|
|
|
- Jocelyn Rose Morton
- 5 years ago
- Views:
Transcription
1
2
3
4
5
6 docid score
7
8 O'Neal averaged 15.2 points 9.2 rebounds and 1.0 assists per game o'neal averaged 15.2 points 9.2 rebounds and 1.0 assists per game o'neal averaged 15.2 points 9.2 rebounds 1.0 assists per game o'neal averag 15.2 point 9.2 rebound 1.0 assist per game
9

10
11
12
13 Original Porter2 Krovetz organization organ organization organ organ organ heading head heading head head head Original Porter2 Krovetz european european europe europe europ europe urgency urgenc urgent urgent urgent urgent
14 D
15 cos x, y x x x x k y y y y k x y x y i1 k x y i k k 2 2 x i yi i1 i1 i
16 x x x x k y y y y k cos x, y k x y x y xi yi x y x y x y i1
17 cos q, d q q q q d d d d k k q d q d q d k i i i i i1 i1 k k k qi di di i1 i1 i1 k q d
18 w TF t, D IDF t i i i
19 TF binary t, D i 1 c ti, D 0 0 c ti, D 0
20 TFraw ti, D c ti, D
21 TF raw t, D i c t D ct D 1 log b c ti, D i, 0 0 i, 0
22 y x log 1 x y log 2 x y log x y log 10 x
23 log log31.10 q
24
25 IDF t uniform 1 i
26 IDF KSJ t log N n t
27 IDF BM 25 t log N nt 0.5 N nt n t 0 n t N 2




28 Multivariate Bernoulli Distribution Results of n independent Bernoulli trails {X 1,, X n } n different coins; toss each coin once Each coin may have a different probability of heads/tails X 1 : tails X 2 : heads X 3 : heads X 4 : heads Different from a binomial distribution with size n Toss the same coin n times (each time independent of others)
29 A Multivariate Bernoulli Model of Document Consider a document D as the outcome of the model Let be a document D s binary term occurrence vector What is the probability of by this MB model? X i P(X i = 1) P(X i = 0) index retrieval search information data computer science index=1 retrieval=1 search=0 information=1 data=0 computer=1 science=0 P D P P P P P P P
30 Naïve Bayes Classification using MB Models X i P(X i = 1 IR) P(X i = 1 DB) index search information data computer relevance SQL P(IR) = 0.3 P(DB) = 0.7 P IR D P IR P X i Di IR P DB D P DB P X D DB i X V i i P IR D P DB D D is 6.33 times more likely to be an IR article than a DB one.
31 log P R D, Q pi 1qi log P NR D, Q 1 p q i t QD i i p P X 1 R, Q i i q P X 1 NR, Q i i p i qi q N n i t i log log log 1 p q q n 0.5 t QD i i t QD i t QD t i i i i
32 ,, scorebm25 d q weightbm25 d q q q i i weight BM25 1 q, d k 1 tf N n 0.5 i i d, qi log dl ni 0.5 k 1 1 b b tfq i, d avdl tf : the raw frequency of q in d q, d i N : the total number of documents in the corpus dl : the length of the document d avdl : the average length of documents in the corpus 1 i n : the document frequency of q k and b are two parameters i i
33 weight k 1 BM25 determines the upperbound of TF: k 1 tf dl k 1 1 b b tf avdl 1 q, d k 1 tf N n 0.5 i i d, qi log dl ni 0.5 k 1 1 b b tfq i, d avdl 1 lim k1 1 tf For an average-length document ( dl avdl), TF k1 1 tf k1 1 tf dl k1 tf k 1 1 b b tf avdl
34 weight BM25 1 q, d k 1 tf N n 0.5 i i d, qi log dl ni 0.5 k 1 1 b b tfq i, d avdl For a longer-than-average document, raw tf will be penalized, k1 1 tf k1 1 tf k1 1 tf TF dl dl avdl k1 tf k 1 1 b b tf k1 tf k1b avdl avdl For a shorter-than-average document, raw tf will be boosted, k1 1 tf k1 1 tf k1 1 tf TF dl dl avdl k1 tf k 1 1 b b tf k1 tf k1b avdl avdl
35 tf dl k 1 1 b b tf avdl tf
36 tf dl k 1 1 b b tf avdl tf
37 tf dl k 1 1 b b tf avdl tf
38 θ θ θ θ tv P t 1 t P(t θ) index 0.21 retrieval 0.32 search 0.18 information 0.11 data 0.06 computer 0.04 science 0.08
39 θ Pt P D n i i t P(t θ) index 0.21 retrieval 0.32 search 0.18 information 0.11 data 0.06 computer 0.04 science 0.08
40 t c(t,d) P(t IR) P(t DB) index retrieval search information data computer science Prior Prob. P(IR)=0.3 P(DB)=0.7 c t, D c t, D P IR D P IR P t IR P DB D P DB td P t DB P IR D P DB D
41 θ θ θ Pt P q D tq Pt log P q D log tq D D ± ±
42 Recap: The Query likelihood model (QL) Each document is generated from a document LM θ D Estimate a language model θ D for the document D Rank documents by P(q θ D ) Example: QL ranks D 1 higher than D 2 D 1 s model t P(t θ D1 ) index 0.21 retrieval 0.32 search 0.18 information 0.11 data 0.06 computer 0.04 science 0.08? query information retrieval Pt P q D1 D1 tq? Pt D2 D2 tq D 2 s model t P(t θ D2 ) index 0.17 retrieval 0.05 search 0.22 information 0.12 data 0.33 computer 0.08 science 0.03 P q
43 ˆ c t, D term frequency PMLE t D D document length ˆ information D D Pˆ MLE retrieval D ˆ 1 1 PMLE an D Pˆ MLE for D Pˆ MLE technique D P MLE ˆ is 1 12 PMLE D ˆ important P MLE D
44 ˆ c t, D term frequency PMLE t D D document length c t, D ˆ D corpus term frequency PMLE t corpus corpus length D D t DF P X e N ˆ i IDF i MLE i 1 corpus t
45 MLE: Recall Several Issues Unseen words get zero probability As long as one query term does not appear in D, the document gets zero probability. Ranking by P MLE (q D) is similar to Boolean AND But no occurrence does not mean impossible. Limited sample size MLE is reasonably good for a large sample size. But we are estimating a document model, usually just a few hundred/thousand words long. In some cases (will cover next lecture), we also need to estimate a query model. The sample size is even shorter. Solution: smoothing (will discuss a few slides later )
46 Jelinek-Mercer Smoothing Start simple, but reasonably good Using P(t Corpus) as the background model Set λ to be constant for all documents, independent of any document or query characteristics Tune to optimize retrieval performance e.g., maximize mean values of or AP over a set of different queries in a dataset. optimal value of λ varies with different databases, query sets, etc. Correctly setting λ is very important 1 P t P t P t Corpus D MLE D
47 Jelinek-Mercer Smoothing Example: λ = 0.5, D = Psmoothed the D word freq P MLE (* D) P(* Corpus) Smoothed the soviet chernobyl disclosure divert downplaye each early
48 Dirichlet Smoothing Problem with Jelinek-Mercer All documents have the same λ Longer documents provide better estimates (because it provides a larger sample), and thus its own MLE is more reliable Make smoothing depend on sample size (adaptive) Here D is the length of the sample and is a constant P t D, Pt Corpus c t D D D MLE weight: 1 Corpus weight: D D
49 Dirichlet Smoothing Example: = 500, D = 1281 Psmoothed D the word freq P MLE (* D) P(* Corpus) Smoothed the soviet chernobyl disclosure divert downplaye each early
50 Smoothing and IDF Similar to many retrieval models, we can write QL as:,, where, log score q D w t D w t D P t D tq Dirichlet smoothing: P t D tf P t Corpus D tf JM smoothing: P t D 1 D Pt Corpus w t, D 1 P t D tf P t D tf Dirichlet: JM: w t, D 1 1 tf P t D D w t, D 1 1 tf P t D D tf is discrete, but let s just assume the functions are all continuous here.
51 Smoothing and IDF No matter in which smoothing method is employed, common words get much higher P smoothed (t D) The weight (score) of the common words by QL increases much slower than that for less common and rare words while raw tf increases. wt D Dirichlet: wt, D 1 Pt D tf Pt D tf, 1 1 JM: w t D tf Pt D D, which is the same for common and less common terms., 1 1 tf P t D D tf log P t, D 1 For MLE: Pt, D,, only depends on tf D tf tf tf is discrete, but let s just assume the functions are all continuous here.
52 Dirichlet smoothing, = Long document, D = 5000; short document, D = 100. Common word, P(t corpus) = 0.01; less common word, P(t corpus) = log P smoothed For common words, log P smoothed increases much slower. tf
53 KLDP Q Pilog i P i Q i
54 θ θ θ θ KLD P t log P t q D Pt q t t q D q log D q log q P t P t P t P t t
55 q D q log D q log q KLD P t P t P t P t ˆ c t, q when PMLE t q, q t t q log Pt D P t, log Pt c t q D ct, q t 1 log Pt D QL q q q t t
56 How to improve retrieval? Clustering search results Group top-ranked results into different topics Showing only a few results for each topic To avoid that the top-ranked results are biased towards only one particular topic Using clusters to improve document representation Because a document is (relatively) short Document representation is boosted by taken into account the clusters/topics it belongs to
57 Cluster-based Document Model Liu & Croft, SIGIR 04 Using k-means for clustering; unigram as features Represent a cluster as a language model, c t cluster Pt cluster 1 c t, cluster Smooth a document D s MLE model using The corpus model (the same as QL) The model of the cluster D belongs to t i i Pt corpus 1 P t D P t D P t cluster P t corpus 1 MLE 2 1 2
58 LDA-based Document Model Wei & Croft, SIGIR 05 Similar to the cluster-based document model Smooth a document MLE model with The corpus model A mixture model of the document s topics
59 Pseudo-relevance Feedback Pseudo-relevance feedback (PRF); blind feedback; Do an initial search using a regular approach, such as QL Assume the top k ranked results as relevant Perform relevance feedback based on the top k results Normally by query expansion Re-run the query A few practical issues The assumption Efficiency concerns: expand a short query (2-3 words) into a long one (e.g., ~50 words) Practically effective for improving overall search effectiveness (in terms of the mean values of effectiveness metrics) Our focus today
60 RM1 Pt, q R D D D D D D R R D D R R,, P D R P t q D R,, P D R P t D R P q D R,, P D R P t D R P q D R P t D P q D q q i i q q i i A1, A2 A3 A4 Assumptions A1: is uniform A2: and A3: A4:
61 RM1 RM1: P t q, R P t, q R P t D P q D Computation Iterate over each feedback document (source) D Assign a weight to D In terms of PRF, we just retrieve top k results by QL and weight each document by QL probability Higher-ranked results get more weights Expand a term t from D by the weight P(t D)P(q D) Sum up terms weights in each feedback document D Normalize the terms weights to probability P t q, R DD R t DD j R D D R i q q Pt D Pqi D qi q Pt j D Pqi D q q i i
62 RM2 RM2: P t q, R P t D P q D j i j qi q R Computation Iterate over each query term q i Iterate over each feedback document D Assign a weight P(q i D) to D Expand a term t from D by P(t D)P(q i D): if both t and q i occur frequently in D, t gets a greater weight Sum up the weight in each document Multiply the expansion weight for each q i Normalize the terms weights to probability P t D j P t D D D D j D

63 Comparing different approaches Lv & Zhai, CIKM 09
64 Pseudo-relevance Feedback Usually believed to be a useful technique But somewhat controversial Recall oriented; limited improvements in precision at the top Making good queries bad; making bad queries worse Overall improvements: average values of metrics? But improving bad/difficult queries may be more important Search efficiency concern Difficult to control; unpredictable for the user Difficult to improve in noisy corpus (such as web corpus) Using some clean corpus for query expansion, e.g., Wikipedia
65
66
67
68
69
70
71 Average Precision (AP): example = the relevant documents Ranking #1 Rank = 1, precision = 1 Rank = 3, precision = 2/3 Rank = 6, precision = 3/6 Rank = 9, precision = 4/9 Rank = 10, precision = 5/10 AP = 1/5 x (1+2/3+3/6+4/9+5/10)
72 Average Precision (AP): example = the relevant documents Ranking #2 AP=?
73 Average Precision (AP): example = the relevant documents Ranking #2 Rank = 2, precision = 1/2 Rank = 5, precision = 2/5 Rank = 6, precision = 3/6 Rank = 7, precision = 4/7 A relevant result is not retrieved we can consider the retrieved rank=, precision = 0 AP = 1/5 x (1/2+2/5+3/6+4/7+0)
74
75
76
77
78 k k r 2 i 1 log i 1 i1 2
79 k k r 2 i 1 log i 1 i1 2
80 k DCG@ k IDCG@ k
81 log 2 log 3 log 4 log 5 log log 2 log 3 log 4 log 5 log
82
83
84
85
86
87
88
89
90
91
92 User Sequence User Sequence User 1 A -> B -> C User 4 A -> B -> C User 2 B - > C -> A User 5 B - > C -> A User 3 C - > A -> B User 6 C - > A -> B

93
94
95
96
97
98
99 R 1 n 2 i1 n i1 y i y i yˆ i y 2 2
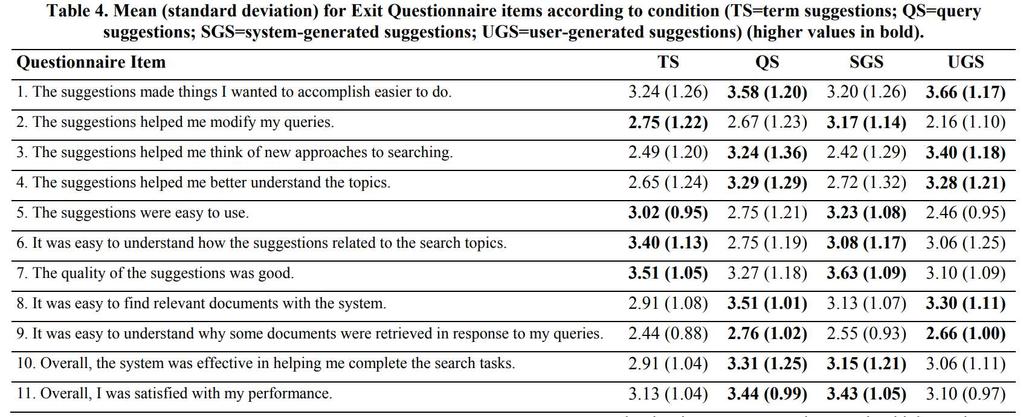
100 ˆ 1 1 Ajusted n i i i n i i y y n n R R n p n p y y
101
102 Lucene Galago Indri Task Task
103 Lucene Galago Indri Mean
104
105
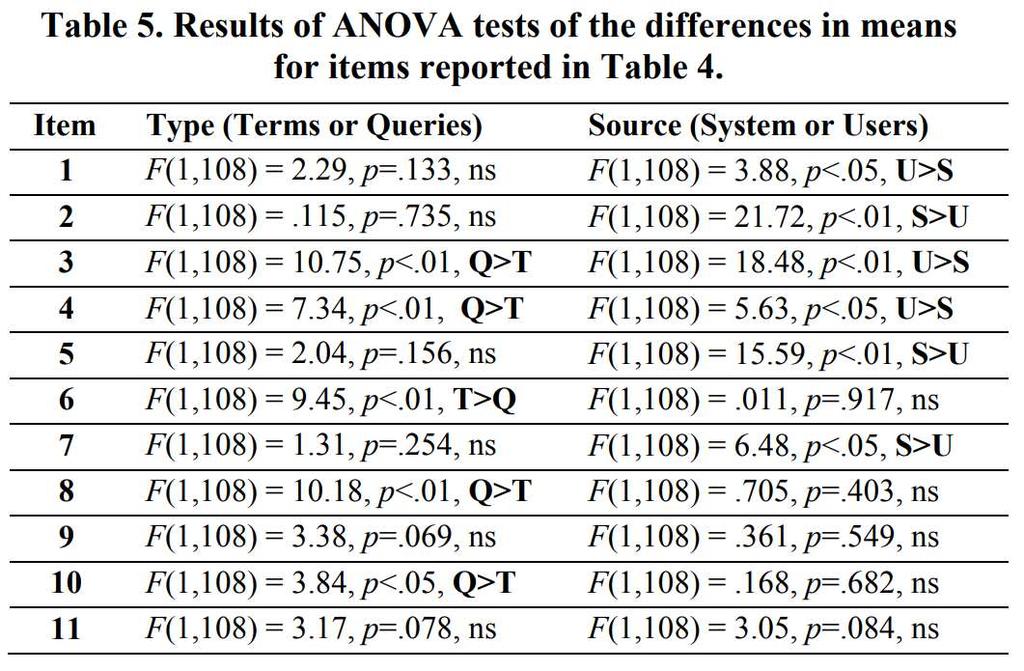
106 Source DF Adj SS Adj MS F-Value P-Value Task System Task * System Error Total
107 Source DF Adj SS Adj MS F-Value P-Value Task System Task * System Error Total
108
109
CS 646 (Fall 2016) Homework 3
 Homework 3") CS 646 (Fall 2016) Homework 3 Deadline: 11:59pm, Oct 31st, 2016 (EST) Access the following resources before you start working on HW3: Download and uncompress the index file and other data from Moodle.
CS 646 (Fall 2016) Homework 3 Deadline: 11:59pm, Oct 31st, 2016 (EST) Access the following resources before you start working on HW3: Download and uncompress the index file and other data from Moodle.
Ranked Retrieval (2)
") Text Technologies for Data Science INFR11145 Ranked Retrieval (2) Instructor: Walid Magdy 31-Oct-2017 Lecture Objectives Learn about Probabilistic models BM25 Learn about LM for IR 2 1 Recall: VSM & TFIDF
Text Technologies for Data Science INFR11145 Ranked Retrieval (2) Instructor: Walid Magdy 31-Oct-2017 Lecture Objectives Learn about Probabilistic models BM25 Learn about LM for IR 2 1 Recall: VSM & TFIDF
Information Retrieval
 Introduction to Information Retrieval Lecture 12: Language Models for IR Outline Language models Language Models for IR Discussion What is a language model? We can view a finite state automaton as a deterministic
Introduction to Information Retrieval Lecture 12: Language Models for IR Outline Language models Language Models for IR Discussion What is a language model? We can view a finite state automaton as a deterministic
Lecture 13: More uses of Language Models
 Lecture 13: More uses of Language Models William Webber (william@williamwebber.com) COMP90042, 2014, Semester 1, Lecture 13 What we ll learn in this lecture Comparing documents, corpora using LM approaches
Lecture 13: More uses of Language Models William Webber (william@williamwebber.com) COMP90042, 2014, Semester 1, Lecture 13 What we ll learn in this lecture Comparing documents, corpora using LM approaches
Language Models. Web Search. LM Jelinek-Mercer Smoothing and LM Dirichlet Smoothing. Slides based on the books: 13
 Language Models LM Jelinek-Mercer Smoothing and LM Dirichlet Smoothing Web Search Slides based on the books: 13 Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis
Language Models LM Jelinek-Mercer Smoothing and LM Dirichlet Smoothing Web Search Slides based on the books: 13 Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis
RETRIEVAL MODELS. Dr. Gjergji Kasneci Introduction to Information Retrieval WS
 RETRIEVAL MODELS Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Retrieval models Boolean model Vector space model Probabilistic
RETRIEVAL MODELS Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Retrieval models Boolean model Vector space model Probabilistic
Language Models. Hongning Wang
 Language Models Hongning Wang CS@UVa Notion of Relevance Relevance (Rep(q), Rep(d)) Similarity P(r1 q,d) r {0,1} Probability of Relevance P(d q) or P(q d) Probabilistic inference Different rep & similarity
Language Models Hongning Wang CS@UVa Notion of Relevance Relevance (Rep(q), Rep(d)) Similarity P(r1 q,d) r {0,1} Probability of Relevance P(d q) or P(q d) Probabilistic inference Different rep & similarity
University of Illinois at Urbana-Champaign. Midterm Examination
 University of Illinois at Urbana-Champaign Midterm Examination CS410 Introduction to Text Information Systems Professor ChengXiang Zhai TA: Azadeh Shakery Time: 2:00 3:15pm, Mar. 14, 2007 Place: Room 1105,
University of Illinois at Urbana-Champaign Midterm Examination CS410 Introduction to Text Information Systems Professor ChengXiang Zhai TA: Azadeh Shakery Time: 2:00 3:15pm, Mar. 14, 2007 Place: Room 1105,
Fall CS646: Information Retrieval. Lecture 6 Boolean Search and Vector Space Model. Jiepu Jiang University of Massachusetts Amherst 2016/09/26
 Fall 2016 CS646: Information Retrieval Lecture 6 Boolean Search and Vector Space Model Jiepu Jiang University of Massachusetts Amherst 2016/09/26 Outline Today Boolean Retrieval Vector Space Model Latent
Fall 2016 CS646: Information Retrieval Lecture 6 Boolean Search and Vector Space Model Jiepu Jiang University of Massachusetts Amherst 2016/09/26 Outline Today Boolean Retrieval Vector Space Model Latent
Midterm Examination Practice
 University of Illinois at Urbana-Champaign Midterm Examination Practice CS598CXZ Advanced Topics in Information Retrieval (Fall 2013) Professor ChengXiang Zhai 1. Basic IR evaluation measures: The following
University of Illinois at Urbana-Champaign Midterm Examination Practice CS598CXZ Advanced Topics in Information Retrieval (Fall 2013) Professor ChengXiang Zhai 1. Basic IR evaluation measures: The following
Information Retrieval
 Introduction to Information Retrieval Lecture 11: Probabilistic Information Retrieval 1 Outline Basic Probability Theory Probability Ranking Principle Extensions 2 Basic Probability Theory For events A
Introduction to Information Retrieval Lecture 11: Probabilistic Information Retrieval 1 Outline Basic Probability Theory Probability Ranking Principle Extensions 2 Basic Probability Theory For events A
PV211: Introduction to Information Retrieval
 PV211: Introduction to Information Retrieval http://www.fi.muni.cz/~sojka/pv211 IIR 11: Probabilistic Information Retrieval Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk
PV211: Introduction to Information Retrieval http://www.fi.muni.cz/~sojka/pv211 IIR 11: Probabilistic Information Retrieval Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk
Bayesian Methods: Naïve Bayes
 Bayesian Methods: aïve Bayes icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Last Time Parameter learning Learning the parameter of a simple coin flipping model Prior
Bayesian Methods: aïve Bayes icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Last Time Parameter learning Learning the parameter of a simple coin flipping model Prior
Probabilistic Field Mapping for Product Search
 Probabilistic Field Mapping for Product Search Aman Berhane Ghirmatsion and Krisztian Balog University of Stavanger, Stavanger, Norway ab.ghirmatsion@stud.uis.no, krisztian.balog@uis.no, Abstract. This
Probabilistic Field Mapping for Product Search Aman Berhane Ghirmatsion and Krisztian Balog University of Stavanger, Stavanger, Norway ab.ghirmatsion@stud.uis.no, krisztian.balog@uis.no, Abstract. This
Language Models. CS6200: Information Retrieval. Slides by: Jesse Anderton
 Language Models CS6200: Information Retrieval Slides by: Jesse Anderton What s wrong with VSMs? Vector Space Models work reasonably well, but have a few problems: They are based on bag-of-words, so they
Language Models CS6200: Information Retrieval Slides by: Jesse Anderton What s wrong with VSMs? Vector Space Models work reasonably well, but have a few problems: They are based on bag-of-words, so they
Language Models, Smoothing, and IDF Weighting
 Language Models, Smoothing, and IDF Weighting Najeeb Abdulmutalib, Norbert Fuhr University of Duisburg-Essen, Germany {najeeb fuhr}@is.inf.uni-due.de Abstract In this paper, we investigate the relationship
Language Models, Smoothing, and IDF Weighting Najeeb Abdulmutalib, Norbert Fuhr University of Duisburg-Essen, Germany {najeeb fuhr}@is.inf.uni-due.de Abstract In this paper, we investigate the relationship
IR Models: The Probabilistic Model. Lecture 8
 IR Models: The Probabilistic Model Lecture 8 ' * ) ( % $ $ +#! "#! '& & Probability of Relevance? ' ', IR is an uncertain process Information need to query Documents to index terms Query terms and index
IR Models: The Probabilistic Model Lecture 8 ' * ) ( % $ $ +#! "#! '& & Probability of Relevance? ' ', IR is an uncertain process Information need to query Documents to index terms Query terms and index
Chapter 10: Information Retrieval. See corresponding chapter in Manning&Schütze
 Chapter 10: Information Retrieval See corresponding chapter in Manning&Schütze Evaluation Metrics in IR 2 Goal In IR there is a much larger variety of possible metrics For different tasks, different metrics
Chapter 10: Information Retrieval See corresponding chapter in Manning&Schütze Evaluation Metrics in IR 2 Goal In IR there is a much larger variety of possible metrics For different tasks, different metrics
PROBABILITY AND INFORMATION THEORY. Dr. Gjergji Kasneci Introduction to Information Retrieval WS
 PROBABILITY AND INFORMATION THEORY Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Probability space Rules of probability
PROBABILITY AND INFORMATION THEORY Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Probability space Rules of probability
Chapter 4: Advanced IR Models
 Chapter 4: Advanced I Models 4.1 robabilistic I 4.1.1 rinciples 4.1.2 robabilistic I with Term Independence 4.1.3 robabilistic I with 2-oisson Model (Okapi BM25) IDM WS 2005 4-1 4.1.1 robabilistic etrieval:
Chapter 4: Advanced I Models 4.1 robabilistic I 4.1.1 rinciples 4.1.2 robabilistic I with Term Independence 4.1.3 robabilistic I with 2-oisson Model (Okapi BM25) IDM WS 2005 4-1 4.1.1 robabilistic etrieval:
Language Models and Smoothing Methods for Collections with Large Variation in Document Length. 2 Models
 Language Models and Smoothing Methods for Collections with Large Variation in Document Length Najeeb Abdulmutalib and Norbert Fuhr najeeb@is.inf.uni-due.de, norbert.fuhr@uni-due.de Information Systems,
Language Models and Smoothing Methods for Collections with Large Variation in Document Length Najeeb Abdulmutalib and Norbert Fuhr najeeb@is.inf.uni-due.de, norbert.fuhr@uni-due.de Information Systems,
Lecture 9: Probabilistic IR The Binary Independence Model and Okapi BM25
 Lecture 9: Probabilistic IR The Binary Independence Model and Okapi BM25 Trevor Cohn (Slide credits: William Webber) COMP90042, 2015, Semester 1 What we ll learn in this lecture Probabilistic models for
Lecture 9: Probabilistic IR The Binary Independence Model and Okapi BM25 Trevor Cohn (Slide credits: William Webber) COMP90042, 2015, Semester 1 What we ll learn in this lecture Probabilistic models for
Boolean and Vector Space Retrieval Models
 Boolean and Vector Space Retrieval Models Many slides in this section are adapted from Prof. Joydeep Ghosh (UT ECE) who in turn adapted them from Prof. Dik Lee (Univ. of Science and Tech, Hong Kong) 1
Boolean and Vector Space Retrieval Models Many slides in this section are adapted from Prof. Joydeep Ghosh (UT ECE) who in turn adapted them from Prof. Dik Lee (Univ. of Science and Tech, Hong Kong) 1
Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology
 CE-324: Modern Information Retrieval Sharif University of Technology") Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2016 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2016 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Retrieval by Content. Part 2: Text Retrieval Term Frequency and Inverse Document Frequency. Srihari: CSE 626 1
 Retrieval by Content Part 2: Text Retrieval Term Frequency and Inverse Document Frequency Srihari: CSE 626 1 Text Retrieval Retrieval of text-based information is referred to as Information Retrieval (IR)
Retrieval by Content Part 2: Text Retrieval Term Frequency and Inverse Document Frequency Srihari: CSE 626 1 Text Retrieval Retrieval of text-based information is referred to as Information Retrieval (IR)
Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology
 CE-324: Modern Information Retrieval Sharif University of Technology") Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2017 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2017 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
CS630 Representing and Accessing Digital Information Lecture 6: Feb 14, 2006
 Scribes: Gilly Leshed, N. Sadat Shami Outline. Review. Mixture of Poissons ( Poisson) model 3. BM5/Okapi method 4. Relevance feedback. Review In discussing probabilistic models for information retrieval
Scribes: Gilly Leshed, N. Sadat Shami Outline. Review. Mixture of Poissons ( Poisson) model 3. BM5/Okapi method 4. Relevance feedback. Review In discussing probabilistic models for information retrieval
Name: Matriculation Number: Tutorial Group: A B C D E
 Name: Matriculation Number: Tutorial Group: A B C D E Question: 1 (5 Points) 2 (6 Points) 3 (5 Points) 4 (5 Points) Total (21 points) Score: General instructions: The written test contains 4 questions
Name: Matriculation Number: Tutorial Group: A B C D E Question: 1 (5 Points) 2 (6 Points) 3 (5 Points) 4 (5 Points) Total (21 points) Score: General instructions: The written test contains 4 questions
Probabilistic Information Retrieval
 Probabilistic Information Retrieval Sumit Bhatia July 16, 2009 Sumit Bhatia Probabilistic Information Retrieval 1/23 Overview 1 Information Retrieval IR Models Probability Basics 2 Document Ranking Problem
Probabilistic Information Retrieval Sumit Bhatia July 16, 2009 Sumit Bhatia Probabilistic Information Retrieval 1/23 Overview 1 Information Retrieval IR Models Probability Basics 2 Document Ranking Problem
ChengXiang ( Cheng ) Zhai Department of Computer Science University of Illinois at Urbana-Champaign
 Zhai Department of Computer Science University of Illinois at Urbana-Champaign") Axiomatic Analysis and Optimization of Information Retrieval Models ChengXiang ( Cheng ) Zhai Department of Computer Science University of Illinois at Urbana-Champaign http://www.cs.uiuc.edu/homes/czhai
Axiomatic Analysis and Optimization of Information Retrieval Models ChengXiang ( Cheng ) Zhai Department of Computer Science University of Illinois at Urbana-Champaign http://www.cs.uiuc.edu/homes/czhai
Expectation maximization tutorial
 Expectation maximization tutorial Octavian Ganea November 18, 2016 1/1 Today Expectation - maximization algorithm Topic modelling 2/1 ML & MAP Observed data: X = {x 1, x 2... x N } 3/1 ML & MAP Observed
Expectation maximization tutorial Octavian Ganea November 18, 2016 1/1 Today Expectation - maximization algorithm Topic modelling 2/1 ML & MAP Observed data: X = {x 1, x 2... x N } 3/1 ML & MAP Observed
Statistical methods for NLP Estimation
 Statistical methods for NLP Estimation UNIVERSITY OF Richard Johansson January 29, 2015 why does the teacher care so much about the coin-tossing experiment? because it can model many situations: I pick
Statistical methods for NLP Estimation UNIVERSITY OF Richard Johansson January 29, 2015 why does the teacher care so much about the coin-tossing experiment? because it can model many situations: I pick
Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology
 CE-324: Modern Information Retrieval Sharif University of Technology") Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Scoring (Vector Space Model) CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
CS 446 Machine Learning Fall 2016 Nov 01, Bayesian Learning
 CS 446 Machine Learning Fall 206 Nov 0, 206 Bayesian Learning Professor: Dan Roth Scribe: Ben Zhou, C. Cervantes Overview Bayesian Learning Naive Bayes Logistic Regression Bayesian Learning So far, we
CS 446 Machine Learning Fall 206 Nov 0, 206 Bayesian Learning Professor: Dan Roth Scribe: Ben Zhou, C. Cervantes Overview Bayesian Learning Naive Bayes Logistic Regression Bayesian Learning So far, we
Advanced Topics in Information Retrieval 5. Diversity & Novelty
 Advanced Topics in Information Retrieval 5. Diversity & Novelty Vinay Setty (vsetty@mpi-inf.mpg.de) Jannik Strötgen (jtroetge@mpi-inf.mpg.de) 1 Outline 5.1. Why Novelty & Diversity? 5.2. Probability Ranking
Advanced Topics in Information Retrieval 5. Diversity & Novelty Vinay Setty (vsetty@mpi-inf.mpg.de) Jannik Strötgen (jtroetge@mpi-inf.mpg.de) 1 Outline 5.1. Why Novelty & Diversity? 5.2. Probability Ranking
Term Weighting and the Vector Space Model. borrowing from: Pandu Nayak and Prabhakar Raghavan
 Term Weighting and the Vector Space Model borrowing from: Pandu Nayak and Prabhakar Raghavan IIR Sections 6.2 6.4.3 Ranked retrieval Scoring documents Term frequency Collection statistics Weighting schemes
Term Weighting and the Vector Space Model borrowing from: Pandu Nayak and Prabhakar Raghavan IIR Sections 6.2 6.4.3 Ranked retrieval Scoring documents Term frequency Collection statistics Weighting schemes
Chap 2: Classical models for information retrieval
 Chap 2: Classical models for information retrieval Jean-Pierre Chevallet & Philippe Mulhem LIG-MRIM Sept 2016 Jean-Pierre Chevallet & Philippe Mulhem Models of IR 1 / 81 Outline Basic IR Models 1 Basic
Chap 2: Classical models for information retrieval Jean-Pierre Chevallet & Philippe Mulhem LIG-MRIM Sept 2016 Jean-Pierre Chevallet & Philippe Mulhem Models of IR 1 / 81 Outline Basic IR Models 1 Basic
INFO 630 / CS 674 Lecture Notes
 INFO 630 / CS 674 Lecture Notes The Language Modeling Approach to Information Retrieval Lecturer: Lillian Lee Lecture 9: September 25, 2007 Scribes: Vladimir Barash, Stephen Purpura, Shaomei Wu Introduction
INFO 630 / CS 674 Lecture Notes The Language Modeling Approach to Information Retrieval Lecturer: Lillian Lee Lecture 9: September 25, 2007 Scribes: Vladimir Barash, Stephen Purpura, Shaomei Wu Introduction
Vector Space Scoring Introduction to Information Retrieval Informatics 141 / CS 121 Donald J. Patterson
 Vector Space Scoring Introduction to Information Retrieval Informatics 141 / CS 121 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Querying Corpus-wide statistics
Vector Space Scoring Introduction to Information Retrieval Informatics 141 / CS 121 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Querying Corpus-wide statistics
Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 6 Scoring term weighting and the vector space model
 Chapter 6 Scoring term weighting and the vector space model") Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 6 Scoring term weighting and the vector space model Ranked retrieval Thus far, our queries have all been Boolean. Documents either
Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 6 Scoring term weighting and the vector space model Ranked retrieval Thus far, our queries have all been Boolean. Documents either
Chapter 3: Maximum-Likelihood & Bayesian Parameter Estimation (part 1)
") HW 1 due today Parameter Estimation Biometrics CSE 190 Lecture 7 Today s lecture was on the blackboard. These slides are an alternative presentation of the material. CSE190, Winter10 CSE190, Winter10 Chapter
HW 1 due today Parameter Estimation Biometrics CSE 190 Lecture 7 Today s lecture was on the blackboard. These slides are an alternative presentation of the material. CSE190, Winter10 CSE190, Winter10 Chapter
Information Retrieval
 Introduction to Information Retrieval CS276: Information Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan Lecture 6: Scoring, Term Weighting and the Vector Space Model This lecture; IIR Sections
Introduction to Information Retrieval CS276: Information Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan Lecture 6: Scoring, Term Weighting and the Vector Space Model This lecture; IIR Sections
On the Foundations of Diverse Information Retrieval. Scott Sanner, Kar Wai Lim, Shengbo Guo, Thore Graepel, Sarvnaz Karimi, Sadegh Kharazmi
 On the Foundations of Diverse Information Retrieval Scott Sanner, Kar Wai Lim, Shengbo Guo, Thore Graepel, Sarvnaz Karimi, Sadegh Kharazmi 1 Outline Need for diversity The answer: MMR But what was the
On the Foundations of Diverse Information Retrieval Scott Sanner, Kar Wai Lim, Shengbo Guo, Thore Graepel, Sarvnaz Karimi, Sadegh Kharazmi 1 Outline Need for diversity The answer: MMR But what was the
Ranking-II. Temporal Representation and Retrieval Models. Temporal Information Retrieval
 Ranking-II Temporal Representation and Retrieval Models Temporal Information Retrieval Ranking in Information Retrieval Ranking documents important for information overload, quickly finding documents which
Ranking-II Temporal Representation and Retrieval Models Temporal Information Retrieval Ranking in Information Retrieval Ranking documents important for information overload, quickly finding documents which
Fielded Sequential Dependence Model for Ad-Hoc Entity Retrieval in the Web of Data
 Fielded Sequential Dependence Model for Ad-Hoc Entity Retrieval in the Web of Data Nikita Zhiltsov 1,2 Alexander Kotov 3 Fedor Nikolaev 3 1 Kazan Federal University 2 Textocat 3 Textual Data Analytics
Fielded Sequential Dependence Model for Ad-Hoc Entity Retrieval in the Web of Data Nikita Zhiltsov 1,2 Alexander Kotov 3 Fedor Nikolaev 3 1 Kazan Federal University 2 Textocat 3 Textual Data Analytics
The Naïve Bayes Classifier. Machine Learning Fall 2017
 The Naïve Bayes Classifier Machine Learning Fall 2017 1 Today s lecture The naïve Bayes Classifier Learning the naïve Bayes Classifier Practical concerns 2 Today s lecture The naïve Bayes Classifier Learning
The Naïve Bayes Classifier Machine Learning Fall 2017 1 Today s lecture The naïve Bayes Classifier Learning the naïve Bayes Classifier Practical concerns 2 Today s lecture The naïve Bayes Classifier Learning
Motivation. User. Retrieval Model Result: Query. Document Collection. Information Need. Information Retrieval / Chapter 3: Retrieval Models
 3. Retrieval Models Motivation Information Need User Retrieval Model Result: Query 1. 2. 3. Document Collection 2 Agenda 3.1 Boolean Retrieval 3.2 Vector Space Model 3.3 Probabilistic IR 3.4 Statistical
3. Retrieval Models Motivation Information Need User Retrieval Model Result: Query 1. 2. 3. Document Collection 2 Agenda 3.1 Boolean Retrieval 3.2 Vector Space Model 3.3 Probabilistic IR 3.4 Statistical
Is Document Frequency important for PRF?
 Author manuscript, published in "ICTIR 2011 - International Conference on the Theory Information Retrieval, Bertinoro : Italy (2011)" Is Document Frequency important for PRF? Stéphane Clinchant 1,2 and
Author manuscript, published in "ICTIR 2011 - International Conference on the Theory Information Retrieval, Bertinoro : Italy (2011)" Is Document Frequency important for PRF? Stéphane Clinchant 1,2 and
A Study of Smoothing Methods for Language Models Applied to Information Retrieval
 A Study of Smoothing Methods for Language Models Applied to Information Retrieval CHENGXIANG ZHAI and JOHN LAFFERTY Carnegie Mellon University Language modeling approaches to information retrieval are
A Study of Smoothing Methods for Language Models Applied to Information Retrieval CHENGXIANG ZHAI and JOHN LAFFERTY Carnegie Mellon University Language modeling approaches to information retrieval are
Sparse vectors recap. ANLP Lecture 22 Lexical Semantics with Dense Vectors. Before density, another approach to normalisation.
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
Vector Space Scoring Introduction to Information Retrieval INF 141 Donald J. Patterson
 Vector Space Scoring Introduction to Information Retrieval INF 141 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Querying Corpus-wide statistics Querying
Vector Space Scoring Introduction to Information Retrieval INF 141 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Querying Corpus-wide statistics Querying
Information Retrieval Basic IR models. Luca Bondi
 Basic IR models Luca Bondi Previously on IR 2 d j q i IRM SC q i, d j IRM D, Q, R q i, d j d j = w 1,j, w 2,j,, w M,j T w i,j = 0 if term t i does not appear in document d j w i,j and w i:1,j assumed to
Basic IR models Luca Bondi Previously on IR 2 d j q i IRM SC q i, d j IRM D, Q, R q i, d j d j = w 1,j, w 2,j,, w M,j T w i,j = 0 if term t i does not appear in document d j w i,j and w i:1,j assumed to
Ranked IR. Lecture Objectives. Text Technologies for Data Science INFR Learn about Ranked IR. Implement: 10/10/2017. Instructor: Walid Magdy
 Text Technologies for Data Science INFR11145 Ranked IR Instructor: Walid Magdy 10-Oct-017 Lecture Objectives Learn about Ranked IR TFIDF VSM SMART notation Implement: TFIDF 1 Boolean Retrieval Thus far,
Text Technologies for Data Science INFR11145 Ranked IR Instructor: Walid Magdy 10-Oct-017 Lecture Objectives Learn about Ranked IR TFIDF VSM SMART notation Implement: TFIDF 1 Boolean Retrieval Thus far,
DISTRIBUTIONAL SEMANTICS
 COMP90042 LECTURE 4 DISTRIBUTIONAL SEMANTICS LEXICAL DATABASES - PROBLEMS Manually constructed Expensive Human annotation can be biased and noisy Language is dynamic New words: slangs, terminology, etc.
COMP90042 LECTURE 4 DISTRIBUTIONAL SEMANTICS LEXICAL DATABASES - PROBLEMS Manually constructed Expensive Human annotation can be biased and noisy Language is dynamic New words: slangs, terminology, etc.
Score Distribution Models
 Score Distribution Models Evangelos Kanoulas Virgil Pavlu Keshi Dai Javed Aslam Score Distributions 2 Score Distributions 2 Score Distributions 9.6592 9.5761 9.4919 9.4784 9.2693 9.2066 9.1407 9.0824 9.0110
Score Distribution Models Evangelos Kanoulas Virgil Pavlu Keshi Dai Javed Aslam Score Distributions 2 Score Distributions 2 Score Distributions 9.6592 9.5761 9.4919 9.4784 9.2693 9.2066 9.1407 9.0824 9.0110
Statistical Methods for NLP
 Statistical Methods for NLP Information Extraction, Hidden Markov Models Sameer Maskey Week 5, Oct 3, 2012 *many slides provided by Bhuvana Ramabhadran, Stanley Chen, Michael Picheny Speech Recognition
Statistical Methods for NLP Information Extraction, Hidden Markov Models Sameer Maskey Week 5, Oct 3, 2012 *many slides provided by Bhuvana Ramabhadran, Stanley Chen, Michael Picheny Speech Recognition
IMU Experiment in IR4QA at NTCIR-8
 IMU Experiment in IR4QA at NTCIR-8 Xiangdong Su, Xueliang Yan, Guanglai Gao, Hongxi Wei School of Computer Science Inner Mongolia University Hohhot, China 010021 Email csggl@imu.edu.cn 6/16/2010 Inner
IMU Experiment in IR4QA at NTCIR-8 Xiangdong Su, Xueliang Yan, Guanglai Gao, Hongxi Wei School of Computer Science Inner Mongolia University Hohhot, China 010021 Email csggl@imu.edu.cn 6/16/2010 Inner
Concept Tracking for Microblog Search
 1,a) 1,b) 1,c) 2013 12 22, 2014 4 7 2 Tweets2011 Twitter Concept Tracking for Microblog Search Taiki Miyanishi 1,a) Kazuhiro Seki 1,b) Kuniaki Uehara 1,c) Received: December 22, 2013, Accepted: April 7,
1,a) 1,b) 1,c) 2013 12 22, 2014 4 7 2 Tweets2011 Twitter Concept Tracking for Microblog Search Taiki Miyanishi 1,a) Kazuhiro Seki 1,b) Kuniaki Uehara 1,c) Received: December 22, 2013, Accepted: April 7,
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING Text Data: Topic Model Instructor: Yizhou Sun yzsun@cs.ucla.edu December 4, 2017 Methods to be Learnt Vector Data Set Data Sequence Data Text Data Classification Clustering
CS145: INTRODUCTION TO DATA MINING Text Data: Topic Model Instructor: Yizhou Sun yzsun@cs.ucla.edu December 4, 2017 Methods to be Learnt Vector Data Set Data Sequence Data Text Data Classification Clustering
CS 188: Artificial Intelligence Spring Today
 CS 188: Artificial Intelligence Spring 2006 Lecture 9: Naïve Bayes 2/14/2006 Dan Klein UC Berkeley Many slides from either Stuart Russell or Andrew Moore Bayes rule Today Expectations and utilities Naïve
CS 188: Artificial Intelligence Spring 2006 Lecture 9: Naïve Bayes 2/14/2006 Dan Klein UC Berkeley Many slides from either Stuart Russell or Andrew Moore Bayes rule Today Expectations and utilities Naïve
Lower-Bounding Term Frequency Normalization
 Lower-Bounding Term Frequency Normalization Yuanhua Lv Department of Computer Science University of Illinois at Urbana-Champaign Urbana, IL 68 ylv@uiuc.edu ChengXiang Zhai Department of Computer Science
Lower-Bounding Term Frequency Normalization Yuanhua Lv Department of Computer Science University of Illinois at Urbana-Champaign Urbana, IL 68 ylv@uiuc.edu ChengXiang Zhai Department of Computer Science
Language Modelling: Smoothing and Model Complexity. COMP-599 Sept 14, 2016
 Language Modelling: Smoothing and Model Complexity COMP-599 Sept 14, 2016 Announcements A1 has been released Due on Wednesday, September 28th Start code for Question 4: Includes some of the package import
Language Modelling: Smoothing and Model Complexity COMP-599 Sept 14, 2016 Announcements A1 has been released Due on Wednesday, September 28th Start code for Question 4: Includes some of the package import
Outline for today. Information Retrieval. Cosine similarity between query and document. tf-idf weighting
 Outline for today Information Retrieval Efficient Scoring and Ranking Recap on ranked retrieval Jörg Tiedemann jorg.tiedemann@lingfil.uu.se Department of Linguistics and Philology Uppsala University Efficient
Outline for today Information Retrieval Efficient Scoring and Ranking Recap on ranked retrieval Jörg Tiedemann jorg.tiedemann@lingfil.uu.se Department of Linguistics and Philology Uppsala University Efficient
Modern Information Retrieval
 Modern Information Retrieval Chapter 3 Modeling Introduction to IR Models Basic Concepts The Boolean Model Term Weighting The Vector Model Probabilistic Model Retrieval Evaluation, Modern Information Retrieval,
Modern Information Retrieval Chapter 3 Modeling Introduction to IR Models Basic Concepts The Boolean Model Term Weighting The Vector Model Probabilistic Model Retrieval Evaluation, Modern Information Retrieval,
Generative Models for Discrete Data
 Generative Models for Discrete Data ddebarr@uw.edu 2016-04-21 Agenda Bayesian Concept Learning Beta-Binomial Model Dirichlet-Multinomial Model Naïve Bayes Classifiers Bayesian Concept Learning Numbers
Generative Models for Discrete Data ddebarr@uw.edu 2016-04-21 Agenda Bayesian Concept Learning Beta-Binomial Model Dirichlet-Multinomial Model Naïve Bayes Classifiers Bayesian Concept Learning Numbers
Evaluation Metrics. Jaime Arguello INLS 509: Information Retrieval March 25, Monday, March 25, 13
 Evaluation Metrics Jaime Arguello INLS 509: Information Retrieval jarguell@email.unc.edu March 25, 2013 1 Batch Evaluation evaluation metrics At this point, we have a set of queries, with identified relevant
Evaluation Metrics Jaime Arguello INLS 509: Information Retrieval jarguell@email.unc.edu March 25, 2013 1 Batch Evaluation evaluation metrics At this point, we have a set of queries, with identified relevant
Outline. Binomial, Multinomial, Normal, Beta, Dirichlet. Posterior mean, MAP, credible interval, posterior distribution
 Outline A short review on Bayesian analysis. Binomial, Multinomial, Normal, Beta, Dirichlet Posterior mean, MAP, credible interval, posterior distribution Gibbs sampling Revisit the Gaussian mixture model
Outline A short review on Bayesian analysis. Binomial, Multinomial, Normal, Beta, Dirichlet Posterior mean, MAP, credible interval, posterior distribution Gibbs sampling Revisit the Gaussian mixture model
Generalized Inverse Document Frequency
 Generalized Inverse Document Frequency Donald Metzler metzler@yahoo-inc.com Yahoo! Research 2821 Mission College Blvd. Santa Clara, CA 95054 ABSTRACT Inverse document frequency (IDF) is one of the most
Generalized Inverse Document Frequency Donald Metzler metzler@yahoo-inc.com Yahoo! Research 2821 Mission College Blvd. Santa Clara, CA 95054 ABSTRACT Inverse document frequency (IDF) is one of the most
Comparing Relevance Feedback Techniques on German News Articles
 B. Mitschang et al. (Hrsg.): BTW 2017 Workshopband, Lecture Notes in Informatics (LNI), Gesellschaft für Informatik, Bonn 2017 301 Comparing Relevance Feedback Techniques on German News Articles Julia
B. Mitschang et al. (Hrsg.): BTW 2017 Workshopband, Lecture Notes in Informatics (LNI), Gesellschaft für Informatik, Bonn 2017 301 Comparing Relevance Feedback Techniques on German News Articles Julia
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
Knowledge Discovery in Data: Overview. Naïve Bayesian Classification. .. Spring 2009 CSC 466: Knowledge Discovery from Data Alexander Dekhtyar..
 Spring 2009 CSC 466: Knowledge Discovery from Data Alexander Dekhtyar Knowledge Discovery in Data: Naïve Bayes Overview Naïve Bayes methodology refers to a probabilistic approach to information discovery
Spring 2009 CSC 466: Knowledge Discovery from Data Alexander Dekhtyar Knowledge Discovery in Data: Naïve Bayes Overview Naïve Bayes methodology refers to a probabilistic approach to information discovery
Gaussian Models
 Gaussian Models ddebarr@uw.edu 2016-04-28 Agenda Introduction Gaussian Discriminant Analysis Inference Linear Gaussian Systems The Wishart Distribution Inferring Parameters Introduction Gaussian Density
Gaussian Models ddebarr@uw.edu 2016-04-28 Agenda Introduction Gaussian Discriminant Analysis Inference Linear Gaussian Systems The Wishart Distribution Inferring Parameters Introduction Gaussian Density
Information Retrieval and Web Search
 Information Retrieval and Web Search IR models: Vector Space Model IR Models Set Theoretic Classic Models Fuzzy Extended Boolean U s e r T a s k Retrieval: Adhoc Filtering Brosing boolean vector probabilistic
Information Retrieval and Web Search IR models: Vector Space Model IR Models Set Theoretic Classic Models Fuzzy Extended Boolean U s e r T a s k Retrieval: Adhoc Filtering Brosing boolean vector probabilistic
Some slides from Carlos Guestrin, Luke Zettlemoyer & K Gajos 2
 Logistics CSE 446: Point Estimation Winter 2012 PS2 out shortly Dan Weld Some slides from Carlos Guestrin, Luke Zettlemoyer & K Gajos 2 Last Time Random variables, distributions Marginal, joint & conditional
Logistics CSE 446: Point Estimation Winter 2012 PS2 out shortly Dan Weld Some slides from Carlos Guestrin, Luke Zettlemoyer & K Gajos 2 Last Time Random variables, distributions Marginal, joint & conditional
Vector Space Model. Yufei Tao KAIST. March 5, Y. Tao, March 5, 2013 Vector Space Model
 Vector Space Model Yufei Tao KAIST March 5, 2013 In this lecture, we will study a problem that is (very) fundamental in information retrieval, and must be tackled by all search engines. Let S be a set
Vector Space Model Yufei Tao KAIST March 5, 2013 In this lecture, we will study a problem that is (very) fundamental in information retrieval, and must be tackled by all search engines. Let S be a set
COMP 551 Applied Machine Learning Lecture 19: Bayesian Inference
 COMP 551 Applied Machine Learning Lecture 19: Bayesian Inference Associate Instructor: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551 Unless otherwise noted, all material posted
COMP 551 Applied Machine Learning Lecture 19: Bayesian Inference Associate Instructor: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551 Unless otherwise noted, all material posted
Ranked IR. Lecture Objectives. Text Technologies for Data Science INFR Learn about Ranked IR. Implement: 10/10/2018. Instructor: Walid Magdy
 Text Technologies for Data Science INFR11145 Ranked IR Instructor: Walid Magdy 10-Oct-2018 Lecture Objectives Learn about Ranked IR TFIDF VSM SMART notation Implement: TFIDF 2 1 Boolean Retrieval Thus
Text Technologies for Data Science INFR11145 Ranked IR Instructor: Walid Magdy 10-Oct-2018 Lecture Objectives Learn about Ranked IR TFIDF VSM SMART notation Implement: TFIDF 2 1 Boolean Retrieval Thus
COMP 551 Applied Machine Learning Lecture 5: Generative models for linear classification
 COMP 55 Applied Machine Learning Lecture 5: Generative models for linear classification Instructor: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp55 Unless otherwise noted, all material
COMP 55 Applied Machine Learning Lecture 5: Generative models for linear classification Instructor: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp55 Unless otherwise noted, all material
A REVIEW ARTICLE ON NAIVE BAYES CLASSIFIER WITH VARIOUS SMOOTHING TECHNIQUES
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 10, October 2014,
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 10, October 2014,
Behavioral Data Mining. Lecture 2
 Behavioral Data Mining Lecture 2 Autonomy Corp Bayes Theorem Bayes Theorem P(A B) = probability of A given that B is true. P(A B) = P(B A)P(A) P(B) In practice we are most interested in dealing with events
Behavioral Data Mining Lecture 2 Autonomy Corp Bayes Theorem Bayes Theorem P(A B) = probability of A given that B is true. P(A B) = P(B A)P(A) P(B) In practice we are most interested in dealing with events
Bayesian Learning. HT2015: SC4 Statistical Data Mining and Machine Learning. Maximum Likelihood Principle. The Bayesian Learning Framework
 HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
3. Basics of Information Retrieval
 Text Analysis and Retrieval 3. Basics of Information Retrieval Prof. Bojana Dalbelo Bašić Assoc. Prof. Jan Šnajder With contributions from dr. sc. Goran Glavaš Mladen Karan, mag. ing. University of Zagreb
Text Analysis and Retrieval 3. Basics of Information Retrieval Prof. Bojana Dalbelo Bašić Assoc. Prof. Jan Šnajder With contributions from dr. sc. Goran Glavaš Mladen Karan, mag. ing. University of Zagreb
Generative Clustering, Topic Modeling, & Bayesian Inference
 Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Information Retrieval
 Information Retrieval Online Evaluation Ilya Markov i.markov@uva.nl University of Amsterdam Ilya Markov i.markov@uva.nl Information Retrieval 1 Course overview Offline Data Acquisition Data Processing
Information Retrieval Online Evaluation Ilya Markov i.markov@uva.nl University of Amsterdam Ilya Markov i.markov@uva.nl Information Retrieval 1 Course overview Offline Data Acquisition Data Processing
Information Retrieval
 Introduction to Information CS276: Information and Web Search Christopher Manning and Pandu Nayak Lecture 15: Learning to Rank Sec. 15.4 Machine learning for IR ranking? We ve looked at methods for ranking
Introduction to Information CS276: Information and Web Search Christopher Manning and Pandu Nayak Lecture 15: Learning to Rank Sec. 15.4 Machine learning for IR ranking? We ve looked at methods for ranking
INFO 4300 / CS4300 Information Retrieval. slides adapted from Hinrich Schütze s, linked from
 INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 26/26: Feature Selection and Exam Overview Paul Ginsparg Cornell University,
INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 26/26: Feature Selection and Exam Overview Paul Ginsparg Cornell University,
Term Weighting and Vector Space Model. Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze
 Term Weighting and Vector Space Model Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze 1 Ranked retrieval Thus far, our queries have all been Boolean. Documents either
Term Weighting and Vector Space Model Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze 1 Ranked retrieval Thus far, our queries have all been Boolean. Documents either
Behavioral Data Mining. Lecture 3 Naïve Bayes Classifier and Generalized Linear Models
 Behavioral Data Mining Lecture 3 Naïve Bayes Classifier and Generalized Linear Models Outline Naïve Bayes Classifier Regularization in Linear Regression Generalized Linear Models Assignment Tips: Matrix
Behavioral Data Mining Lecture 3 Naïve Bayes Classifier and Generalized Linear Models Outline Naïve Bayes Classifier Regularization in Linear Regression Generalized Linear Models Assignment Tips: Matrix
A Unified Posterior Regularized Topic Model with Maximum Margin for Learning-to-Rank
 A Unified Posterior Regularized Topic Model with Maximum Margin for Learning-to-Rank Shoaib Jameel Shoaib Jameel 1, Wai Lam 2, Steven Schockaert 1, and Lidong Bing 3 1 School of Computer Science and Informatics,
A Unified Posterior Regularized Topic Model with Maximum Margin for Learning-to-Rank Shoaib Jameel Shoaib Jameel 1, Wai Lam 2, Steven Schockaert 1, and Lidong Bing 3 1 School of Computer Science and Informatics,
Why Language Models and Inverse Document Frequency for Information Retrieval?
 Why Language Models and Inverse Document Frequency for Information Retrieval? Catarina Moreira, Andreas Wichert Instituto Superior Técnico, INESC-ID Av. Professor Cavaco Silva, 2744-016 Porto Salvo, Portugal
Why Language Models and Inverse Document Frequency for Information Retrieval? Catarina Moreira, Andreas Wichert Instituto Superior Técnico, INESC-ID Av. Professor Cavaco Silva, 2744-016 Porto Salvo, Portugal
Recap: Language models. Foundations of Natural Language Processing Lecture 4 Language Models: Evaluation and Smoothing. Two types of evaluation in NLP
 Recap: Language models Foundations of atural Language Processing Lecture 4 Language Models: Evaluation and Smoothing Alex Lascarides (Slides based on those from Alex Lascarides, Sharon Goldwater and Philipp
Recap: Language models Foundations of atural Language Processing Lecture 4 Language Models: Evaluation and Smoothing Alex Lascarides (Slides based on those from Alex Lascarides, Sharon Goldwater and Philipp
Text mining and natural language analysis. Jefrey Lijffijt
 Text mining and natural language analysis Jefrey Lijffijt PART I: Introduction to Text Mining Why text mining The amount of text published on paper, on the web, and even within companies is inconceivably
Text mining and natural language analysis Jefrey Lijffijt PART I: Introduction to Text Mining Why text mining The amount of text published on paper, on the web, and even within companies is inconceivably
Information Retrieval and Topic Models. Mausam (Based on slides of W. Arms, Dan Jurafsky, Thomas Hofmann, Ata Kaban, Chris Manning, Melanie Martin)
") Information Retrieval and Topic Models Mausam (Based on slides of W. Arms, Dan Jurafsky, Thomas Hofmann, Ata Kaban, Chris Manning, Melanie Martin) Sec. 1.1 Unstructured data in 1620 Which plays of Shakespeare
Information Retrieval and Topic Models Mausam (Based on slides of W. Arms, Dan Jurafsky, Thomas Hofmann, Ata Kaban, Chris Manning, Melanie Martin) Sec. 1.1 Unstructured data in 1620 Which plays of Shakespeare
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University September 22, 2011 Today: MLE and MAP Bayes Classifiers Naïve Bayes Readings: Mitchell: Naïve Bayes and Logistic
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University September 22, 2011 Today: MLE and MAP Bayes Classifiers Naïve Bayes Readings: Mitchell: Naïve Bayes and Logistic
Natural Language Processing. Topics in Information Retrieval. Updated 5/10
 Natural Language Processing Topics in Information Retrieval Updated 5/10 Outline Introduction to IR Design features of IR systems Evaluation measures The vector space model Latent semantic indexing Background
Natural Language Processing Topics in Information Retrieval Updated 5/10 Outline Introduction to IR Design features of IR systems Evaluation measures The vector space model Latent semantic indexing Background
Non-Boolean models of retrieval: Agenda
 Non-Boolean models of retrieval: Agenda Review of Boolean model and TF/IDF Simple extensions thereof Vector model Language Model-based retrieval Matrix decomposition methods Non-Boolean models of retrieval:
Non-Boolean models of retrieval: Agenda Review of Boolean model and TF/IDF Simple extensions thereof Vector model Language Model-based retrieval Matrix decomposition methods Non-Boolean models of retrieval:
Language as a Stochastic Process
 CS769 Spring 2010 Advanced Natural Language Processing Language as a Stochastic Process Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu 1 Basic Statistics for NLP Pick an arbitrary letter x at random from any
CS769 Spring 2010 Advanced Natural Language Processing Language as a Stochastic Process Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu 1 Basic Statistics for NLP Pick an arbitrary letter x at random from any
Information Retrieval
 Introduction to Information Retrieval CS276: Information Retrieval and Web Search Christopher Manning, Pandu Nayak, and Prabhakar Raghavan Lecture 14: Learning to Rank Sec. 15.4 Machine learning for IR
Introduction to Information Retrieval CS276: Information Retrieval and Web Search Christopher Manning, Pandu Nayak, and Prabhakar Raghavan Lecture 14: Learning to Rank Sec. 15.4 Machine learning for IR