Constrained optimization
|
|
|
- Norma Strickland
- 5 years ago
- Views:
Transcription

1 Constrained optimization DS-GA 1013 / MATH-GA 2824 Optimization-based Data Analysis Carlos Fernandez-Granda
2 Compressed sensing Convex constrained problems Analyzing optimization-based methods
 2D DFT (log.")
3 Magnetic resonance imaging 2D DFT (magnitude) 2D DFT (log. of magnitude)
4 Magnetic resonance imaging Data: Samples from spectrum Problem: Sampling is time consuming (annoying, kids move... ) Images are compressible (sparse in wavelet basis) Can we recover compressible signals from less data?

5 2D wavelet transform

6 2D wavelet transform


7 Full DFT matrix

8 Full DFT matrix
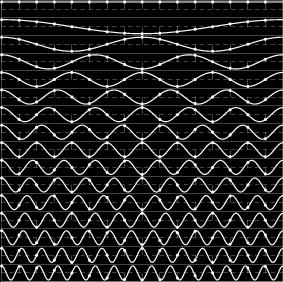
9 Regular subsampling
10 Regular subsampling
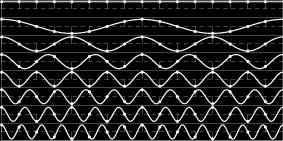
11 Random subsampling
12 Random subsampling

13 Toy example
14 Regular subsampling
15 Random subsampling
16 Linear inverse problems Linear inverse problem A x = y Linear measurements, A R m n y[i] = A i:, x, 1 i n, Aim: Recover data signal x R m from data y R n We need n m, otherwise the problem is underdetermined If n < m there are infinite solutions x + w where w null (A)
17 Sparse recovery Aim: Recover sparse x from linear measurements When is the problem well posed? A x = y There shouldn t be two sparse vectors x 1 and x 2 such that A x 1 = A x 2
18 Spark The spark of a matrix is the smallest subset of columns that is linearly dependent
19 Spark The spark of a matrix is the smallest subset of columns that is linearly dependent Let y := A x, where A R m n, y R n and x R m is a sparse vector with s nonzero entries The vector x is the only vector with sparsity s consistent with the data, i.e. it is the solution of for any choice of x if and only if min x x 0 subject to A x = y spark (A) > 2s
20 Proof Equivalent statements For any x, x is the only vector with sparsity s consistent with the data
21 Proof Equivalent statements For any x, x is the only vector with sparsity s consistent with the data For any pair of s-sparse vectors x 1 and x 2 A ( x 1 x 2 ) 0
22 Proof Equivalent statements For any x, x is the only vector with sparsity s consistent with the data For any pair of s-sparse vectors x 1 and x 2 A ( x 1 x 2 ) 0 For any pair of subsets of s indices T 1 and T 2 A T1 T 2 α 0 for any α R T 1 T 2
23 Proof Equivalent statements For any x, x is the only vector with sparsity s consistent with the data For any pair of s-sparse vectors x 1 and x 2 A ( x 1 x 2 ) 0 For any pair of subsets of s indices T 1 and T 2 A T1 T 2 α 0 for any α R T 1 T 2 All submatrices with at most 2s columns have no nonzero vectors in their null space
24 Proof Equivalent statements For any x, x is the only vector with sparsity s consistent with the data For any pair of s-sparse vectors x 1 and x 2 A ( x 1 x 2 ) 0 For any pair of subsets of s indices T 1 and T 2 A T1 T 2 α 0 for any α R T 1 T 2 All submatrices with at most 2s columns have no nonzero vectors in their null space All submatrices with at most 2s columns are full rank
25 Restricted-isometry property Robust version of spark If two s-sparse vectors x 1, x 2 are far, then A x 1, A x 2 should be far The linear operator should preserve distances (be an isometry) when restricted to act upon sparse vectors
26 Restricted-isometry property A satisfies the restricted isometry property (RIP) with constant κ s if for any s-sparse vector x (1 κ s ) x 2 A x 2 (1 + κ s ) x 2 If A satisfies the RIP for a sparsity level 2s then for any s-sparse x 1, x 2 y 2 y 1 2
27 Restricted-isometry property A satisfies the restricted isometry property (RIP) with constant κ s if for any s-sparse vector x (1 κ s ) x 2 A x 2 (1 + κ s ) x 2 If A satisfies the RIP for a sparsity level 2s then for any s-sparse x 1, x 2 y 2 y 1 2 = A ( x 1 x 2 ) (1 κ 2s ) x 2 x 1 2
28 Regular subsampling
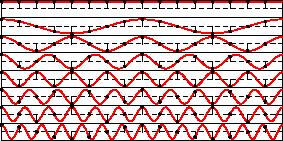
29 Regular subsampling
30 Correlation with column Correlation
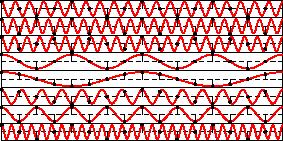
31 Random subsampling
32 Random subsampling
33 Correlation with column Correlation
34 Restricted-isometry property Deterministic matrices tend to not satisfy the RIP It is NP-hard to check if spark or RIP hold Random matrices satisfy RIP with high probability We prove it for Gaussian iid matrices, ideas in proof for random Fourier matrices are similar
35 Restricted-isometry property for Gaussian matrices Let A R m n be a random matrix with iid standard Gaussian entries 1 m A satisfies the RIP for a constant κ s with probability 1 C 2 n m C 1s κ 2 s for two fixed constants C 1, C 2 > 0 ( n ) log s as long as
36 Proof For a fixed support T of size s bounds follow from bounds on singular values of Gaussian matrices
37 Singular values of m s matrix, s = 100 σi m m/s i
38 Singular values of m s matrix, s = 1000 σi m m/s ,000 i
39 Proof For a fixed submatrix the singular values are bounded by m (1 κs ) σ s σ 1 m (1 + κ s ) with probability at least ( ) 12 s ( ) 1 2 exp mκ2 s 32 κ s For any vector x with support T 1 κs x 2 1 m A x κ s x 2
40 Union bound For any events S 1, S 2,..., S n in a probability space P ( i S i ) n P (S i ). i=1
41 Proof Number of different supports of size s
42 Proof Number of different supports of size s ( ) n ( en s s ) s
43 Proof Number of different supports of size s ( ) n ( en s s ) s By the union bound 1 κs x 2 1 m A x κ s x 2 holds for any s-sparse vector x with probability at least ( en ) ( ) s 12 s ( ) 1 2 exp mκ2 s s 32 κ s ( = 1 exp log 2 + s + s log 1 C 2 n as long as ( n s ) + s log m C 1s κ 2 s ( 12 κ s ( n ) log s ) mκ2 s 2 )
44 Sparse recovery via l 1 -norm minimization l 0 - norm" minimization is intractable (As usual) we can minimize l 1 norm instead, estimate x l1 to is the solution min x x 1 subject to A x = y
45 Minimum l 2 -norm solution (regular subsampling) 4 True Signal Minimum L2 Solution
46 Minimum l 1 -norm solution (regular subsampling) 4 True Signal Minimum L1 Solution
47 Minimum l 2 -norm solution (random subsampling) 4 True Signal Minimum L2 Solution
48 Minimum l 1 -norm solution (random subsampling) 4 True Signal Minimum L1 Solution
49 Geometric intuition l 2 norm l 1 norm
50 Sparse recovery via l 1 -norm minimization If the signal is sparse in a transform domain then min x c 1 subject to AW c = y If we want to recover the original c then AW should satisfy the RIP
51 Sparse recovery via l 1 -norm minimization If the signal is sparse in a transform domain then min x c 1 subject to AW c = y If we want to recover the original c then AW should satisfy the RIP However, we might be fine with any c such that A c = x

52 Regular subsampling
53 Minimum l 2 -norm solution (regular subsampling)

54 Minimum l 1 -norm solution (regular subsampling)

55 Random subsampling

56 Minimum l 2 -norm solution (random subsampling)

57 Minimum l 1 -norm solution (random subsampling)
58 Compressed sensing Convex constrained problems Analyzing optimization-based methods
59 Convex sets A convex set S is any set such that for any x, y S and θ (0, 1) θ x + (1 θ) y S The intersection of convex sets is convex
60 Convex vs nonconvex Nonconvex Convex
61 Epigraph epi (f ) f A function is convex if and only if its epigraph is convex
62 Projection onto convex set The projection of any vector x onto a non-empty closed convex set S exists and is unique P S ( x) := arg min y S x y 2
63 Proof Assume there are two distinct projections y 1 y 2 Consider y belongs to S (why?) y := y 1 + y 2 2
64 Proof x y, y 1 y = x y 1 + y 2 2 x y1 = 2, y 1 y 1 + y x y 2, x y 1 x y
65 Proof x y, y 1 y = x y 1 + y 2, y 1 y 1 + y x y1 = + x y 2, x y 1 x y = 1 ( x y x y 2 2) 4 = 0
66 Proof x y, y 1 y = x y 1 + y 2, y 1 y 1 + y x y1 = + x y 2, x y 1 x y = 1 ( x y x y 2 2) 4 By Pythagoras theorem = 0 x y 1 2 2
67 Proof x y, y 1 y = x y 1 + y 2, y 1 y 1 + y x y1 = + x y 2, x y 1 x y = 1 ( x y x y 2 2) 4 By Pythagoras theorem = 0 x y = x y y 1 y 2 2
68 Proof x y, y 1 y = x y 1 + y 2, y 1 y 1 + y x y1 = + x y 2, x y 1 x y = 1 ( x y x y 2 2) 4 By Pythagoras theorem = 0 x y = x y y 1 y 2 2 = x y y 1 y
69 Proof x y, y 1 y = x y 1 + y 2, y 1 y 1 + y x y1 = + x y 2, x y 1 x y = 1 ( x y x y 2 2) 4 By Pythagoras theorem = 0 x y = x y y 1 y 2 2 = x y y 1 y > x y 2 2 2
70 Convex combination Given n vectors x 1, x 2,..., x n R n, x := n θ i x i i=1 is a convex combination of x 1, x 2,..., x n if θ i 0, 1 i n n θ i = 1 i=1
71 Convex hull The convex hull of S is the set of convex combinations of points in S The l 1 -norm ball is the convex hull of the intersection between the l 0 norm" ball and the l -norm ball
72 l 1 -norm ball
73 B l1 C (B l0 B l ) Let x B l1 Set θ i := x[i], θ 0 = 1 n i=1 θ i n i=0 θ i = 1 by construction, θ i 0 and n+1 θ 0 = 1 i=1 θ i = 1 x 1 0 because x B l1
74 B l1 C (B l0 B l ) Let x B l1 Set θ i := x[i], θ 0 = 1 n i=1 θ i n i=0 θ i = 1 by construction, θ i 0 and n+1 θ 0 = 1 i=1 θ i = 1 x 1 0 because x B l1 x B l0 B l because x = n θ i sign ( x[i]) e i + θ 0 0 i=1
75 C (B l0 B l ) B l1 Let x C (B l0 B l ), then x = m θ i y i i=1
76 C (B l0 B l ) B l1 Let x C (B l0 B l ), then x = m θ i y i i=1 x 1
77 C (B l0 B l ) B l1 Let x C (B l0 B l ), then x = m θ i y i i=1 x 1 m θ i y i 1 i=1 by the Triangle inequality
78 C (B l0 B l ) B l1 Let x C (B l0 B l ), then x = m θ i y i i=1 x 1 m θ i y i 1 i=1 m θ i y i i=1 by the Triangle inequality y i only has one nonzero entry
79 C (B l0 B l ) B l1 Let x C (B l0 B l ), then x = m θ i y i i=1 x 1 m θ i y i 1 i=1 m θ i y i i=1 m i=1 θ i by the Triangle inequality y i only has one nonzero entry
80 C (B l0 B l ) B l1 Let x C (B l0 B l ), then x = m θ i y i i=1 x 1 1 m θ i y i 1 i=1 m θ i y i i=1 m i=1 θ i by the Triangle inequality y i only has one nonzero entry
81 Convex optimization problem f 0, f 1,..., f m, h 1,..., h p : R n R minimize f 0 ( x) subject to f i ( x) 0, 1 i m, h i ( x) = 0, 1 i p,
82 Definitions A feasible vector is a vector that satisfies all the constraints A solution is any vector x such that for all feasible vectors x f 0 ( x) f 0 ( x ) If a solution exists f ( x ) is the optimal value or optimum of the problem
83 Convex optimization problem The optimization problem is convex if f 0 is convex f 1,..., f m are convex h 1,..., h p are affine, i.e. h i ( x) = a i T x + b i for some a i R n and b i R
84 Linear program minimize subject to a T x c T i x d i, 1 i m A x = b
85 l 1 -norm minimization as an LP The optimization problem minimize x 1 subject to A x = b can be recast as the LP minimize subject to m t[i] i=1 t[i] e T i x t[i] e T i x A x = b
86 Proof Solution to l 1 -norm min. problem: x l 1 Solution to linear program: ( x lp, t lp) Set t l 1 [i] := x l 1 [i] ( x l 1, t l ) 1 is feasible for linear program x l 1 = 1 m t l 1 [i] i=1
87 Proof Solution to l 1 -norm min. problem: x l 1 Solution to linear program: ( x lp, t lp) Set t l 1 [i] := x l 1 [i] ( x l 1, t l ) 1 is feasible for linear program x l 1 = 1 m t l 1 [i] i=1 m t lp [i] i=1 by optimality of t lp
88 Proof Solution to l 1 -norm min. problem: x l 1 Solution to linear program: ( x lp, t lp) Set t l 1 [i] := x l 1 [i] ( x l 1, t l ) 1 is feasible for linear program x l 1 m = t l 1 [i] 1 i=1 m t lp [i] i=1 x lp 1 by optimality of t lp
89 Proof Solution to l 1 -norm min. problem: x l 1 Solution to linear program: ( x lp, t lp) Set t l 1 [i] := x l 1 [i] ( x l 1, t l ) 1 is feasible for linear program x l 1 m = t l 1 [i] 1 i=1 m t lp [i] i=1 x lp 1 by optimality of t lp x lp is a solution to the l 1 -norm min. problem
90 Proof Set t l 1 [i] := x l 1 [i] m i=1 t l 1 i = x l 1 1
91 Proof Set t l 1 [i] := x l 1 [i] m i=1 t l 1 i = x l 1 1 x lp 1 by optimality of x l 1
92 Proof Set t l 1 [i] := x l 1 [i] m i=1 t l 1 i = x l 1 1 x lp 1 by optimality of x l 1 m t lp [i] i=1
93 Proof Set t l 1 [i] := x l 1 [i] m i=1 t l 1 i = x l 1 1 x lp 1 by optimality of x l 1 m t lp [i] i=1 ( x l 1, t l ) 1 is a solution to the linear problem
94 Quadratic program For a positive semidefinite matrix Q R n n minimize subject to x T Q x + a T x c T i x d i, 1 i m, A x = b
95 l 1 -norm regularized least squares as a QP The optimization problem can be recast as the QP minimize A x y α x 1 minimize subject to x T A T A x 2 y T x + α t[i] e T i x t[i] e T i x n t[i] i=1
96 Lagrangian The Lagrangian of a canonical optimization problem is m p L ( x, α, ν) := f 0 ( x) + α[i] f i ( x) + ν[j] h j ( x), i=1 j=1 α R m, ν R p are called Lagrange multipliers or dual variables If x is feasible and α[i] 0 for 1 i m L ( x, α, ν) f 0 ( x)
97 Lagrange dual function The Lagrange dual function of the problem is l ( α, ν) := inf x R n f 0 ( x) + m α[i]f i ( x) + i=1 Let p be an optimum of the optimization problem as long as α[i] 0 for 1 i n l ( α, ν) p p ν[j]h j ( x) j=1
98 Dual problem The dual problem of the (primal) optimization problem is maximize l ( α, ν) subject to α[i] 0, 1 i m. The dual problem is always convex, even if the primal isn t!
99 Maximum/supremum of convex functions Pointwise maximum of m convex functions f 1,..., f m is convex f max (x) := max 1 i m f i (x) Pointwise supremum of a family of convex functions indexed by a set I is convex f sup (x) := sup f i (x) i I
100 Proof For any 0 θ 1 and any x, y R, f sup (θ x + (1 θ) y) = sup f i (θ x + (1 θ) y) i I
101 Proof For any 0 θ 1 and any x, y R, f sup (θ x + (1 θ) y) = sup f i (θ x + (1 θ) y) i I sup θf i ( x) + (1 θ) f i ( y) i I by convexity of the f i
102 Proof For any 0 θ 1 and any x, y R, f sup (θ x + (1 θ) y) = sup f i (θ x + (1 θ) y) i I sup θf i ( x) + (1 θ) f i ( y) i I θ sup i I f i ( x) + (1 θ) sup f j ( y) j I by convexity of the f i
103 Proof For any 0 θ 1 and any x, y R, f sup (θ x + (1 θ) y) = sup f i (θ x + (1 θ) y) i I sup θf i ( x) + (1 θ) f i ( y) i I θ sup i I f i ( x) + (1 θ) sup f j ( y) j I = θf sup ( x) + (1 θ) f sup ( y) by convexity of the f i
104 Weak duality If p is a primal optimum and d a dual optimum d p
105 Strong duality For convex problems d = p under very weak conditions LPs: The primal optimum is finite General convex programs (Slater s condition): There exists a point that is strictly feasible f i ( x) < 0 1 i m
106 l 1 -norm minimization The dual problem of min x x 1 subject to A x = y is max y T ν ν subject to A T ν 1
107 Proof Lagrangian L ( x, ν) = x 1 + ν T ( y A x) Lagrange dual function l ( α, ν) := inf x R n x 1 (AT ν) T x + ν T y
108 Proof Lagrangian L ( x, ν) = x 1 + ν T ( y A x) Lagrange dual function If A T ν[i] > 1? l ( α, ν) := inf x R n x 1 (AT ν) T x + ν T y
109 Proof Lagrangian L ( x, ν) = x 1 + ν T ( y A x) Lagrange dual function l ( α, ν) := inf x R n x 1 (AT ν) T x + ν T y If A T ν[i] > 1? We can set x[i] and l ( α, ν)
110 Proof Lagrangian L ( x, ν) = x 1 + ν T ( y A x) Lagrange dual function l ( α, ν) := inf x R n x 1 (AT ν) T x + ν T y If A T ν[i] > 1? We can set x[i] and l ( α, ν) If A T ν 1? (A T ν) T x
111 Proof Lagrangian L ( x, ν) = x 1 + ν T ( y A x) Lagrange dual function l ( α, ν) := inf x R n x 1 (AT ν) T x + ν T y If A T ν[i] > 1? We can set x[i] and l ( α, ν) If A T ν 1? (A T ν) T A x x T 1 ν x 1
112 Proof Lagrangian L ( x, ν) = x 1 + ν T ( y A x) Lagrange dual function l ( α, ν) := inf x R n x 1 (AT ν) T x + ν T y If A T ν[i] > 1? We can set x[i] and l ( α, ν) If A T ν 1? so l ( α, ν) = ν T y (A T ν) T A x x T 1 ν x 1
113 Strong duality The solution ν to satisfies max y T ν ν subject to A T ν 1 (A T ν )[i]= sign( x [i]) for all x [i] 0 for all solutions x to the primal problem min x x 1 subject to A x = y
114 Dual solution True Signal Sign Minimum L1 Dual Solution
115 Proof By strong duality By Hölder s inequality x 1 = y T ν = (A x ) T ν = ( x ) T (A T ν ) m = (A T ν )[i] x [i] i=1 x 1 m (A T ν )[i] x [i] i=1 with equality if and only if (A T ν )[i] = sign( x [i]) for all x [i] 0
116 Another algorithm for sparse recovery Aim: Find nonzero locations of a sparse vector x from y = A x Insight: We have access to inner products of x and A T w for any w y T w
117 Another algorithm for sparse recovery Aim: Find nonzero locations of a sparse vector x from y = A x Insight: We have access to inner products of x and A T w for any w y T w = (A x) T w
118 Another algorithm for sparse recovery Aim: Find nonzero locations of a sparse vector x from y = A x Insight: We have access to inner products of x and A T w for any w y T w = (A x) T w = x T (A T w)
119 Another algorithm for sparse recovery Aim: Find nonzero locations of a sparse vector x from y = A x Insight: We have access to inner products of x and A T w for any w y T w = (A x) T w = x T (A T w) Idea: Maximize A T w, bounding magnitude of entries by 1
120 Another algorithm for sparse recovery Aim: Find nonzero locations of a sparse vector x from y = A x Insight: We have access to inner products of x and A T w for any w y T w = (A x) T w = x T (A T w) Idea: Maximize A T w, bounding magnitude of entries by 1 Entries where x is nonzero should saturate to 1 or -1
121 Compressed sensing Convex constrained problems Analyzing optimization-based methods
122 Analyzing optimization-based methods Best case scenario: Primal solution has closed form Otherwise: Use dual solution to characterize primal solution
123 Minimum l 2 -norm solution Let A R m n be a full rank matrix such that m < n For any y R n the solution to the optimization problem is arg min x x 2 subject to A x = y. x := VS 1 U T y where A = USV T is the SVD of A = A T ( A T A) 1 y
124 Proof x = P row(a) x + P row(a) x Since A is full rank V, P row(a) x = V c for some vector c R n A x = AP row(a) x
125 Proof x = P row(a) x + P row(a) x Since A is full rank V, P row(a) x = V c for some vector c R n A x = AP row(a) x = USV T V c
126 Proof x = P row(a) x + P row(a) x Since A is full rank V, P row(a) x = V c for some vector c R n A x = AP row(a) x = USV T V c = US c
127 Proof x = P row(a) x + P row(a) x Since A is full rank V, P row(a) x = V c for some vector c R n A x = AP row(a) x = USV T V c = US c A x = y is equivalent to US c = y and c = S 1 U T y
128 Proof For all feasible vectors x P row(a) x = VS 1 U T y By Pythagoras theorem, minimizing x 2 is equivalent to minimizing x 2 2 = Prow(A) x Prow(A) x 2 2
129 Regular subsampling
130 Minimum l 2 -norm solution (regular subsampling) 4 True Signal Minimum L2 Solution
131 Regular subsampling A := 1 2 [ Fm/2 F m/2 ] F m/2 F m/2 = I F m/2 F m/2 = I x := [ xup x down ]
132 Regular subsampling x l2 = arg min A x= y x 2
133 Regular subsampling x l2 = arg min A x= y x 2 = A T ( A T A ) 1 y
134 Regular subsampling x l2 = arg min A x= y x 2 = A T ( A T A ) 1 y [ ] ( [ ]) 1 = 1 F m/2 1 [ ] 1 F 2 Fm/2 Fm/2 F m/2 2 m/2 1 [ 2 2 Fm/2 Fm/2 ] [ ] x F up m/2 x down
135 Regular subsampling x l2 = arg min A x= y x 2 = A T ( A T A ) 1 y [ ] ( [ ]) 1 = 1 F m/2 1 [ ] 1 F 2 Fm/2 Fm/2 F m/2 2 m/2 1 [ 2 2 Fm/2 Fm/2 [ ] ) 1 F m/2 Fm/2 + F m/2fm/2 ( ) Fm/2 x up + F m/2 x down [ ] = 1 F (1 m/2 2 2 F m/2 ] [ ] x F up m/2 x down
136 Regular subsampling x l2 = arg min A x= y x 2 = A T ( A T A ) 1 y [ ] ( [ ]) 1 = 1 F m/2 1 [ ] 1 F 2 Fm/2 Fm/2 F m/2 2 m/2 1 [ 2 2 Fm/2 Fm/2 [ ] ) 1 F m/2 Fm/2 + F m/2fm/2 ( ) Fm/2 x up + F m/2 x down [ ] = 1 F (1 m/2 2 Fm/2 2 [ ] = 1 F m/2 I 1 ( ) F m/2 x up + F m/2 x down 2 F m/2 ] [ ] x F up m/2 x down
137 Regular subsampling x l2 = arg min A x= y x 2 = A T ( A T A ) 1 y [ ] ( [ ]) 1 = 1 F m/2 1 [ ] 1 F 2 Fm/2 Fm/2 F m/2 2 m/2 1 [ 2 2 Fm/2 Fm/2 [ ] ) 1 F m/2 Fm/2 + F m/2fm/2 ( ) Fm/2 x up + F m/2 x down [ ] = 1 F (1 m/2 2 Fm/2 2 [ ] = 1 F m/2 2 Fm/2 I 1 ( ) F m/2 x up + F m/2 x down [ = 1 ( )] F m/2 Fm/2 x up + F m/2 x ( down ) 2 Fm/2 x up + F m/2 x down F m/2 ] [ ] x F up m/2 x down
138 Regular subsampling x l2 = arg min A x= y x 2 = A T ( A T A ) 1 y [ ] ( [ ]) 1 = 1 F m/2 1 [ ] 1 F 2 Fm/2 Fm/2 F m/2 2 m/2 1 [ 2 2 Fm/2 Fm/2 [ ] ) 1 F m/2 Fm/2 + F m/2fm/2 ( ) Fm/2 x up + F m/2 x down [ ] = 1 F (1 m/2 2 Fm/2 2 [ ] = 1 F m/2 2 Fm/2 I 1 ( ) F m/2 x up + F m/2 x down [ = 1 ( )] F m/2 Fm/2 x up + F m/2 x ( down ) 2 Fm/2 Fm/2 x up + F m/2 x down = 1 [ ] xup + x down 2 x up + x down ] [ ] x F up m/2 x down
139 Minimum l 1 -norm solution Problem: arg min A x= y x 1 doesn t have a closed form Instead we can use a dual variable to certify optimality
140 Dual solution The solution ν to satisfies max y T ν ν subject to A T ν 1 (A T ν )[i]= sign( x [i]) for all x [i] 0 where x [i] is a solution to the primal problem min x x 1 subject to A x = y
141 Dual certificate If there exists a vector ν R n such that (A T ν)[i] = sign( x [i]) if x [i] 0 (A T ν)[i] <1 if x [i] = 0 then x is the unique solution to the primal problem min x x 1 subject to A x = y as long as the submatrix A T is full rank
142 Proof 1 ν is feasible for the dual problem, so for any primal feasible x x 1 y T ν
143 Proof 1 ν is feasible for the dual problem, so for any primal feasible x x 1 y T ν = (A x ) T ν
144 Proof 1 ν is feasible for the dual problem, so for any primal feasible x x 1 y T ν = (A x ) T ν = ( x ) T (A T ν)
145 Proof 1 ν is feasible for the dual problem, so for any primal feasible x x 1 y T ν = (A x ) T ν = ( x ) T (A T ν) = x [i] sign( x [i]) i T
146 Proof 1 ν is feasible for the dual problem, so for any primal feasible x x 1 y T ν = (A x ) T ν = ( x ) T (A T ν) = x [i] sign( x [i]) i T x must be a solution = x 1
147 Proof 2 A T ν is a subgradient of the l 1 norm at x For any other feasible vector x x 1 x 1 + (A T ν) T ( x x )
148 Proof 2 A T ν is a subgradient of the l 1 norm at x For any other feasible vector x x 1 x 1 + (A T ν) T ( x x ) = x 1 + ν T (A x A x )
149 Proof 2 A T ν is a subgradient of the l 1 norm at x For any other feasible vector x x 1 x 1 + (A T ν) T ( x x ) = x 1 + ν T (A x A x ) = x 1
150 Random subsampling
151 Minimum l 1 -norm solution (random subsampling) 4 True Signal Minimum L1 Solution
152 Exact sparse recovery via l 1 -norm minimization Assumption: There exists a signal x R m with s nonzeros such that A x = y for a random A R m n (random Fourier, Gaussian iid,... ) Exact recovery: If the number of measurements satisfies m C s log n the solution of the problem minimize x 1 subject to A x = y is the original signal with probability at least 1 1 n
153 Proof Show that dual certificate always exists We need A T T ν = sign( x T ) A T T c ν < 1 s constraints Idea: Impose A T ν = sign( x ) and minimize A T T c ν Problem: No closed-form solution How about minimizing l 2 norm?
154 Proof of exact recovery Prove that dual certificate exists for any s-sparse x Dual certificate candidate: Solution of minimize v 2 subject to A T T v = sign ( x T ) Closed-form solution ν l2 := A T ( A T T A T ) 1 sign ( x T ) A T T A T is invertible with high probability We need to prove that A T ν l2 satisfies (A T ν l2 ) T c < 1
155 Dual certificate Sign Pattern Dual Function
156 Proof of exact recovery To control (A T ν l2 ) T c, we need to bound for i T c A T i Let w := ( A T T A T ) 1 sign ( x T ) ( A T T A T ) 1 sign ( x T ) A T i w can be bounded using independence Result then follows from union bound
Lecture Notes 9: Constrained Optimization
 Optimization-based data analysis Fall 017 Lecture Notes 9: Constrained Optimization 1 Compressed sensing 1.1 Underdetermined linear inverse problems Linear inverse problems model measurements of the form
Optimization-based data analysis Fall 017 Lecture Notes 9: Constrained Optimization 1 Compressed sensing 1.1 Underdetermined linear inverse problems Linear inverse problems model measurements of the form
Lagrange duality. The Lagrangian. We consider an optimization program of the form
 Lagrange duality Another way to arrive at the KKT conditions, and one which gives us some insight on solving constrained optimization problems, is through the Lagrange dual. The dual is a maximization
Lagrange duality Another way to arrive at the KKT conditions, and one which gives us some insight on solving constrained optimization problems, is through the Lagrange dual. The dual is a maximization
Extreme Abridgment of Boyd and Vandenberghe s Convex Optimization
 Extreme Abridgment of Boyd and Vandenberghe s Convex Optimization Compiled by David Rosenberg Abstract Boyd and Vandenberghe s Convex Optimization book is very well-written and a pleasure to read. The
Extreme Abridgment of Boyd and Vandenberghe s Convex Optimization Compiled by David Rosenberg Abstract Boyd and Vandenberghe s Convex Optimization book is very well-written and a pleasure to read. The
Random projections. 1 Introduction. 2 Dimensionality reduction. Lecture notes 5 February 29, 2016
 Lecture notes 5 February 9, 016 1 Introduction Random projections Random projections are a useful tool in the analysis and processing of high-dimensional data. We will analyze two applications that use
Lecture notes 5 February 9, 016 1 Introduction Random projections Random projections are a useful tool in the analysis and processing of high-dimensional data. We will analyze two applications that use
Convex Optimization & Lagrange Duality
 Convex Optimization & Lagrange Duality Chee Wei Tan CS 8292 : Advanced Topics in Convex Optimization and its Applications Fall 2010 Outline Convex optimization Optimality condition Lagrange duality KKT
Convex Optimization & Lagrange Duality Chee Wei Tan CS 8292 : Advanced Topics in Convex Optimization and its Applications Fall 2010 Outline Convex optimization Optimality condition Lagrange duality KKT
DS-GA 1002 Lecture notes 10 November 23, Linear models
 DS-GA 2 Lecture notes November 23, 2 Linear functions Linear models A linear model encodes the assumption that two quantities are linearly related. Mathematically, this is characterized using linear functions.
DS-GA 2 Lecture notes November 23, 2 Linear functions Linear models A linear model encodes the assumption that two quantities are linearly related. Mathematically, this is characterized using linear functions.
Introduction to Compressed Sensing
 Introduction to Compressed Sensing Alejandro Parada, Gonzalo Arce University of Delaware August 25, 2016 Motivation: Classical Sampling 1 Motivation: Classical Sampling Issues Some applications Radar Spectral
Introduction to Compressed Sensing Alejandro Parada, Gonzalo Arce University of Delaware August 25, 2016 Motivation: Classical Sampling 1 Motivation: Classical Sampling Issues Some applications Radar Spectral
14. Duality. ˆ Upper and lower bounds. ˆ General duality. ˆ Constraint qualifications. ˆ Counterexample. ˆ Complementary slackness.
 CS/ECE/ISyE 524 Introduction to Optimization Spring 2016 17 14. Duality ˆ Upper and lower bounds ˆ General duality ˆ Constraint qualifications ˆ Counterexample ˆ Complementary slackness ˆ Examples ˆ Sensitivity
CS/ECE/ISyE 524 Introduction to Optimization Spring 2016 17 14. Duality ˆ Upper and lower bounds ˆ General duality ˆ Constraint qualifications ˆ Counterexample ˆ Complementary slackness ˆ Examples ˆ Sensitivity
I.3. LMI DUALITY. Didier HENRION EECI Graduate School on Control Supélec - Spring 2010
 I.3. LMI DUALITY Didier HENRION henrion@laas.fr EECI Graduate School on Control Supélec - Spring 2010 Primal and dual For primal problem p = inf x g 0 (x) s.t. g i (x) 0 define Lagrangian L(x, z) = g 0
I.3. LMI DUALITY Didier HENRION henrion@laas.fr EECI Graduate School on Control Supélec - Spring 2010 Primal and dual For primal problem p = inf x g 0 (x) s.t. g i (x) 0 define Lagrangian L(x, z) = g 0
5. Duality. Lagrangian
 5. Duality Convex Optimization Boyd & Vandenberghe Lagrange dual problem weak and strong duality geometric interpretation optimality conditions perturbation and sensitivity analysis examples generalized
5. Duality Convex Optimization Boyd & Vandenberghe Lagrange dual problem weak and strong duality geometric interpretation optimality conditions perturbation and sensitivity analysis examples generalized
Lecture 3 January 28
 EECS 28B / STAT 24B: Advanced Topics in Statistical LearningSpring 2009 Lecture 3 January 28 Lecturer: Pradeep Ravikumar Scribe: Timothy J. Wheeler Note: These lecture notes are still rough, and have only
EECS 28B / STAT 24B: Advanced Topics in Statistical LearningSpring 2009 Lecture 3 January 28 Lecturer: Pradeep Ravikumar Scribe: Timothy J. Wheeler Note: These lecture notes are still rough, and have only
Convex Optimization M2
 Convex Optimization M2 Lecture 3 A. d Aspremont. Convex Optimization M2. 1/49 Duality A. d Aspremont. Convex Optimization M2. 2/49 DMs DM par email: dm.daspremont@gmail.com A. d Aspremont. Convex Optimization
Convex Optimization M2 Lecture 3 A. d Aspremont. Convex Optimization M2. 1/49 Duality A. d Aspremont. Convex Optimization M2. 2/49 DMs DM par email: dm.daspremont@gmail.com A. d Aspremont. Convex Optimization
CS-E4830 Kernel Methods in Machine Learning
 CS-E4830 Kernel Methods in Machine Learning Lecture 3: Convex optimization and duality Juho Rousu 27. September, 2017 Juho Rousu 27. September, 2017 1 / 45 Convex optimization Convex optimisation This
CS-E4830 Kernel Methods in Machine Learning Lecture 3: Convex optimization and duality Juho Rousu 27. September, 2017 Juho Rousu 27. September, 2017 1 / 45 Convex optimization Convex optimisation This
Constrained Optimization and Lagrangian Duality
 CIS 520: Machine Learning Oct 02, 2017 Constrained Optimization and Lagrangian Duality Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may or may
CIS 520: Machine Learning Oct 02, 2017 Constrained Optimization and Lagrangian Duality Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may or may
STAT 200C: High-dimensional Statistics
 STAT 200C: High-dimensional Statistics Arash A. Amini May 30, 2018 1 / 57 Table of Contents 1 Sparse linear models Basis Pursuit and restricted null space property Sufficient conditions for RNS 2 / 57
STAT 200C: High-dimensional Statistics Arash A. Amini May 30, 2018 1 / 57 Table of Contents 1 Sparse linear models Basis Pursuit and restricted null space property Sufficient conditions for RNS 2 / 57
Lecture: Duality of LP, SOCP and SDP
 1/33 Lecture: Duality of LP, SOCP and SDP Zaiwen Wen Beijing International Center For Mathematical Research Peking University http://bicmr.pku.edu.cn/~wenzw/bigdata2017.html wenzw@pku.edu.cn Acknowledgement:
1/33 Lecture: Duality of LP, SOCP and SDP Zaiwen Wen Beijing International Center For Mathematical Research Peking University http://bicmr.pku.edu.cn/~wenzw/bigdata2017.html wenzw@pku.edu.cn Acknowledgement:
Duality. Lagrange dual problem weak and strong duality optimality conditions perturbation and sensitivity analysis generalized inequalities
 Duality Lagrange dual problem weak and strong duality optimality conditions perturbation and sensitivity analysis generalized inequalities Lagrangian Consider the optimization problem in standard form
Duality Lagrange dual problem weak and strong duality optimality conditions perturbation and sensitivity analysis generalized inequalities Lagrangian Consider the optimization problem in standard form
Lagrange Duality. Daniel P. Palomar. Hong Kong University of Science and Technology (HKUST)
") Lagrange Duality Daniel P. Palomar Hong Kong University of Science and Technology (HKUST) ELEC5470 - Convex Optimization Fall 2017-18, HKUST, Hong Kong Outline of Lecture Lagrangian Dual function Dual
Lagrange Duality Daniel P. Palomar Hong Kong University of Science and Technology (HKUST) ELEC5470 - Convex Optimization Fall 2017-18, HKUST, Hong Kong Outline of Lecture Lagrangian Dual function Dual
Convex Optimization Boyd & Vandenberghe. 5. Duality
 5. Duality Convex Optimization Boyd & Vandenberghe Lagrange dual problem weak and strong duality geometric interpretation optimality conditions perturbation and sensitivity analysis examples generalized
5. Duality Convex Optimization Boyd & Vandenberghe Lagrange dual problem weak and strong duality geometric interpretation optimality conditions perturbation and sensitivity analysis examples generalized
Conditions for Robust Principal Component Analysis
 Rose-Hulman Undergraduate Mathematics Journal Volume 12 Issue 2 Article 9 Conditions for Robust Principal Component Analysis Michael Hornstein Stanford University, mdhornstein@gmail.com Follow this and
Rose-Hulman Undergraduate Mathematics Journal Volume 12 Issue 2 Article 9 Conditions for Robust Principal Component Analysis Michael Hornstein Stanford University, mdhornstein@gmail.com Follow this and
Lecture: Introduction to Compressed Sensing Sparse Recovery Guarantees
 Lecture: Introduction to Compressed Sensing Sparse Recovery Guarantees http://bicmr.pku.edu.cn/~wenzw/bigdata2018.html Acknowledgement: this slides is based on Prof. Emmanuel Candes and Prof. Wotao Yin
Lecture: Introduction to Compressed Sensing Sparse Recovery Guarantees http://bicmr.pku.edu.cn/~wenzw/bigdata2018.html Acknowledgement: this slides is based on Prof. Emmanuel Candes and Prof. Wotao Yin
Lecture: Duality.
 Lecture: Duality http://bicmr.pku.edu.cn/~wenzw/opt-2016-fall.html Acknowledgement: this slides is based on Prof. Lieven Vandenberghe s lecture notes Introduction 2/35 Lagrange dual problem weak and strong
Lecture: Duality http://bicmr.pku.edu.cn/~wenzw/opt-2016-fall.html Acknowledgement: this slides is based on Prof. Lieven Vandenberghe s lecture notes Introduction 2/35 Lagrange dual problem weak and strong
PHASE RETRIEVAL OF SPARSE SIGNALS FROM MAGNITUDE INFORMATION. A Thesis MELTEM APAYDIN
 PHASE RETRIEVAL OF SPARSE SIGNALS FROM MAGNITUDE INFORMATION A Thesis by MELTEM APAYDIN Submitted to the Office of Graduate and Professional Studies of Texas A&M University in partial fulfillment of the
PHASE RETRIEVAL OF SPARSE SIGNALS FROM MAGNITUDE INFORMATION A Thesis by MELTEM APAYDIN Submitted to the Office of Graduate and Professional Studies of Texas A&M University in partial fulfillment of the
Sparse Recovery Beyond Compressed Sensing
 Sparse Recovery Beyond Compressed Sensing Carlos Fernandez-Granda www.cims.nyu.edu/~cfgranda Applied Math Colloquium, MIT 4/30/2018 Acknowledgements Project funded by NSF award DMS-1616340 Separable Nonlinear
Sparse Recovery Beyond Compressed Sensing Carlos Fernandez-Granda www.cims.nyu.edu/~cfgranda Applied Math Colloquium, MIT 4/30/2018 Acknowledgements Project funded by NSF award DMS-1616340 Separable Nonlinear
EE/ACM Applications of Convex Optimization in Signal Processing and Communications Lecture 17
 EE/ACM 150 - Applications of Convex Optimization in Signal Processing and Communications Lecture 17 Andre Tkacenko Signal Processing Research Group Jet Propulsion Laboratory May 29, 2012 Andre Tkacenko
EE/ACM 150 - Applications of Convex Optimization in Signal Processing and Communications Lecture 17 Andre Tkacenko Signal Processing Research Group Jet Propulsion Laboratory May 29, 2012 Andre Tkacenko
The Lagrangian L : R d R m R r R is an (easier to optimize) lower bound on the original problem:
 lower bound on the original problem:") HT05: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford Convex Optimization and slides based on Arthur Gretton s Advanced Topics in Machine Learning course
HT05: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford Convex Optimization and slides based on Arthur Gretton s Advanced Topics in Machine Learning course
Lagrangian Duality and Convex Optimization
 Lagrangian Duality and Convex Optimization David Rosenberg New York University February 11, 2015 David Rosenberg (New York University) DS-GA 1003 February 11, 2015 1 / 24 Introduction Why Convex Optimization?
Lagrangian Duality and Convex Optimization David Rosenberg New York University February 11, 2015 David Rosenberg (New York University) DS-GA 1003 February 11, 2015 1 / 24 Introduction Why Convex Optimization?
1 Regression with High Dimensional Data
 6.883 Learning with Combinatorial Structure ote for Lecture 11 Instructor: Prof. Stefanie Jegelka Scribe: Xuhong Zhang 1 Regression with High Dimensional Data Consider the following regression problem:
6.883 Learning with Combinatorial Structure ote for Lecture 11 Instructor: Prof. Stefanie Jegelka Scribe: Xuhong Zhang 1 Regression with High Dimensional Data Consider the following regression problem:
Sparse Optimization Lecture: Dual Certificate in l 1 Minimization
 Sparse Optimization Lecture: Dual Certificate in l 1 Minimization Instructor: Wotao Yin July 2013 Note scriber: Zheng Sun Those who complete this lecture will know what is a dual certificate for l 1 minimization
Sparse Optimization Lecture: Dual Certificate in l 1 Minimization Instructor: Wotao Yin July 2013 Note scriber: Zheng Sun Those who complete this lecture will know what is a dual certificate for l 1 minimization
Supremum of simple stochastic processes
 Subspace embeddings Daniel Hsu COMS 4772 1 Supremum of simple stochastic processes 2 Recap: JL lemma JL lemma. For any ε (0, 1/2), point set S R d of cardinality 16 ln n S = n, and k N such that k, there
Subspace embeddings Daniel Hsu COMS 4772 1 Supremum of simple stochastic processes 2 Recap: JL lemma JL lemma. For any ε (0, 1/2), point set S R d of cardinality 16 ln n S = n, and k N such that k, there
EE 227A: Convex Optimization and Applications October 14, 2008
 EE 227A: Convex Optimization and Applications October 14, 2008 Lecture 13: SDP Duality Lecturer: Laurent El Ghaoui Reading assignment: Chapter 5 of BV. 13.1 Direct approach 13.1.1 Primal problem Consider
EE 227A: Convex Optimization and Applications October 14, 2008 Lecture 13: SDP Duality Lecturer: Laurent El Ghaoui Reading assignment: Chapter 5 of BV. 13.1 Direct approach 13.1.1 Primal problem Consider
Sparse solutions of underdetermined systems
 Sparse solutions of underdetermined systems I-Liang Chern September 22, 2016 1 / 16 Outline Sparsity and Compressibility: the concept for measuring sparsity and compressibility of data Minimum measurements
Sparse solutions of underdetermined systems I-Liang Chern September 22, 2016 1 / 16 Outline Sparsity and Compressibility: the concept for measuring sparsity and compressibility of data Minimum measurements
Lecture 7: Convex Optimizations
 Lecture 7: Convex Optimizations Radu Balan, David Levermore March 29, 2018 Convex Sets. Convex Functions A set S R n is called a convex set if for any points x, y S the line segment [x, y] := {tx + (1
Lecture 7: Convex Optimizations Radu Balan, David Levermore March 29, 2018 Convex Sets. Convex Functions A set S R n is called a convex set if for any points x, y S the line segment [x, y] := {tx + (1
Reconstruction from Anisotropic Random Measurements
 Reconstruction from Anisotropic Random Measurements Mark Rudelson and Shuheng Zhou The University of Michigan, Ann Arbor Coding, Complexity, and Sparsity Workshop, 013 Ann Arbor, Michigan August 7, 013
Reconstruction from Anisotropic Random Measurements Mark Rudelson and Shuheng Zhou The University of Michigan, Ann Arbor Coding, Complexity, and Sparsity Workshop, 013 Ann Arbor, Michigan August 7, 013
Sparsity Regularization
 Sparsity Regularization Bangti Jin Course Inverse Problems & Imaging 1 / 41 Outline 1 Motivation: sparsity? 2 Mathematical preliminaries 3 l 1 solvers 2 / 41 problem setup finite-dimensional formulation
Sparsity Regularization Bangti Jin Course Inverse Problems & Imaging 1 / 41 Outline 1 Motivation: sparsity? 2 Mathematical preliminaries 3 l 1 solvers 2 / 41 problem setup finite-dimensional formulation
Optimization-based sparse recovery: Compressed sensing vs. super-resolution
 Optimization-based sparse recovery: Compressed sensing vs. super-resolution Carlos Fernandez-Granda, Google Computational Photography and Intelligent Cameras, IPAM 2/5/2014 This work was supported by a
Optimization-based sparse recovery: Compressed sensing vs. super-resolution Carlos Fernandez-Granda, Google Computational Photography and Intelligent Cameras, IPAM 2/5/2014 This work was supported by a
IEOR 265 Lecture 3 Sparse Linear Regression
 IOR 65 Lecture 3 Sparse Linear Regression 1 M Bound Recall from last lecture that the reason we are interested in complexity measures of sets is because of the following result, which is known as the M
IOR 65 Lecture 3 Sparse Linear Regression 1 M Bound Recall from last lecture that the reason we are interested in complexity measures of sets is because of the following result, which is known as the M
Lecture Note 5: Semidefinite Programming for Stability Analysis
 ECE7850: Hybrid Systems:Theory and Applications Lecture Note 5: Semidefinite Programming for Stability Analysis Wei Zhang Assistant Professor Department of Electrical and Computer Engineering Ohio State
ECE7850: Hybrid Systems:Theory and Applications Lecture Note 5: Semidefinite Programming for Stability Analysis Wei Zhang Assistant Professor Department of Electrical and Computer Engineering Ohio State
Sparse regression. Optimization-Based Data Analysis. Carlos Fernandez-Granda
 Sparse regression Optimization-Based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_spring16 Carlos Fernandez-Granda 3/28/2016 Regression Least-squares regression Example: Global warming Logistic
Sparse regression Optimization-Based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_spring16 Carlos Fernandez-Granda 3/28/2016 Regression Least-squares regression Example: Global warming Logistic
Overview. Optimization-Based Data Analysis. Carlos Fernandez-Granda
 Overview Optimization-Based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_spring16 Carlos Fernandez-Granda 1/25/2016 Sparsity Denoising Regression Inverse problems Low-rank models Matrix completion
Overview Optimization-Based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_spring16 Carlos Fernandez-Granda 1/25/2016 Sparsity Denoising Regression Inverse problems Low-rank models Matrix completion
EE364a Review Session 5
 EE364a Review Session 5 EE364a Review announcements: homeworks 1 and 2 graded homework 4 solutions (check solution to additional problem 1) scpd phone-in office hours: tuesdays 6-7pm (650-723-1156) 1 Complementary
EE364a Review Session 5 EE364a Review announcements: homeworks 1 and 2 graded homework 4 solutions (check solution to additional problem 1) scpd phone-in office hours: tuesdays 6-7pm (650-723-1156) 1 Complementary
Machine Learning. Support Vector Machines. Manfred Huber
 Machine Learning Support Vector Machines Manfred Huber 2015 1 Support Vector Machines Both logistic regression and linear discriminant analysis learn a linear discriminant function to separate the data
Machine Learning Support Vector Machines Manfred Huber 2015 1 Support Vector Machines Both logistic regression and linear discriminant analysis learn a linear discriminant function to separate the data
Gauge optimization and duality
 1 / 54 Gauge optimization and duality Junfeng Yang Department of Mathematics Nanjing University Joint with Shiqian Ma, CUHK September, 2015 2 / 54 Outline Introduction Duality Lagrange duality Fenchel
1 / 54 Gauge optimization and duality Junfeng Yang Department of Mathematics Nanjing University Joint with Shiqian Ma, CUHK September, 2015 2 / 54 Outline Introduction Duality Lagrange duality Fenchel
Support Vector Machines: Maximum Margin Classifiers
 Support Vector Machines: Maximum Margin Classifiers Machine Learning and Pattern Recognition: September 16, 2008 Piotr Mirowski Based on slides by Sumit Chopra and Fu-Jie Huang 1 Outline What is behind
Support Vector Machines: Maximum Margin Classifiers Machine Learning and Pattern Recognition: September 16, 2008 Piotr Mirowski Based on slides by Sumit Chopra and Fu-Jie Huang 1 Outline What is behind
Lecture 8. Strong Duality Results. September 22, 2008
 Strong Duality Results September 22, 2008 Outline Lecture 8 Slater Condition and its Variations Convex Objective with Linear Inequality Constraints Quadratic Objective over Quadratic Constraints Representation
Strong Duality Results September 22, 2008 Outline Lecture 8 Slater Condition and its Variations Convex Objective with Linear Inequality Constraints Quadratic Objective over Quadratic Constraints Representation
A Brief Review on Convex Optimization
 A Brief Review on Convex Optimization 1 Convex set S R n is convex if x,y S, λ,µ 0, λ+µ = 1 λx+µy S geometrically: x,y S line segment through x,y S examples (one convex, two nonconvex sets): A Brief Review
A Brief Review on Convex Optimization 1 Convex set S R n is convex if x,y S, λ,µ 0, λ+µ = 1 λx+µy S geometrically: x,y S line segment through x,y S examples (one convex, two nonconvex sets): A Brief Review
15. Conic optimization
 L. Vandenberghe EE236C (Spring 216) 15. Conic optimization conic linear program examples modeling duality 15-1 Generalized (conic) inequalities Conic inequality: a constraint x K where K is a convex cone
L. Vandenberghe EE236C (Spring 216) 15. Conic optimization conic linear program examples modeling duality 15-1 Generalized (conic) inequalities Conic inequality: a constraint x K where K is a convex cone
Optimization for Communications and Networks. Poompat Saengudomlert. Session 4 Duality and Lagrange Multipliers
 Optimization for Communications and Networks Poompat Saengudomlert Session 4 Duality and Lagrange Multipliers P Saengudomlert (2015) Optimization Session 4 1 / 14 24 Dual Problems Consider a primal convex
Optimization for Communications and Networks Poompat Saengudomlert Session 4 Duality and Lagrange Multipliers P Saengudomlert (2015) Optimization Session 4 1 / 14 24 Dual Problems Consider a primal convex
Semidefinite Programming Basics and Applications
 Semidefinite Programming Basics and Applications Ray Pörn, principal lecturer Åbo Akademi University Novia University of Applied Sciences Content What is semidefinite programming (SDP)? How to represent
Semidefinite Programming Basics and Applications Ray Pörn, principal lecturer Åbo Akademi University Novia University of Applied Sciences Content What is semidefinite programming (SDP)? How to represent
Lecture Notes on Support Vector Machine
 Lecture Notes on Support Vector Machine Feng Li fli@sdu.edu.cn Shandong University, China 1 Hyperplane and Margin In a n-dimensional space, a hyper plane is defined by ω T x + b = 0 (1) where ω R n is
Lecture Notes on Support Vector Machine Feng Li fli@sdu.edu.cn Shandong University, China 1 Hyperplane and Margin In a n-dimensional space, a hyper plane is defined by ω T x + b = 0 (1) where ω R n is
Towards a Mathematical Theory of Super-resolution
 Towards a Mathematical Theory of Super-resolution Carlos Fernandez-Granda www.stanford.edu/~cfgranda/ Information Theory Forum, Information Systems Laboratory, Stanford 10/18/2013 Acknowledgements This
Towards a Mathematical Theory of Super-resolution Carlos Fernandez-Granda www.stanford.edu/~cfgranda/ Information Theory Forum, Information Systems Laboratory, Stanford 10/18/2013 Acknowledgements This
Course Notes for EE227C (Spring 2018): Convex Optimization and Approximation
: Convex Optimization and Approximation") Course Notes for EE227C (Spring 2018): Convex Optimization and Approximation Instructor: Moritz Hardt Email: hardt+ee227c@berkeley.edu Graduate Instructor: Max Simchowitz Email: msimchow+ee227c@berkeley.edu
Course Notes for EE227C (Spring 2018): Convex Optimization and Approximation Instructor: Moritz Hardt Email: hardt+ee227c@berkeley.edu Graduate Instructor: Max Simchowitz Email: msimchow+ee227c@berkeley.edu
subject to (x 2)(x 4) u,
(x 4) u,") Exercises Basic definitions 5.1 A simple example. Consider the optimization problem with variable x R. minimize x 2 + 1 subject to (x 2)(x 4) 0, (a) Analysis of primal problem. Give the feasible set, the
Exercises Basic definitions 5.1 A simple example. Consider the optimization problem with variable x R. minimize x 2 + 1 subject to (x 2)(x 4) 0, (a) Analysis of primal problem. Give the feasible set, the
E5295/5B5749 Convex optimization with engineering applications. Lecture 5. Convex programming and semidefinite programming
 E5295/5B5749 Convex optimization with engineering applications Lecture 5 Convex programming and semidefinite programming A. Forsgren, KTH 1 Lecture 5 Convex optimization 2006/2007 Convex quadratic program
E5295/5B5749 Convex optimization with engineering applications Lecture 5 Convex programming and semidefinite programming A. Forsgren, KTH 1 Lecture 5 Convex optimization 2006/2007 Convex quadratic program
Sparsity Models. Tong Zhang. Rutgers University. T. Zhang (Rutgers) Sparsity Models 1 / 28
 Sparsity Models 1 / 28") Sparsity Models Tong Zhang Rutgers University T. Zhang (Rutgers) Sparsity Models 1 / 28 Topics Standard sparse regression model algorithms: convex relaxation and greedy algorithm sparse recovery analysis:
Sparsity Models Tong Zhang Rutgers University T. Zhang (Rutgers) Sparsity Models 1 / 28 Topics Standard sparse regression model algorithms: convex relaxation and greedy algorithm sparse recovery analysis:
HW1 solutions. 1. α Ef(x) β, where Ef(x) is the expected value of f(x), i.e., Ef(x) = n. i=1 p if(a i ). (The function f : R R is given.
 β, where Ef(x) is the expected value of f(x), i.e., Ef(x) = n. i=1 p if(a i ). (The function f : R R is given.") HW1 solutions Exercise 1 (Some sets of probability distributions.) Let x be a real-valued random variable with Prob(x = a i ) = p i, i = 1,..., n, where a 1 < a 2 < < a n. Of course p R n lies in the standard
HW1 solutions Exercise 1 (Some sets of probability distributions.) Let x be a real-valued random variable with Prob(x = a i ) = p i, i = 1,..., n, where a 1 < a 2 < < a n. Of course p R n lies in the standard
Recovering overcomplete sparse representations from structured sensing
 Recovering overcomplete sparse representations from structured sensing Deanna Needell Claremont McKenna College Feb. 2015 Support: Alfred P. Sloan Foundation and NSF CAREER #1348721. Joint work with Felix
Recovering overcomplete sparse representations from structured sensing Deanna Needell Claremont McKenna College Feb. 2015 Support: Alfred P. Sloan Foundation and NSF CAREER #1348721. Joint work with Felix
CSCI : Optimization and Control of Networks. Review on Convex Optimization
 CSCI7000-016: Optimization and Control of Networks Review on Convex Optimization 1 Convex set S R n is convex if x,y S, λ,µ 0, λ+µ = 1 λx+µy S geometrically: x,y S line segment through x,y S examples (one
CSCI7000-016: Optimization and Control of Networks Review on Convex Optimization 1 Convex set S R n is convex if x,y S, λ,µ 0, λ+µ = 1 λx+µy S geometrically: x,y S line segment through x,y S examples (one
Linear and non-linear programming
 Linear and non-linear programming Benjamin Recht March 11, 2005 The Gameplan Constrained Optimization Convexity Duality Applications/Taxonomy 1 Constrained Optimization minimize f(x) subject to g j (x)
Linear and non-linear programming Benjamin Recht March 11, 2005 The Gameplan Constrained Optimization Convexity Duality Applications/Taxonomy 1 Constrained Optimization minimize f(x) subject to g j (x)
Shiqian Ma, MAT-258A: Numerical Optimization 1. Chapter 4. Subgradient
 Shiqian Ma, MAT-258A: Numerical Optimization 1 Chapter 4 Subgradient Shiqian Ma, MAT-258A: Numerical Optimization 2 4.1. Subgradients definition subgradient calculus duality and optimality conditions Shiqian
Shiqian Ma, MAT-258A: Numerical Optimization 1 Chapter 4 Subgradient Shiqian Ma, MAT-258A: Numerical Optimization 2 4.1. Subgradients definition subgradient calculus duality and optimality conditions Shiqian
Primal Dual Pursuit A Homotopy based Algorithm for the Dantzig Selector
 Primal Dual Pursuit A Homotopy based Algorithm for the Dantzig Selector Muhammad Salman Asif Thesis Committee: Justin Romberg (Advisor), James McClellan, Russell Mersereau School of Electrical and Computer
Primal Dual Pursuit A Homotopy based Algorithm for the Dantzig Selector Muhammad Salman Asif Thesis Committee: Justin Romberg (Advisor), James McClellan, Russell Mersereau School of Electrical and Computer
COMS 4721: Machine Learning for Data Science Lecture 6, 2/2/2017
 COMS 4721: Machine Learning for Data Science Lecture 6, 2/2/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University UNDERDETERMINED LINEAR EQUATIONS We
COMS 4721: Machine Learning for Data Science Lecture 6, 2/2/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University UNDERDETERMINED LINEAR EQUATIONS We
6-1 The Positivstellensatz P. Parrilo and S. Lall, ECC
 6-1 The Positivstellensatz P. Parrilo and S. Lall, ECC 2003 2003.09.02.10 6. The Positivstellensatz Basic semialgebraic sets Semialgebraic sets Tarski-Seidenberg and quantifier elimination Feasibility
6-1 The Positivstellensatz P. Parrilo and S. Lall, ECC 2003 2003.09.02.10 6. The Positivstellensatz Basic semialgebraic sets Semialgebraic sets Tarski-Seidenberg and quantifier elimination Feasibility
N. L. P. NONLINEAR PROGRAMMING (NLP) deals with optimization models with at least one nonlinear function. NLP. Optimization. Models of following form:
 deals with optimization models with at least one nonlinear function. NLP. Optimization. Models of following form:") 0.1 N. L. P. Katta G. Murty, IOE 611 Lecture slides Introductory Lecture NONLINEAR PROGRAMMING (NLP) deals with optimization models with at least one nonlinear function. NLP does not include everything
0.1 N. L. P. Katta G. Murty, IOE 611 Lecture slides Introductory Lecture NONLINEAR PROGRAMMING (NLP) deals with optimization models with at least one nonlinear function. NLP does not include everything
Sparse Legendre expansions via l 1 minimization
 Sparse Legendre expansions via l 1 minimization Rachel Ward, Courant Institute, NYU Joint work with Holger Rauhut, Hausdorff Center for Mathematics, Bonn, Germany. June 8, 2010 Outline Sparse recovery
Sparse Legendre expansions via l 1 minimization Rachel Ward, Courant Institute, NYU Joint work with Holger Rauhut, Hausdorff Center for Mathematics, Bonn, Germany. June 8, 2010 Outline Sparse recovery
8. Geometric problems
 8. Geometric problems Convex Optimization Boyd & Vandenberghe extremal volume ellipsoids centering classification placement and facility location 8 Minimum volume ellipsoid around a set Löwner-John ellipsoid
8. Geometric problems Convex Optimization Boyd & Vandenberghe extremal volume ellipsoids centering classification placement and facility location 8 Minimum volume ellipsoid around a set Löwner-John ellipsoid
SCRIBERS: SOROOSH SHAFIEEZADEH-ABADEH, MICHAËL DEFFERRARD
 EE-731: ADVANCED TOPICS IN DATA SCIENCES LABORATORY FOR INFORMATION AND INFERENCE SYSTEMS SPRING 2016 INSTRUCTOR: VOLKAN CEVHER SCRIBERS: SOROOSH SHAFIEEZADEH-ABADEH, MICHAËL DEFFERRARD STRUCTURED SPARSITY
EE-731: ADVANCED TOPICS IN DATA SCIENCES LABORATORY FOR INFORMATION AND INFERENCE SYSTEMS SPRING 2016 INSTRUCTOR: VOLKAN CEVHER SCRIBERS: SOROOSH SHAFIEEZADEH-ABADEH, MICHAËL DEFFERRARD STRUCTURED SPARSITY
The convex algebraic geometry of rank minimization
 The convex algebraic geometry of rank minimization Pablo A. Parrilo Laboratory for Information and Decision Systems Massachusetts Institute of Technology International Symposium on Mathematical Programming
The convex algebraic geometry of rank minimization Pablo A. Parrilo Laboratory for Information and Decision Systems Massachusetts Institute of Technology International Symposium on Mathematical Programming
IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 57, NO. 11, NOVEMBER On the Performance of Sparse Recovery
 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 57, NO. 11, NOVEMBER 2011 7255 On the Performance of Sparse Recovery Via `p-minimization (0 p 1) Meng Wang, Student Member, IEEE, Weiyu Xu, and Ao Tang, Senior
IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 57, NO. 11, NOVEMBER 2011 7255 On the Performance of Sparse Recovery Via `p-minimization (0 p 1) Meng Wang, Student Member, IEEE, Weiyu Xu, and Ao Tang, Senior
Compressed Sensing and Sparse Recovery
 ELE 538B: Sparsity, Structure and Inference Compressed Sensing and Sparse Recovery Yuxin Chen Princeton University, Spring 217 Outline Restricted isometry property (RIP) A RIPless theory Compressed sensing
ELE 538B: Sparsity, Structure and Inference Compressed Sensing and Sparse Recovery Yuxin Chen Princeton University, Spring 217 Outline Restricted isometry property (RIP) A RIPless theory Compressed sensing
Motivation. Lecture 2 Topics from Optimization and Duality. network utility maximization (NUM) problem:
 problem:") CDS270 Maryam Fazel Lecture 2 Topics from Optimization and Duality Motivation network utility maximization (NUM) problem: consider a network with S sources (users), each sending one flow at rate x s, through
CDS270 Maryam Fazel Lecture 2 Topics from Optimization and Duality Motivation network utility maximization (NUM) problem: consider a network with S sources (users), each sending one flow at rate x s, through
LECTURE 25: REVIEW/EPILOGUE LECTURE OUTLINE
 LECTURE 25: REVIEW/EPILOGUE LECTURE OUTLINE CONVEX ANALYSIS AND DUALITY Basic concepts of convex analysis Basic concepts of convex optimization Geometric duality framework - MC/MC Constrained optimization
LECTURE 25: REVIEW/EPILOGUE LECTURE OUTLINE CONVEX ANALYSIS AND DUALITY Basic concepts of convex analysis Basic concepts of convex optimization Geometric duality framework - MC/MC Constrained optimization
ICS-E4030 Kernel Methods in Machine Learning
 ICS-E4030 Kernel Methods in Machine Learning Lecture 3: Convex optimization and duality Juho Rousu 28. September, 2016 Juho Rousu 28. September, 2016 1 / 38 Convex optimization Convex optimisation This
ICS-E4030 Kernel Methods in Machine Learning Lecture 3: Convex optimization and duality Juho Rousu 28. September, 2016 Juho Rousu 28. September, 2016 1 / 38 Convex optimization Convex optimisation This
Geometric problems. Chapter Projection on a set. The distance of a point x 0 R n to a closed set C R n, in the norm, is defined as
 Chapter 8 Geometric problems 8.1 Projection on a set The distance of a point x 0 R n to a closed set C R n, in the norm, is defined as dist(x 0,C) = inf{ x 0 x x C}. The infimum here is always achieved.
Chapter 8 Geometric problems 8.1 Projection on a set The distance of a point x 0 R n to a closed set C R n, in the norm, is defined as dist(x 0,C) = inf{ x 0 x x C}. The infimum here is always achieved.
Nonlinear Programming 3rd Edition. Theoretical Solutions Manual Chapter 6
 Nonlinear Programming 3rd Edition Theoretical Solutions Manual Chapter 6 Dimitri P. Bertsekas Massachusetts Institute of Technology Athena Scientific, Belmont, Massachusetts 1 NOTE This manual contains
Nonlinear Programming 3rd Edition Theoretical Solutions Manual Chapter 6 Dimitri P. Bertsekas Massachusetts Institute of Technology Athena Scientific, Belmont, Massachusetts 1 NOTE This manual contains
Demixing Sines and Spikes: Robust Spectral Super-resolution in the Presence of Outliers
 Demixing Sines and Spikes: Robust Spectral Super-resolution in the Presence of Outliers Carlos Fernandez-Granda, Gongguo Tang, Xiaodong Wang and Le Zheng September 6 Abstract We consider the problem of
Demixing Sines and Spikes: Robust Spectral Super-resolution in the Presence of Outliers Carlos Fernandez-Granda, Gongguo Tang, Xiaodong Wang and Le Zheng September 6 Abstract We consider the problem of
SPARSE signal representations have gained popularity in recent
 6958 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 57, NO. 10, OCTOBER 2011 Blind Compressed Sensing Sivan Gleichman and Yonina C. Eldar, Senior Member, IEEE Abstract The fundamental principle underlying
6958 IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 57, NO. 10, OCTOBER 2011 Blind Compressed Sensing Sivan Gleichman and Yonina C. Eldar, Senior Member, IEEE Abstract The fundamental principle underlying
Subgradients. subgradients. strong and weak subgradient calculus. optimality conditions via subgradients. directional derivatives
 Subgradients subgradients strong and weak subgradient calculus optimality conditions via subgradients directional derivatives Prof. S. Boyd, EE364b, Stanford University Basic inequality recall basic inequality
Subgradients subgradients strong and weak subgradient calculus optimality conditions via subgradients directional derivatives Prof. S. Boyd, EE364b, Stanford University Basic inequality recall basic inequality
Convex Optimization. Dani Yogatama. School of Computer Science, Carnegie Mellon University, Pittsburgh, PA, USA. February 12, 2014
 Convex Optimization Dani Yogatama School of Computer Science, Carnegie Mellon University, Pittsburgh, PA, USA February 12, 2014 Dani Yogatama (Carnegie Mellon University) Convex Optimization February 12,
Convex Optimization Dani Yogatama School of Computer Science, Carnegie Mellon University, Pittsburgh, PA, USA February 12, 2014 Dani Yogatama (Carnegie Mellon University) Convex Optimization February 12,
Uniqueness Conditions for A Class of l 0 -Minimization Problems
 Uniqueness Conditions for A Class of l 0 -Minimization Problems Chunlei Xu and Yun-Bin Zhao October, 03, Revised January 04 Abstract. We consider a class of l 0 -minimization problems, which is to search
Uniqueness Conditions for A Class of l 0 -Minimization Problems Chunlei Xu and Yun-Bin Zhao October, 03, Revised January 04 Abstract. We consider a class of l 0 -minimization problems, which is to search
ECE 8201: Low-dimensional Signal Models for High-dimensional Data Analysis
 ECE 8201: Low-dimensional Signal Models for High-dimensional Data Analysis Lecture 7: Matrix completion Yuejie Chi The Ohio State University Page 1 Reference Guaranteed Minimum-Rank Solutions of Linear
ECE 8201: Low-dimensional Signal Models for High-dimensional Data Analysis Lecture 7: Matrix completion Yuejie Chi The Ohio State University Page 1 Reference Guaranteed Minimum-Rank Solutions of Linear
Optimization for Compressed Sensing
 Optimization for Compressed Sensing Robert J. Vanderbei 2014 March 21 Dept. of Industrial & Systems Engineering University of Florida http://www.princeton.edu/ rvdb Lasso Regression The problem is to solve
Optimization for Compressed Sensing Robert J. Vanderbei 2014 March 21 Dept. of Industrial & Systems Engineering University of Florida http://www.princeton.edu/ rvdb Lasso Regression The problem is to solve
Linear Programming. Larry Blume Cornell University, IHS Vienna and SFI. Summer 2016
 Linear Programming Larry Blume Cornell University, IHS Vienna and SFI Summer 2016 These notes derive basic results in finite-dimensional linear programming using tools of convex analysis. Most sources
Linear Programming Larry Blume Cornell University, IHS Vienna and SFI Summer 2016 These notes derive basic results in finite-dimensional linear programming using tools of convex analysis. Most sources
Statistical Issues in Searches: Photon Science Response. Rebecca Willett, Duke University
 Statistical Issues in Searches: Photon Science Response Rebecca Willett, Duke University 1 / 34 Photon science seen this week Applications tomography ptychography nanochrystalography coherent diffraction
Statistical Issues in Searches: Photon Science Response Rebecca Willett, Duke University 1 / 34 Photon science seen this week Applications tomography ptychography nanochrystalography coherent diffraction
ECE 8201: Low-dimensional Signal Models for High-dimensional Data Analysis
 ECE 8201: Low-dimensional Signal Models for High-dimensional Data Analysis Lecture 3: Sparse signal recovery: A RIPless analysis of l 1 minimization Yuejie Chi The Ohio State University Page 1 Outline
ECE 8201: Low-dimensional Signal Models for High-dimensional Data Analysis Lecture 3: Sparse signal recovery: A RIPless analysis of l 1 minimization Yuejie Chi The Ohio State University Page 1 Outline
10 Numerical methods for constrained problems
 10 Numerical methods for constrained problems min s.t. f(x) h(x) = 0 (l), g(x) 0 (m), x X The algorithms can be roughly divided the following way: ˆ primal methods: find descent direction keeping inside
10 Numerical methods for constrained problems min s.t. f(x) h(x) = 0 (l), g(x) 0 (m), x X The algorithms can be roughly divided the following way: ˆ primal methods: find descent direction keeping inside
LMI MODELLING 4. CONVEX LMI MODELLING. Didier HENRION. LAAS-CNRS Toulouse, FR Czech Tech Univ Prague, CZ. Universidad de Valladolid, SP March 2009
 LMI MODELLING 4. CONVEX LMI MODELLING Didier HENRION LAAS-CNRS Toulouse, FR Czech Tech Univ Prague, CZ Universidad de Valladolid, SP March 2009 Minors A minor of a matrix F is the determinant of a submatrix
LMI MODELLING 4. CONVEX LMI MODELLING Didier HENRION LAAS-CNRS Toulouse, FR Czech Tech Univ Prague, CZ Universidad de Valladolid, SP March 2009 Minors A minor of a matrix F is the determinant of a submatrix
EE/AA 578, Univ of Washington, Fall Duality
 7. Duality EE/AA 578, Univ of Washington, Fall 2016 Lagrange dual problem weak and strong duality geometric interpretation optimality conditions perturbation and sensitivity analysis examples generalized
7. Duality EE/AA 578, Univ of Washington, Fall 2016 Lagrange dual problem weak and strong duality geometric interpretation optimality conditions perturbation and sensitivity analysis examples generalized
3. Linear Programming and Polyhedral Combinatorics
 Massachusetts Institute of Technology 18.433: Combinatorial Optimization Michel X. Goemans February 28th, 2013 3. Linear Programming and Polyhedral Combinatorics Summary of what was seen in the introductory
Massachusetts Institute of Technology 18.433: Combinatorial Optimization Michel X. Goemans February 28th, 2013 3. Linear Programming and Polyhedral Combinatorics Summary of what was seen in the introductory
Primal/Dual Decomposition Methods
 Primal/Dual Decomposition Methods Daniel P. Palomar Hong Kong University of Science and Technology (HKUST) ELEC5470 - Convex Optimization Fall 2018-19, HKUST, Hong Kong Outline of Lecture Subgradients
Primal/Dual Decomposition Methods Daniel P. Palomar Hong Kong University of Science and Technology (HKUST) ELEC5470 - Convex Optimization Fall 2018-19, HKUST, Hong Kong Outline of Lecture Subgradients
CS295: Convex Optimization. Xiaohui Xie Department of Computer Science University of California, Irvine
 CS295: Convex Optimization Xiaohui Xie Department of Computer Science University of California, Irvine Course information Prerequisites: multivariate calculus and linear algebra Textbook: Convex Optimization
CS295: Convex Optimization Xiaohui Xie Department of Computer Science University of California, Irvine Course information Prerequisites: multivariate calculus and linear algebra Textbook: Convex Optimization
Support Vector Machines
 Support Vector Machines Support vector machines (SVMs) are one of the central concepts in all of machine learning. They are simply a combination of two ideas: linear classification via maximum (or optimal
Support Vector Machines Support vector machines (SVMs) are one of the central concepts in all of machine learning. They are simply a combination of two ideas: linear classification via maximum (or optimal
4. Convex optimization problems
 Convex Optimization Boyd & Vandenberghe 4. Convex optimization problems optimization problem in standard form convex optimization problems quasiconvex optimization linear optimization quadratic optimization
Convex Optimization Boyd & Vandenberghe 4. Convex optimization problems optimization problem in standard form convex optimization problems quasiconvex optimization linear optimization quadratic optimization
Lecture 22: More On Compressed Sensing
 Lecture 22: More On Compressed Sensing Scribed by Eric Lee, Chengrun Yang, and Sebastian Ament Nov. 2, 207 Recap and Introduction Basis pursuit was the method of recovering the sparsest solution to an
Lecture 22: More On Compressed Sensing Scribed by Eric Lee, Chengrun Yang, and Sebastian Ament Nov. 2, 207 Recap and Introduction Basis pursuit was the method of recovering the sparsest solution to an
3. Vector spaces 3.1 Linear dependence and independence 3.2 Basis and dimension. 5. Extreme points and basic feasible solutions
 A. LINEAR ALGEBRA. CONVEX SETS 1. Matrices and vectors 1.1 Matrix operations 1.2 The rank of a matrix 2. Systems of linear equations 2.1 Basic solutions 3. Vector spaces 3.1 Linear dependence and independence
A. LINEAR ALGEBRA. CONVEX SETS 1. Matrices and vectors 1.1 Matrix operations 1.2 The rank of a matrix 2. Systems of linear equations 2.1 Basic solutions 3. Vector spaces 3.1 Linear dependence and independence
Optimality Conditions for Constrained Optimization
 72 CHAPTER 7 Optimality Conditions for Constrained Optimization 1. First Order Conditions In this section we consider first order optimality conditions for the constrained problem P : minimize f 0 (x)
72 CHAPTER 7 Optimality Conditions for Constrained Optimization 1. First Order Conditions In this section we consider first order optimality conditions for the constrained problem P : minimize f 0 (x)
Subgradients. subgradients and quasigradients. subgradient calculus. optimality conditions via subgradients. directional derivatives
 Subgradients subgradients and quasigradients subgradient calculus optimality conditions via subgradients directional derivatives Prof. S. Boyd, EE392o, Stanford University Basic inequality recall basic
Subgradients subgradients and quasigradients subgradient calculus optimality conditions via subgradients directional derivatives Prof. S. Boyd, EE392o, Stanford University Basic inequality recall basic
Linear Models. DS-GA 1013 / MATH-GA 2824 Optimization-based Data Analysis.
 Linear Models DS-GA 1013 / MATH-GA 2824 Optimization-based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_fall17/index.html Carlos Fernandez-Granda Linear regression Least-squares estimation
Linear Models DS-GA 1013 / MATH-GA 2824 Optimization-based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_fall17/index.html Carlos Fernandez-Granda Linear regression Least-squares estimation
Near Optimal Signal Recovery from Random Projections
 1 Near Optimal Signal Recovery from Random Projections Emmanuel Candès, California Institute of Technology Multiscale Geometric Analysis in High Dimensions: Workshop # 2 IPAM, UCLA, October 2004 Collaborators:
1 Near Optimal Signal Recovery from Random Projections Emmanuel Candès, California Institute of Technology Multiscale Geometric Analysis in High Dimensions: Workshop # 2 IPAM, UCLA, October 2004 Collaborators:
ECE G: Special Topics in Signal Processing: Sparsity, Structure, and Inference
 ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Low-rank matrix recovery via convex relaxations Yuejie Chi Department of Electrical and Computer Engineering Spring
ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Low-rank matrix recovery via convex relaxations Yuejie Chi Department of Electrical and Computer Engineering Spring