probabilistic Graphical Models
 Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 12: Gaussian Belief Propagation, State Space Models and Kalman Filters Guest Kalman Filter Lecture by
Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 12: Gaussian Belief Propagation, State Space Models and Kalman Filters Guest Kalman Filter Lecture by
Note Set 5: Hidden Markov Models
 Note Set 5: Hidden Markov Models Probabilistic Learning: Theory and Algorithms, CS 274A, Winter 2016 1 Hidden Markov Models (HMMs) 1.1 Introduction Consider observed data vectors x t that are d-dimensional
Note Set 5: Hidden Markov Models Probabilistic Learning: Theory and Algorithms, CS 274A, Winter 2016 1 Hidden Markov Models (HMMs) 1.1 Introduction Consider observed data vectors x t that are d-dimensional
COMP90051 Statistical Machine Learning
 COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 24. Hidden Markov Models & message passing Looking back Representation of joint distributions Conditional/marginal independence
COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 24. Hidden Markov Models & message passing Looking back Representation of joint distributions Conditional/marginal independence
The Kalman Filter ImPr Talk
 The Kalman Filter ImPr Talk Ged Ridgway Centre for Medical Image Computing November, 2006 Outline What is the Kalman Filter? State Space Models Kalman Filter Overview Bayesian Updating of Estimates Kalman
The Kalman Filter ImPr Talk Ged Ridgway Centre for Medical Image Computing November, 2006 Outline What is the Kalman Filter? State Space Models Kalman Filter Overview Bayesian Updating of Estimates Kalman
CS 188: Artificial Intelligence Fall Recap: Inference Example
 CS 188: Artificial Intelligence Fall 2007 Lecture 19: Decision Diagrams 11/01/2007 Dan Klein UC Berkeley Recap: Inference Example Find P( F=bad) Restrict all factors P() P(F=bad ) P() 0.7 0.3 eather 0.7
CS 188: Artificial Intelligence Fall 2007 Lecture 19: Decision Diagrams 11/01/2007 Dan Klein UC Berkeley Recap: Inference Example Find P( F=bad) Restrict all factors P() P(F=bad ) P() 0.7 0.3 eather 0.7
CSE 473: Artificial Intelligence Probability Review à Markov Models. Outline
 CSE 473: Artificial Intelligence Probability Review à Markov Models Daniel Weld University of Washington [These slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
CSE 473: Artificial Intelligence Probability Review à Markov Models Daniel Weld University of Washington [These slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
Mathematical Formulation of Our Example
 Mathematical Formulation of Our Example We define two binary random variables: open and, where is light on or light off. Our question is: What is? Computer Vision 1 Combining Evidence Suppose our robot
Mathematical Formulation of Our Example We define two binary random variables: open and, where is light on or light off. Our question is: What is? Computer Vision 1 Combining Evidence Suppose our robot
Modeling and state estimation Examples State estimation Probabilities Bayes filter Particle filter. Modeling. CSC752 Autonomous Robotic Systems
 Modeling CSC752 Autonomous Robotic Systems Ubbo Visser Department of Computer Science University of Miami February 21, 2017 Outline 1 Modeling and state estimation 2 Examples 3 State estimation 4 Probabilities
Modeling CSC752 Autonomous Robotic Systems Ubbo Visser Department of Computer Science University of Miami February 21, 2017 Outline 1 Modeling and state estimation 2 Examples 3 State estimation 4 Probabilities
CSE 473: Artificial Intelligence Spring 2014
 CSE 473: Artificial Intelligence Spring 2014 Hidden Markov Models Hanna Hajishirzi Many slides adapted from Dan Weld, Pieter Abbeel, Dan Klein, Stuart Russell, Andrew Moore & Luke Zettlemoyer 1 Outline
CSE 473: Artificial Intelligence Spring 2014 Hidden Markov Models Hanna Hajishirzi Many slides adapted from Dan Weld, Pieter Abbeel, Dan Klein, Stuart Russell, Andrew Moore & Luke Zettlemoyer 1 Outline
Inference in Bayesian networks
 Inference in Bayesian networks AIMA2e hapter 14.4 5 1 Outline Exact inference by enumeration Exact inference by variable elimination Approximate inference by stochastic simulation Approximate inference
Inference in Bayesian networks AIMA2e hapter 14.4 5 1 Outline Exact inference by enumeration Exact inference by variable elimination Approximate inference by stochastic simulation Approximate inference
CSE 473: Ar+ficial Intelligence. Probability Recap. Markov Models - II. Condi+onal probability. Product rule. Chain rule.
 CSE 473: Ar+ficial Intelligence Markov Models - II Daniel S. Weld - - - University of Washington [Most slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188
CSE 473: Ar+ficial Intelligence Markov Models - II Daniel S. Weld - - - University of Washington [Most slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188
Temporal Models.
 Temporal Models www.cs.wisc.edu/~page/cs760/ Goals for the lecture (with thanks to Irene Ong, Stuart Russell and Peter Norvig, Jakob Rasmussen, Jeremy Weiss, Yujia Bao, Charles Kuang, Peggy Peissig, and
Temporal Models www.cs.wisc.edu/~page/cs760/ Goals for the lecture (with thanks to Irene Ong, Stuart Russell and Peter Norvig, Jakob Rasmussen, Jeremy Weiss, Yujia Bao, Charles Kuang, Peggy Peissig, and
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
Advanced Data Science
 Advanced Data Science Dr. Kira Radinsky Slides Adapted from Tom M. Mitchell Agenda Topics Covered: Time series data Markov Models Hidden Markov Models Dynamic Bayes Nets Additional Reading: Bishop: Chapter
Advanced Data Science Dr. Kira Radinsky Slides Adapted from Tom M. Mitchell Agenda Topics Covered: Time series data Markov Models Hidden Markov Models Dynamic Bayes Nets Additional Reading: Bishop: Chapter
Lecture 4: State Estimation in Hidden Markov Models (cont.)
") EE378A Statistical Signal Processing Lecture 4-04/13/2017 Lecture 4: State Estimation in Hidden Markov Models (cont.) Lecturer: Tsachy Weissman Scribe: David Wugofski In this lecture we build on previous
EE378A Statistical Signal Processing Lecture 4-04/13/2017 Lecture 4: State Estimation in Hidden Markov Models (cont.) Lecturer: Tsachy Weissman Scribe: David Wugofski In this lecture we build on previous
Autonomous Navigation for Flying Robots
 Computer Vision Group Prof. Daniel Cremers Autonomous Navigation for Flying Robots Lecture 6.2: Kalman Filter Jürgen Sturm Technische Universität München Motivation Bayes filter is a useful tool for state
Computer Vision Group Prof. Daniel Cremers Autonomous Navigation for Flying Robots Lecture 6.2: Kalman Filter Jürgen Sturm Technische Universität München Motivation Bayes filter is a useful tool for state
CS 188: Artificial Intelligence
 CS 188: Artificial Intelligence Hidden Markov Models Instructor: Anca Dragan --- University of California, Berkeley [These slides were created by Dan Klein, Pieter Abbeel, and Anca. http://ai.berkeley.edu.]
CS 188: Artificial Intelligence Hidden Markov Models Instructor: Anca Dragan --- University of California, Berkeley [These slides were created by Dan Klein, Pieter Abbeel, and Anca. http://ai.berkeley.edu.]
STATS 306B: Unsupervised Learning Spring Lecture 5 April 14
 STATS 306B: Unsupervised Learning Spring 2014 Lecture 5 April 14 Lecturer: Lester Mackey Scribe: Brian Do and Robin Jia 5.1 Discrete Hidden Markov Models 5.1.1 Recap In the last lecture, we introduced
STATS 306B: Unsupervised Learning Spring 2014 Lecture 5 April 14 Lecturer: Lester Mackey Scribe: Brian Do and Robin Jia 5.1 Discrete Hidden Markov Models 5.1.1 Recap In the last lecture, we introduced
Sequential Monte Carlo Methods for Bayesian Computation
 Sequential Monte Carlo Methods for Bayesian Computation A. Doucet Kyoto Sept. 2012 A. Doucet (MLSS Sept. 2012) Sept. 2012 1 / 136 Motivating Example 1: Generic Bayesian Model Let X be a vector parameter
Sequential Monte Carlo Methods for Bayesian Computation A. Doucet Kyoto Sept. 2012 A. Doucet (MLSS Sept. 2012) Sept. 2012 1 / 136 Motivating Example 1: Generic Bayesian Model Let X be a vector parameter
Outline. CSE 573: Artificial Intelligence Autumn Agent. Partial Observability. Markov Decision Process (MDP) 10/31/2012
 10/31/2012") CSE 573: Artificial Intelligence Autumn 2012 Reasoning about Uncertainty & Hidden Markov Models Daniel Weld Many slides adapted from Dan Klein, Stuart Russell, Andrew Moore & Luke Zettlemoyer 1 Outline
CSE 573: Artificial Intelligence Autumn 2012 Reasoning about Uncertainty & Hidden Markov Models Daniel Weld Many slides adapted from Dan Klein, Stuart Russell, Andrew Moore & Luke Zettlemoyer 1 Outline
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 24, 2016 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 24, 2016 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Template-Based Representations. Sargur Srihari
 Template-Based Representations Sargur srihari@cedar.buffalo.edu 1 Topics Variable-based vs Template-based Temporal Models Basic Assumptions Dynamic Bayesian Networks Hidden Markov Models Linear Dynamical
Template-Based Representations Sargur srihari@cedar.buffalo.edu 1 Topics Variable-based vs Template-based Temporal Models Basic Assumptions Dynamic Bayesian Networks Hidden Markov Models Linear Dynamical
Introduction to Mobile Robotics Probabilistic Robotics
 Introduction to Mobile Robotics Probabilistic Robotics Wolfram Burgard 1 Probabilistic Robotics Key idea: Explicit representation of uncertainty (using the calculus of probability theory) Perception Action
Introduction to Mobile Robotics Probabilistic Robotics Wolfram Burgard 1 Probabilistic Robotics Key idea: Explicit representation of uncertainty (using the calculus of probability theory) Perception Action
Sequence labeling. Taking collective a set of interrelated instances x 1,, x T and jointly labeling them
 HMM, MEMM and CRF 40-957 Special opics in Artificial Intelligence: Probabilistic Graphical Models Sharif University of echnology Soleymani Spring 2014 Sequence labeling aking collective a set of interrelated
HMM, MEMM and CRF 40-957 Special opics in Artificial Intelligence: Probabilistic Graphical Models Sharif University of echnology Soleymani Spring 2014 Sequence labeling aking collective a set of interrelated
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
CS325 Artificial Intelligence Ch. 15,20 Hidden Markov Models and Particle Filtering
 CS325 Artificial Intelligence Ch. 15,20 Hidden Markov Models and Particle Filtering Cengiz Günay, Emory Univ. Günay Ch. 15,20 Hidden Markov Models and Particle FilteringSpring 2013 1 / 21 Get Rich Fast!
CS325 Artificial Intelligence Ch. 15,20 Hidden Markov Models and Particle Filtering Cengiz Günay, Emory Univ. Günay Ch. 15,20 Hidden Markov Models and Particle FilteringSpring 2013 1 / 21 Get Rich Fast!
LEARNING DYNAMIC SYSTEMS: MARKOV MODELS
 LEARNING DYNAMIC SYSTEMS: MARKOV MODELS Markov Process and Markov Chains Hidden Markov Models Kalman Filters Types of dynamic systems Problem of future state prediction Predictability Observability Easily
LEARNING DYNAMIC SYSTEMS: MARKOV MODELS Markov Process and Markov Chains Hidden Markov Models Kalman Filters Types of dynamic systems Problem of future state prediction Predictability Observability Easily
CS 188: Artificial Intelligence. Our Status in CS188
 CS 188: Artificial Intelligence Probability Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. 1 Our Status in CS188 We re done with Part I Search and Planning! Part II: Probabilistic Reasoning
CS 188: Artificial Intelligence Probability Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. 1 Our Status in CS188 We re done with Part I Search and Planning! Part II: Probabilistic Reasoning
Stochastic inference in Bayesian networks, Markov chain Monte Carlo methods
 Stochastic inference in Bayesian networks, Markov chain Monte Carlo methods AI: Stochastic inference in BNs AI: Stochastic inference in BNs 1 Outline ypes of inference in (causal) BNs Hardness of exact
Stochastic inference in Bayesian networks, Markov chain Monte Carlo methods AI: Stochastic inference in BNs AI: Stochastic inference in BNs 1 Outline ypes of inference in (causal) BNs Hardness of exact
Machine Learning 4771
 Machine Learning 4771 Instructor: ony Jebara Kalman Filtering Linear Dynamical Systems and Kalman Filtering Structure from Motion Linear Dynamical Systems Audio: x=pitch y=acoustic waveform Vision: x=object
Machine Learning 4771 Instructor: ony Jebara Kalman Filtering Linear Dynamical Systems and Kalman Filtering Structure from Motion Linear Dynamical Systems Audio: x=pitch y=acoustic waveform Vision: x=object
Hidden Markov models
 Hidden Markov models Charles Elkan November 26, 2012 Important: These lecture notes are based on notes written by Lawrence Saul. Also, these typeset notes lack illustrations. See the classroom lectures
Hidden Markov models Charles Elkan November 26, 2012 Important: These lecture notes are based on notes written by Lawrence Saul. Also, these typeset notes lack illustrations. See the classroom lectures
Introduction to Artificial Intelligence (AI)
") Introduction to Artificial Intelligence (AI) Computer Science cpsc502, Lecture 9 Oct, 11, 2011 Slide credit Approx. Inference : S. Thrun, P, Norvig, D. Klein CPSC 502, Lecture 9 Slide 1 Today Oct 11 Bayesian
Introduction to Artificial Intelligence (AI) Computer Science cpsc502, Lecture 9 Oct, 11, 2011 Slide credit Approx. Inference : S. Thrun, P, Norvig, D. Klein CPSC 502, Lecture 9 Slide 1 Today Oct 11 Bayesian
2-Step Temporal Bayesian Networks (2TBN): Filtering, Smoothing, and Beyond Technical Report: TRCIM1030
: Filtering, Smoothing, and Beyond Technical Report: TRCIM1030") 2-Step Temporal Bayesian Networks (2TBN): Filtering, Smoothing, and Beyond Technical Report: TRCIM1030 Anqi Xu anqixu(at)cim(dot)mcgill(dot)ca School of Computer Science, McGill University, Montreal, Canada,
2-Step Temporal Bayesian Networks (2TBN): Filtering, Smoothing, and Beyond Technical Report: TRCIM1030 Anqi Xu anqixu(at)cim(dot)mcgill(dot)ca School of Computer Science, McGill University, Montreal, Canada,
Robot Localization and Kalman Filters
 Robot Localization and Kalman Filters Rudy Negenborn rudy@negenborn.net August 26, 2003 Outline Robot Localization Probabilistic Localization Kalman Filters Kalman Localization Kalman Localization with
Robot Localization and Kalman Filters Rudy Negenborn rudy@negenborn.net August 26, 2003 Outline Robot Localization Probabilistic Localization Kalman Filters Kalman Localization Kalman Localization with
Bayesian Approaches Data Mining Selected Technique
 Bayesian Approaches Data Mining Selected Technique Henry Xiao xiao@cs.queensu.ca School of Computing Queen s University Henry Xiao CISC 873 Data Mining p. 1/17 Probabilistic Bases Review the fundamentals
Bayesian Approaches Data Mining Selected Technique Henry Xiao xiao@cs.queensu.ca School of Computing Queen s University Henry Xiao CISC 873 Data Mining p. 1/17 Probabilistic Bases Review the fundamentals
Bayesian Machine Learning - Lecture 7
 Bayesian Machine Learning - Lecture 7 Guido Sanguinetti Institute for Adaptive and Neural Computation School of Informatics University of Edinburgh gsanguin@inf.ed.ac.uk March 4, 2015 Today s lecture 1
Bayesian Machine Learning - Lecture 7 Guido Sanguinetti Institute for Adaptive and Neural Computation School of Informatics University of Edinburgh gsanguin@inf.ed.ac.uk March 4, 2015 Today s lecture 1
Multiscale Systems Engineering Research Group
 Hidden Markov Model Prof. Yan Wang Woodruff School of Mechanical Engineering Georgia Institute of echnology Atlanta, GA 30332, U.S.A. yan.wang@me.gatech.edu Learning Objectives o familiarize the hidden
Hidden Markov Model Prof. Yan Wang Woodruff School of Mechanical Engineering Georgia Institute of echnology Atlanta, GA 30332, U.S.A. yan.wang@me.gatech.edu Learning Objectives o familiarize the hidden
Why do we care? Examples. Bayes Rule. What room am I in? Handling uncertainty over time: predicting, estimating, recognizing, learning
 Handling uncertainty over time: predicting, estimating, recognizing, learning Chris Atkeson 004 Why do we care? Speech recognition makes use of dependence of words and phonemes across time. Knowing where
Handling uncertainty over time: predicting, estimating, recognizing, learning Chris Atkeson 004 Why do we care? Speech recognition makes use of dependence of words and phonemes across time. Knowing where