Alphabet Friendly FM Index
|
|
|
- Merilyn Barker
- 5 years ago
- Views:
Transcription
1 Alphabet Friendly FM Index Author: Rodrigo González Santiago, November 8 th, 2005 Departamento de Ciencias de la Computación Universidad de Chile
2 Outline Motivations Basics Burrows Wheeler Transform FM Index Compression boosting Wavelet tree Alphabet Friendly FM Index Experimental results Conclusions Departamento de Ciencias de la Computación Universidad de Chile
3 Motivations In pattern matching, the main problem consists in determining the number of occurrences of a pattern P over a text T, where text and pattern are sequences of characters from an alphabet Σ of size σ. Many different indexing data structures have been proposed for this aim, such as inverted lists, suffix trees, suffix arrays and succinct indexes. Over time, the size of textual information has been growing, hence the importance of having succinct indexing data structures for pattern matching. This has motivated a search for less space demanding indexes, in particular, using the same or less space than the original text. One of the most recent succinct indexes is the Alphabet Friendly FM Index, from now on AF FMI. Departamento de Ciencias de la Computación Universidad de Chile
4 Basics The suffix array of a text T is an array A that contains all the starting positions of the suffixes of the text T, such that T[A[1] n]<t[a[2] n]< <T[A[n] n], that is, array A gives the lexicographic order of all suffixes of the text T. The empirical entropy H resembles the entropy defined in the probabilistic setting. However, the empirical entropy is defined for any string and can be used to measure the performance of compression algorithms without any assumption on the input. So, when we create a succinct index structure it is natural to ask how close the index structure is to H k and which kind of search the index structure supports. Departamento de Ciencias de la Computación Universidad de Chile
5 Burrows Wheeler Transform (1) Burrows and Wheeler introduced a new compression algorithm based on a reversible transformation now called the Burrows Wheeler Transform (BWT from now on). The BWT consists of three basic steps: append at the end of T a special character # smaller than any other text character form a conceptual matrix M whose rows are the cyclic shifts of the string T# sorted in lexicographic order construct the transformed text BWT by taking the last column of matrix M. Departamento de Ciencias de la Computación Universidad de Chile
6 Burrows Wheeler Transform (2) Departamento de Ciencias de la Computación Universidad de Chile
7 Burrows Wheeler Transform (3) The inverse of the BWT consists in calculating: LF(i)=C[BWT[i]]+Occ(BWT[i],i) For c Σ, let C[c] be the total number of text characters which are alphabetically smaller than c. For c Σ, let Occ(c,q) be the number of occurrences of character c in the prefix BWT[1,q]. LF( ) comes from Last to First column mapping because character BWT[i] is located in the first column of M at position LF(i). In this way, we can navigate the text T backwards. That is, if T[k]= BWT[i], then T[k 1]= BWT [LF(i)] Departamento de Ciencias de la Computación Universidad de Chile
8 Burrows Wheeler Transform (4) For example if i=9 then LF(9)=C[BWT[9]]+Occ(BWT[9],9) = C[s]+Occ(s,9) = 8+3 = 11 Departamento de Ciencias de la Computación Universidad de Chile
9 FM Index (1) The FM index is a full text self index that allows to efficiently search for the occurrences of an arbitrary pattern P as a substring of the text T. The FM index is composed of a compressed representation of BWT with auxiliary structures that permit us to compute in O(1) time the value of Occ(c,q) with c Σ and for any q [1...n]. Departamento de Ciencias de la Computación Universidad de Chile
10 FM Index (2) The pseudo code of the counting operation that works in p phases is: To obtain the position of each row where P[1,p] is prefix, it is necessary to mark one text position every O(log 2 n/ log log n) and then to use LF(.) until finding a marked position. Departamento de Ciencias de la Computación Universidad de Chile
11 FM Index (3) For example if P= si c=p[i]=p[2]= i First=C[c]+Occ(c,First 1)+1=C[ i ]+0+1=2 Last=C[c]+Occ(c,Last)=C[ i ]+4=1+4=5 Departamento de Ciencias de la Computación Universidad de Chile
12 FM Index (4) c=p[1]= s First=C[c]+Occ(c,First 1)+1=C( s )+Occ( s,1 1)+1=8+0+1=9 Last=C[c]+Occ(c,Last)=C( s )+Occ( s,5)=8+2=10 Departamento de Ciencias de la Computación Universidad de Chile
13 Compression boosting (1) The key idea is that one can take an algorithm whose performance can be bounded in terms of the zero order entropy and obtain, via the booster, a new compressor whose performance can be bounded in terms of the k th order entropy, simultaneously for all k. The boosting technique computes an optimal partition S={s 1,s 2 s z } of BWT, such that, if we compress each s i with a zero th order entropy, we have a k th order entropy bound for the compressed BWT.
14 Rank First we show a binary rank: Rank 1 (Bits,i)=numbers of ones in Bits[1,i] Rank 1 (Bits,203)= =Superblock(203/32)+Block(203/8)+count( ,203%8) =Superblock(6)+Block(25)+popcount( ) = =113
15 Wavelet tree (1) Theorem. Let W[1..w] denote a string over an arbitrary alphabet. The wavelet tree built on W uses wh 0 (W) + O(log (w log log w)/ log w) bits of storage and supports in O(log ) time the following operations: given q, 1 q w, the retrieval of the character W[q]; given c and q, 1 q w, the computation of the number of occurrences Occ W (c, q) of c in W[1..q].
16 Wavelet tree (2) C 1 =0000,C 3 =0010
17 Alphabet Friendly FM Index (1) To build the FM index we need to solve two problems: a) to compress BWT up to H k (T) b) to compute Occ(c, q) and BWT[q] in time independent of n. We use the boosting technique to transform problem a) into the problem of compressing the strings s 1,s 2 s z up to their zero th order entropy, and we use the wavelet tree to create a compressed (up to H 0 ) and indexable representation of each s i thus solving simultaneously problems a) and b).
18 Alphabet Friendly FM Index (2) Construction First we determine the optimal partition s 1,s 2 s z using the booster. Build a binary string B that keeps track of the starting positions in BWT of the s iʹs. For each string s i, i = 1 z build: the array C i [1, ] such that C i [c] stores the occurrences of character c within s 1,s 2 s i 1 the wavelet tree T i.
19 Alphabet Friendly FM Index (2) To compute BWT[q], we first determine the substring s y containing the q th character of BWT by computing y=rank 1 (B,q). Then we exploit the wavelet tree T y to determine BWT[q]. To compute Occ(c, q), we initially determine the substring s y where the row q occurs, y=rank 1 (B,q). Then we exploit the wavelet tree T y and the array C y [c] to compute Occ(c,q)=Occ_s y (c,q )+C y [c], where q = q sum(j=1..y 1; s j )
20 Alphabet Friendly FM Index (3) The size of the new index built on a string T[1,n] is bounded by nh k (T)+O(log (n loglog n)/ log n) bits, where H k (T) is the k th order empirical entropy of T. The above bound holds simultaneously for all k αlog n and any constant 0<α< 1. Moreover, the index design does not depend on the parameter k, which plays a role only in analysis of the space occupancy. Using the AF index, the counting of the occurrences of an arbitrary pattern P[1,p] as a substring of T takes O(p log ) time. Locating each pattern occurrence takes O(log (log 2 n/ loglog n)) time. Reporting a text substring of length l takes O((l + log 2 n/ loglog n) log ) time.
21 Alphabet Friendly FM Index (4) Using O(n) additional bits of storage, we can design a variant of the AF FMI that counts the pattern occurrences in O(p/ε) time (independent on ), and O((log 2 n/loglogn) ε /ε) time to locate each occurrence. To achive this we show first an approach with flat bit arrays Let W[1,w] be a substring of the BWT computed for the indexed text T. Instead of the wavelet tree, we process W by building bit arrays S c such that S c [i] = 1 if and only if W[i] = c. We then construct a FID data structure over each S c to support in constant time Rank 1 () and Select 1 () queries. Now a more general tradeoff with r ary trees Let us consider an r ary tree built over a string W[1,w]. Much like a wavelet tree, each node u of the r ary tree is responsible for a subset of the alphabet, say u, so that u represents the subsequence W u of W formed by the characters in u. The root node stands for the whole, and thus stores the whole string W. Each node u with children u 1 u r splits its alphabet u into r equally sized subsets u1 ur.
22 Alphabet Friendly FM Index (5) In each node u j, child of u, we store a bit array S uj of length W u such that S uj [q] = 1 whenever W u [q] uj. S uj is indeed the characteristic vector of the characters of W u copied into W uj. A FID data structure is then built over S uj to answer in constant time Rank 1 () and Select 1 () queries. Finally, if we also have =O(polylog n), the counting of the occurrences of an arbitrary pattern P[1,p] as a substring of T takes O(p) time. Locating each pattern occurrence takes O(log 1+ε n) time. Reporting a text substring of length l takes O(l + log 1+ε n) time.
23 Experimental Results (1) We have the following site that supports the test bed to all our experimental results: We compare several indexes over a collection of files. code/sources.100mb code/sources.50mb dna/dna.100mb dna/dna.50mb music/pitches.50mb nlang/english.100mb nlang/english.50mb protein/proteins.50mb xml/dblp.xml.100mb xml/dblp.xml.50mb
24 Experimental Results (2) Index size(count) CCSA SSA RLFM AF-FMI Text xml/dblp.xml.100mb xml/dblp.xml.50mb protein/proteins.50mb code/sources.100mb code/sources.50mb dna/dna.100mb dna/dna.50mb music/pitches.50mb nlang/english.100mb nlang/english.50mb Size (MB)
25 Experimental Results (3) Index size(samplesize=64) CCSA SSA RLFM AF-FMI Text xml/dblp.xml.100mb xml/dblp.xml.50mb code/sources.100mb code/sources.50mb dna/dna.100mb dna/dna.50mb music/pitches.50mb nlang/english.100mb nlang/english.50mb protein/proteins.50mb Size (MB)

26 Experimental Results (4)


27 Experimental Results (5)
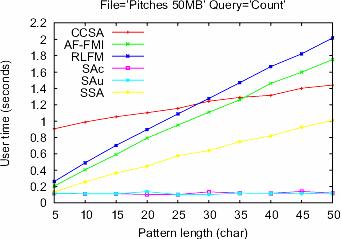

28 Experimental Results (6)
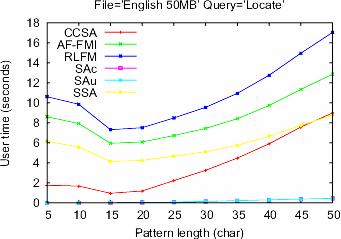
29 Experimental Results (7)
30 Experimental Results (8)
31 Experimental Results (9)
32 Conclusions We have shown that the combination of the FM index, compression boosting techniques, wavelet trees, and fully indexable dictionaries, yields a simple data structure that uses asymptotically optimal space. The AF Index is very competitive with the existing full text selfindexes. Departamento de Ciencias de la Computación Universidad de Chile
33 Questions? Departamento de Ciencias de la Computación Universidad de Chile
Succinct Suffix Arrays based on Run-Length Encoding
 Succinct Suffix Arrays based on Run-Length Encoding Veli Mäkinen Gonzalo Navarro Abstract A succinct full-text self-index is a data structure built on a text T = t 1 t 2...t n, which takes little space
Succinct Suffix Arrays based on Run-Length Encoding Veli Mäkinen Gonzalo Navarro Abstract A succinct full-text self-index is a data structure built on a text T = t 1 t 2...t n, which takes little space
Compressed Representations of Sequences and Full-Text Indexes
 Compressed Representations of Sequences and Full-Text Indexes PAOLO FERRAGINA Università di Pisa GIOVANNI MANZINI Università del Piemonte Orientale VELI MÄKINEN University of Helsinki AND GONZALO NAVARRO
Compressed Representations of Sequences and Full-Text Indexes PAOLO FERRAGINA Università di Pisa GIOVANNI MANZINI Università del Piemonte Orientale VELI MÄKINEN University of Helsinki AND GONZALO NAVARRO
Compressed Representations of Sequences and Full-Text Indexes
 Compressed Representations of Sequences and Full-Text Indexes PAOLO FERRAGINA Dipartimento di Informatica, Università di Pisa, Italy GIOVANNI MANZINI Dipartimento di Informatica, Università del Piemonte
Compressed Representations of Sequences and Full-Text Indexes PAOLO FERRAGINA Dipartimento di Informatica, Università di Pisa, Italy GIOVANNI MANZINI Dipartimento di Informatica, Università del Piemonte
Smaller and Faster Lempel-Ziv Indices
 Smaller and Faster Lempel-Ziv Indices Diego Arroyuelo and Gonzalo Navarro Dept. of Computer Science, Universidad de Chile, Chile. {darroyue,gnavarro}@dcc.uchile.cl Abstract. Given a text T[1..u] over an
Smaller and Faster Lempel-Ziv Indices Diego Arroyuelo and Gonzalo Navarro Dept. of Computer Science, Universidad de Chile, Chile. {darroyue,gnavarro}@dcc.uchile.cl Abstract. Given a text T[1..u] over an
Theoretical Computer Science. Dynamic rank/select structures with applications to run-length encoded texts
 Theoretical Computer Science 410 (2009) 4402 4413 Contents lists available at ScienceDirect Theoretical Computer Science journal homepage: www.elsevier.com/locate/tcs Dynamic rank/select structures with
Theoretical Computer Science 410 (2009) 4402 4413 Contents lists available at ScienceDirect Theoretical Computer Science journal homepage: www.elsevier.com/locate/tcs Dynamic rank/select structures with
arxiv: v1 [cs.ds] 25 Nov 2009
![arxiv: v1 [cs.ds] 25 Nov 2009](/thumbs/92/110125947.jpg "arxiv: v1 [cs.ds] 25 Nov 2009") Alphabet Partitioning for Compressed Rank/Select with Applications Jérémy Barbay 1, Travis Gagie 1, Gonzalo Navarro 1 and Yakov Nekrich 2 1 Department of Computer Science University of Chile {jbarbay,
Alphabet Partitioning for Compressed Rank/Select with Applications Jérémy Barbay 1, Travis Gagie 1, Gonzalo Navarro 1 and Yakov Nekrich 2 1 Department of Computer Science University of Chile {jbarbay,
Succincter text indexing with wildcards
 University of British Columbia CPM 2011 June 27, 2011 Problem overview Problem overview Problem overview Problem overview Problem overview Problem overview Problem overview Problem overview Problem overview
University of British Columbia CPM 2011 June 27, 2011 Problem overview Problem overview Problem overview Problem overview Problem overview Problem overview Problem overview Problem overview Problem overview
arxiv: v1 [cs.ds] 19 Apr 2011
![arxiv: v1 [cs.ds] 19 Apr 2011](/thumbs/78/76803171.jpg "arxiv: v1 [cs.ds] 19 Apr 2011") Fixed Block Compression Boosting in FM-Indexes Juha Kärkkäinen 1 and Simon J. Puglisi 2 1 Department of Computer Science, University of Helsinki, Finland juha.karkkainen@cs.helsinki.fi 2 Department of
Fixed Block Compression Boosting in FM-Indexes Juha Kärkkäinen 1 and Simon J. Puglisi 2 1 Department of Computer Science, University of Helsinki, Finland juha.karkkainen@cs.helsinki.fi 2 Department of
Indexing LZ77: The Next Step in Self-Indexing. Gonzalo Navarro Department of Computer Science, University of Chile
 Indexing LZ77: The Next Step in Self-Indexing Gonzalo Navarro Department of Computer Science, University of Chile gnavarro@dcc.uchile.cl Part I: Why Jumping off the Cliff The Past Century Self-Indexing:
Indexing LZ77: The Next Step in Self-Indexing Gonzalo Navarro Department of Computer Science, University of Chile gnavarro@dcc.uchile.cl Part I: Why Jumping off the Cliff The Past Century Self-Indexing:
Preview: Text Indexing
 Simon Gog gog@ira.uka.de - Simon Gog: KIT University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association www.kit.edu Text Indexing Motivation Problems Given a text
Simon Gog gog@ira.uka.de - Simon Gog: KIT University of the State of Baden-Wuerttemberg and National Research Center of the Helmholtz Association www.kit.edu Text Indexing Motivation Problems Given a text
Text Indexing: Lecture 6
 Simon Gog gog@kit.edu - 0 Simon Gog: KIT The Research University in the Helmholtz Association www.kit.edu Reviewing the last two lectures We have seen two top-k document retrieval frameworks. Question
Simon Gog gog@kit.edu - 0 Simon Gog: KIT The Research University in the Helmholtz Association www.kit.edu Reviewing the last two lectures We have seen two top-k document retrieval frameworks. Question
Complementary Contextual Models with FM-index for DNA Compression
 2017 Data Compression Conference Complementary Contextual Models with FM-index for DNA Compression Wenjing Fan,WenruiDai,YongLi, and Hongkai Xiong Department of Electronic Engineering Department of Biomedical
2017 Data Compression Conference Complementary Contextual Models with FM-index for DNA Compression Wenjing Fan,WenruiDai,YongLi, and Hongkai Xiong Department of Electronic Engineering Department of Biomedical
Dynamic Entropy-Compressed Sequences and Full-Text Indexes
 Dynamic Entropy-Compressed Sequences and Full-Text Indexes VELI MÄKINEN University of Helsinki and GONZALO NAVARRO University of Chile First author funded by the Academy of Finland under grant 108219.
Dynamic Entropy-Compressed Sequences and Full-Text Indexes VELI MÄKINEN University of Helsinki and GONZALO NAVARRO University of Chile First author funded by the Academy of Finland under grant 108219.
Small-Space Dictionary Matching (Dissertation Proposal)
") Small-Space Dictionary Matching (Dissertation Proposal) Graduate Center of CUNY 1/24/2012 Problem Definition Dictionary Matching Input: Dictionary D = P 1,P 2,...,P d containing d patterns. Text T of length
Small-Space Dictionary Matching (Dissertation Proposal) Graduate Center of CUNY 1/24/2012 Problem Definition Dictionary Matching Input: Dictionary D = P 1,P 2,...,P d containing d patterns. Text T of length
A Simple Alphabet-Independent FM-Index
 A Simple Alphabet-Independent -Index Szymon Grabowski 1, Veli Mäkinen 2, Gonzalo Navarro 3, Alejandro Salinger 3 1 Computer Engineering Dept., Tech. Univ. of Lódź, Poland. e-mail: sgrabow@zly.kis.p.lodz.pl
A Simple Alphabet-Independent -Index Szymon Grabowski 1, Veli Mäkinen 2, Gonzalo Navarro 3, Alejandro Salinger 3 1 Computer Engineering Dept., Tech. Univ. of Lódź, Poland. e-mail: sgrabow@zly.kis.p.lodz.pl
Alphabet-Independent Compressed Text Indexing
 Alphabet-Independent Compressed Text Indexing DJAMAL BELAZZOUGUI Université Paris Diderot GONZALO NAVARRO University of Chile Self-indexes are able to represent a text within asymptotically the information-theoretic
Alphabet-Independent Compressed Text Indexing DJAMAL BELAZZOUGUI Université Paris Diderot GONZALO NAVARRO University of Chile Self-indexes are able to represent a text within asymptotically the information-theoretic
arxiv: v1 [cs.ds] 15 Feb 2012
![arxiv: v1 [cs.ds] 15 Feb 2012](/thumbs/92/110725364.jpg "arxiv: v1 [cs.ds] 15 Feb 2012") Linear-Space Substring Range Counting over Polylogarithmic Alphabets Travis Gagie 1 and Pawe l Gawrychowski 2 1 Aalto University, Finland travis.gagie@aalto.fi 2 Max Planck Institute, Germany gawry@cs.uni.wroc.pl
Linear-Space Substring Range Counting over Polylogarithmic Alphabets Travis Gagie 1 and Pawe l Gawrychowski 2 1 Aalto University, Finland travis.gagie@aalto.fi 2 Max Planck Institute, Germany gawry@cs.uni.wroc.pl
Compressed Index for Dynamic Text
 Compressed Index for Dynamic Text Wing-Kai Hon Tak-Wah Lam Kunihiko Sadakane Wing-Kin Sung Siu-Ming Yiu Abstract This paper investigates how to index a text which is subject to updates. The best solution
Compressed Index for Dynamic Text Wing-Kai Hon Tak-Wah Lam Kunihiko Sadakane Wing-Kin Sung Siu-Ming Yiu Abstract This paper investigates how to index a text which is subject to updates. The best solution
Self-Indexed Grammar-Based Compression
 Fundamenta Informaticae XXI (2001) 1001 1025 1001 IOS Press Self-Indexed Grammar-Based Compression Francisco Claude David R. Cheriton School of Computer Science University of Waterloo fclaude@cs.uwaterloo.ca
Fundamenta Informaticae XXI (2001) 1001 1025 1001 IOS Press Self-Indexed Grammar-Based Compression Francisco Claude David R. Cheriton School of Computer Science University of Waterloo fclaude@cs.uwaterloo.ca
Rank and Select Operations on Binary Strings (1974; Elias)
") Rank and Select Operations on Binary Strings (1974; Elias) Naila Rahman, University of Leicester, www.cs.le.ac.uk/ nyr1 Rajeev Raman, University of Leicester, www.cs.le.ac.uk/ rraman entry editor: Paolo
Rank and Select Operations on Binary Strings (1974; Elias) Naila Rahman, University of Leicester, www.cs.le.ac.uk/ nyr1 Rajeev Raman, University of Leicester, www.cs.le.ac.uk/ rraman entry editor: Paolo
Lecture 18 April 26, 2012
 6.851: Advanced Data Structures Spring 2012 Prof. Erik Demaine Lecture 18 April 26, 2012 1 Overview In the last lecture we introduced the concept of implicit, succinct, and compact data structures, and
6.851: Advanced Data Structures Spring 2012 Prof. Erik Demaine Lecture 18 April 26, 2012 1 Overview In the last lecture we introduced the concept of implicit, succinct, and compact data structures, and
On Compressing and Indexing Repetitive Sequences
 On Compressing and Indexing Repetitive Sequences Sebastian Kreft a,1,2, Gonzalo Navarro a,2 a Department of Computer Science, University of Chile Abstract We introduce LZ-End, a new member of the Lempel-Ziv
On Compressing and Indexing Repetitive Sequences Sebastian Kreft a,1,2, Gonzalo Navarro a,2 a Department of Computer Science, University of Chile Abstract We introduce LZ-End, a new member of the Lempel-Ziv
COMPRESSED INDEXING DATA STRUCTURES FOR BIOLOGICAL SEQUENCES
 COMPRESSED INDEXING DATA STRUCTURES FOR BIOLOGICAL SEQUENCES DO HUY HOANG (B.C.S. (Hons), NUS) A THESIS SUBMITTED FOR THE DEGREE OF DOCTOR OF PHILOSOPHY IN COMPUTER SCIENCE SCHOOL OF COMPUTING NATIONAL
COMPRESSED INDEXING DATA STRUCTURES FOR BIOLOGICAL SEQUENCES DO HUY HOANG (B.C.S. (Hons), NUS) A THESIS SUBMITTED FOR THE DEGREE OF DOCTOR OF PHILOSOPHY IN COMPUTER SCIENCE SCHOOL OF COMPUTING NATIONAL
Stronger Lempel-Ziv Based Compressed Text Indexing
 Stronger Lempel-Ziv Based Compressed Text Indexing Diego Arroyuelo 1, Gonzalo Navarro 1, and Kunihiko Sadakane 2 1 Dept. of Computer Science, Universidad de Chile, Blanco Encalada 2120, Santiago, Chile.
Stronger Lempel-Ziv Based Compressed Text Indexing Diego Arroyuelo 1, Gonzalo Navarro 1, and Kunihiko Sadakane 2 1 Dept. of Computer Science, Universidad de Chile, Blanco Encalada 2120, Santiago, Chile.
A Faster Grammar-Based Self-Index
 A Faster Grammar-Based Self-Index Travis Gagie 1 Pawe l Gawrychowski 2 Juha Kärkkäinen 3 Yakov Nekrich 4 Simon Puglisi 5 Aalto University Max-Planck-Institute für Informatik University of Helsinki University
A Faster Grammar-Based Self-Index Travis Gagie 1 Pawe l Gawrychowski 2 Juha Kärkkäinen 3 Yakov Nekrich 4 Simon Puglisi 5 Aalto University Max-Planck-Institute für Informatik University of Helsinki University
Self-Indexed Grammar-Based Compression
 Fundamenta Informaticae XXI (2001) 1001 1025 1001 IOS Press Self-Indexed Grammar-Based Compression Francisco Claude David R. Cheriton School of Computer Science University of Waterloo fclaude@cs.uwaterloo.ca
Fundamenta Informaticae XXI (2001) 1001 1025 1001 IOS Press Self-Indexed Grammar-Based Compression Francisco Claude David R. Cheriton School of Computer Science University of Waterloo fclaude@cs.uwaterloo.ca
COMP9319 Web Data Compression and Search. Lecture 2: Adaptive Huffman, BWT
 COMP9319 Web Data Compression and Search Lecture 2: daptive Huffman, BWT 1 Original readings Login to your cse account:! cd ~cs9319/papers! Original readings of each lecture will be placed there. 2 Course
COMP9319 Web Data Compression and Search Lecture 2: daptive Huffman, BWT 1 Original readings Login to your cse account:! cd ~cs9319/papers! Original readings of each lecture will be placed there. 2 Course
Advanced Text Indexing Techniques. Johannes Fischer
 Advanced ext Indexing echniques Johannes Fischer SS 2009 1 Suffix rees, -Arrays and -rays 1.1 Recommended Reading Dan Gusfield: Algorithms on Strings, rees, and Sequences. 1997. ambridge University Press,
Advanced ext Indexing echniques Johannes Fischer SS 2009 1 Suffix rees, -Arrays and -rays 1.1 Recommended Reading Dan Gusfield: Algorithms on Strings, rees, and Sequences. 1997. ambridge University Press,
Opportunistic Data Structures with Applications
 Opportunistic Data Structures with Applications Paolo Ferragina Giovanni Manzini Abstract There is an upsurging interest in designing succinct data structures for basic searching problems (see [23] and
Opportunistic Data Structures with Applications Paolo Ferragina Giovanni Manzini Abstract There is an upsurging interest in designing succinct data structures for basic searching problems (see [23] and
String Range Matching
 String Range Matching Juha Kärkkäinen, Dominik Kempa, and Simon J. Puglisi Department of Computer Science, University of Helsinki Helsinki, Finland firstname.lastname@cs.helsinki.fi Abstract. Given strings
String Range Matching Juha Kärkkäinen, Dominik Kempa, and Simon J. Puglisi Department of Computer Science, University of Helsinki Helsinki, Finland firstname.lastname@cs.helsinki.fi Abstract. Given strings
Optimal-Time Text Indexing in BWT-runs Bounded Space
 Optimal-Time Text Indexing in BWT-runs Bounded Space Travis Gagie Gonzalo Navarro Nicola Prezza Abstract Indexing highly repetitive texts such as genomic databases, software repositories and versioned
Optimal-Time Text Indexing in BWT-runs Bounded Space Travis Gagie Gonzalo Navarro Nicola Prezza Abstract Indexing highly repetitive texts such as genomic databases, software repositories and versioned
Breaking a Time-and-Space Barrier in Constructing Full-Text Indices
 Breaking a Time-and-Space Barrier in Constructing Full-Text Indices Wing-Kai Hon Kunihiko Sadakane Wing-Kin Sung Abstract Suffix trees and suffix arrays are the most prominent full-text indices, and their
Breaking a Time-and-Space Barrier in Constructing Full-Text Indices Wing-Kai Hon Kunihiko Sadakane Wing-Kin Sung Abstract Suffix trees and suffix arrays are the most prominent full-text indices, and their
Data Compression Techniques
 Data Compression Techniques Part 2: Text Compression Lecture 7: Burrows Wheeler Compression Juha Kärkkäinen 21.11.2017 1 / 16 Burrows Wheeler Transform The Burrows Wheeler transform (BWT) is a transformation
Data Compression Techniques Part 2: Text Compression Lecture 7: Burrows Wheeler Compression Juha Kärkkäinen 21.11.2017 1 / 16 Burrows Wheeler Transform The Burrows Wheeler transform (BWT) is a transformation
COMP9319 Web Data Compression and Search. Lecture 2: Adaptive Huffman, BWT
 COMP9319 Web Data Compression and Search Lecture 2: daptive Huffman, BWT 1 Original readings Login to your cse account: cd ~cs9319/papers Original readings of each lecture will be placed there. 2 Course
COMP9319 Web Data Compression and Search Lecture 2: daptive Huffman, BWT 1 Original readings Login to your cse account: cd ~cs9319/papers Original readings of each lecture will be placed there. 2 Course
Internal Pattern Matching Queries in a Text and Applications
 Internal Pattern Matching Queries in a Text and Applications Tomasz Kociumaka Jakub Radoszewski Wojciech Rytter Tomasz Waleń Abstract We consider several types of internal queries: questions about subwords
Internal Pattern Matching Queries in a Text and Applications Tomasz Kociumaka Jakub Radoszewski Wojciech Rytter Tomasz Waleń Abstract We consider several types of internal queries: questions about subwords
Optimal Dynamic Sequence Representations
 Optimal Dynamic Sequence Representations Gonzalo Navarro Yakov Nekrich Abstract We describe a data structure that supports access, rank and select queries, as well as symbol insertions and deletions, on
Optimal Dynamic Sequence Representations Gonzalo Navarro Yakov Nekrich Abstract We describe a data structure that supports access, rank and select queries, as well as symbol insertions and deletions, on
Fast Fully-Compressed Suffix Trees
 Fast Fully-Compressed Suffix Trees Gonzalo Navarro Department of Computer Science University of Chile, Chile gnavarro@dcc.uchile.cl Luís M. S. Russo INESC-ID / Instituto Superior Técnico Technical University
Fast Fully-Compressed Suffix Trees Gonzalo Navarro Department of Computer Science University of Chile, Chile gnavarro@dcc.uchile.cl Luís M. S. Russo INESC-ID / Instituto Superior Técnico Technical University
Theoretical aspects of ERa, the fastest practical suffix tree construction algorithm
 Theoretical aspects of ERa, the fastest practical suffix tree construction algorithm Matevž Jekovec University of Ljubljana Faculty of Computer and Information Science Oct 10, 2013 Text indexing problem
Theoretical aspects of ERa, the fastest practical suffix tree construction algorithm Matevž Jekovec University of Ljubljana Faculty of Computer and Information Science Oct 10, 2013 Text indexing problem
Practical Indexing of Repetitive Collections using Relative Lempel-Ziv
 Practical Indexing of Repetitive Collections using Relative Lempel-Ziv Gonzalo Navarro and Víctor Sepúlveda CeBiB Center for Biotechnology and Bioengineering, Chile Department of Computer Science, University
Practical Indexing of Repetitive Collections using Relative Lempel-Ziv Gonzalo Navarro and Víctor Sepúlveda CeBiB Center for Biotechnology and Bioengineering, Chile Department of Computer Science, University
Space-Efficient Construction Algorithm for Circular Suffix Tree
 Space-Efficient Construction Algorithm for Circular Suffix Tree Wing-Kai Hon, Tsung-Han Ku, Rahul Shah and Sharma Thankachan CPM2013 1 Outline Preliminaries and Motivation Circular Suffix Tree Our Indexes
Space-Efficient Construction Algorithm for Circular Suffix Tree Wing-Kai Hon, Tsung-Han Ku, Rahul Shah and Sharma Thankachan CPM2013 1 Outline Preliminaries and Motivation Circular Suffix Tree Our Indexes
arxiv: v1 [cs.ds] 8 Sep 2018
![arxiv: v1 [cs.ds] 8 Sep 2018](/thumbs/92/108222904.jpg "arxiv: v1 [cs.ds] 8 Sep 2018") Fully-Functional Suffix Trees and Optimal Text Searching in BWT-runs Bounded Space Travis Gagie 1,2, Gonzalo Navarro 2,3, and Nicola Prezza 4 1 EIT, Diego Portales University, Chile 2 Center for Biotechnology
Fully-Functional Suffix Trees and Optimal Text Searching in BWT-runs Bounded Space Travis Gagie 1,2, Gonzalo Navarro 2,3, and Nicola Prezza 4 1 EIT, Diego Portales University, Chile 2 Center for Biotechnology
2018/5/3. YU Xiangyu
 2018/5/3 YU Xiangyu yuxy@scut.edu.cn Entropy Huffman Code Entropy of Discrete Source Definition of entropy: If an information source X can generate n different messages x 1, x 2,, x i,, x n, then the
2018/5/3 YU Xiangyu yuxy@scut.edu.cn Entropy Huffman Code Entropy of Discrete Source Definition of entropy: If an information source X can generate n different messages x 1, x 2,, x i,, x n, then the
Lecture 4 : Adaptive source coding algorithms
 Lecture 4 : Adaptive source coding algorithms February 2, 28 Information Theory Outline 1. Motivation ; 2. adaptive Huffman encoding ; 3. Gallager and Knuth s method ; 4. Dictionary methods : Lempel-Ziv
Lecture 4 : Adaptive source coding algorithms February 2, 28 Information Theory Outline 1. Motivation ; 2. adaptive Huffman encoding ; 3. Gallager and Knuth s method ; 4. Dictionary methods : Lempel-Ziv
Computing Techniques for Parallel and Distributed Systems with an Application to Data Compression. Sergio De Agostino Sapienza University di Rome
 Computing Techniques for Parallel and Distributed Systems with an Application to Data Compression Sergio De Agostino Sapienza University di Rome Parallel Systems A parallel random access machine (PRAM)
Computing Techniques for Parallel and Distributed Systems with an Application to Data Compression Sergio De Agostino Sapienza University di Rome Parallel Systems A parallel random access machine (PRAM)
Succinct 2D Dictionary Matching with No Slowdown
 Succinct 2D Dictionary Matching with No Slowdown Shoshana Neuburger and Dina Sokol City University of New York Problem Definition Dictionary Matching Input: Dictionary D = P 1,P 2,...,P d containing d
Succinct 2D Dictionary Matching with No Slowdown Shoshana Neuburger and Dina Sokol City University of New York Problem Definition Dictionary Matching Input: Dictionary D = P 1,P 2,...,P d containing d
An Algorithmic Framework for Compression and Text Indexing
 An Algorithmic Framework for Compression and Text Indexing Roberto Grossi Ankur Gupta Jeffrey Scott Vitter Abstract We present a unified algorithmic framework to obtain nearly optimal space bounds for
An Algorithmic Framework for Compression and Text Indexing Roberto Grossi Ankur Gupta Jeffrey Scott Vitter Abstract We present a unified algorithmic framework to obtain nearly optimal space bounds for
Dynamic Programming. Shuang Zhao. Microsoft Research Asia September 5, Dynamic Programming. Shuang Zhao. Outline. Introduction.
 Microsoft Research Asia September 5, 2005 1 2 3 4 Section I What is? Definition is a technique for efficiently recurrence computing by storing partial results. In this slides, I will NOT use too many formal
Microsoft Research Asia September 5, 2005 1 2 3 4 Section I What is? Definition is a technique for efficiently recurrence computing by storing partial results. In this slides, I will NOT use too many formal
Compact Data Strutures
 (To compress is to Conquer) Compact Data Strutures Antonio Fariña, Javier D. Fernández and Miguel A. Martinez-Prieto 3rd KEYSTONE Training School Keyword search in Big Linked Data 23 TH AUGUST 2017 Agenda
(To compress is to Conquer) Compact Data Strutures Antonio Fariña, Javier D. Fernández and Miguel A. Martinez-Prieto 3rd KEYSTONE Training School Keyword search in Big Linked Data 23 TH AUGUST 2017 Agenda
Streaming and communication complexity of Hamming distance
 Streaming and communication complexity of Hamming distance Tatiana Starikovskaya IRIF, Université Paris-Diderot (Joint work with Raphaël Clifford, ICALP 16) Approximate pattern matching Problem Pattern
Streaming and communication complexity of Hamming distance Tatiana Starikovskaya IRIF, Université Paris-Diderot (Joint work with Raphaël Clifford, ICALP 16) Approximate pattern matching Problem Pattern
arxiv: v1 [cs.ds] 22 Nov 2012
![arxiv: v1 [cs.ds] 22 Nov 2012](/thumbs/92/110949120.jpg "arxiv: v1 [cs.ds] 22 Nov 2012") Faster Compact Top-k Document Retrieval Roberto Konow and Gonzalo Navarro Department of Computer Science, University of Chile {rkonow,gnavarro}@dcc.uchile.cl arxiv:1211.5353v1 [cs.ds] 22 Nov 2012 Abstract:
Faster Compact Top-k Document Retrieval Roberto Konow and Gonzalo Navarro Department of Computer Science, University of Chile {rkonow,gnavarro}@dcc.uchile.cl arxiv:1211.5353v1 [cs.ds] 22 Nov 2012 Abstract:
Linear-Space Alignment
 Linear-Space Alignment Subsequences and Substrings Definition A string x is a substring of a string x, if x = ux v for some prefix string u and suffix string v (similarly, x = x i x j, for some 1 i j x
Linear-Space Alignment Subsequences and Substrings Definition A string x is a substring of a string x, if x = ux v for some prefix string u and suffix string v (similarly, x = x i x j, for some 1 i j x
Forbidden Patterns. {vmakinen leena.salmela
 Forbidden Patterns Johannes Fischer 1,, Travis Gagie 2,, Tsvi Kopelowitz 3, Moshe Lewenstein 4, Veli Mäkinen 5,, Leena Salmela 5,, and Niko Välimäki 5, 1 KIT, Karlsruhe, Germany, johannes.fischer@kit.edu
Forbidden Patterns Johannes Fischer 1,, Travis Gagie 2,, Tsvi Kopelowitz 3, Moshe Lewenstein 4, Veli Mäkinen 5,, Leena Salmela 5,, and Niko Välimäki 5, 1 KIT, Karlsruhe, Germany, johannes.fischer@kit.edu
New Lower and Upper Bounds for Representing Sequences
 New Lower and Upper Bounds for Representing Sequences Djamal Belazzougui 1 and Gonzalo Navarro 2 1 LIAFA, Univ. Paris Diderot - Paris 7, France. dbelaz@liafa.jussieu.fr 2 Department of Computer Science,
New Lower and Upper Bounds for Representing Sequences Djamal Belazzougui 1 and Gonzalo Navarro 2 1 LIAFA, Univ. Paris Diderot - Paris 7, France. dbelaz@liafa.jussieu.fr 2 Department of Computer Science,
Source Coding. Master Universitario en Ingeniería de Telecomunicación. I. Santamaría Universidad de Cantabria
 Source Coding Master Universitario en Ingeniería de Telecomunicación I. Santamaría Universidad de Cantabria Contents Introduction Asymptotic Equipartition Property Optimal Codes (Huffman Coding) Universal
Source Coding Master Universitario en Ingeniería de Telecomunicación I. Santamaría Universidad de Cantabria Contents Introduction Asymptotic Equipartition Property Optimal Codes (Huffman Coding) Universal
Compact Indexes for Flexible Top-k Retrieval
 Compact Indexes for Flexible Top-k Retrieval Simon Gog Matthias Petri Institute of Theoretical Informatics, Karlsruhe Institute of Technology Computing and Information Systems, The University of Melbourne
Compact Indexes for Flexible Top-k Retrieval Simon Gog Matthias Petri Institute of Theoretical Informatics, Karlsruhe Institute of Technology Computing and Information Systems, The University of Melbourne
Read Mapping. Burrows Wheeler Transform and Reference Based Assembly. Genomics: Lecture #5 WS 2014/2015
 Mapping Burrows Wheeler and Reference Based Assembly Institut für Medizinische Genetik und Humangenetik Charité Universitätsmedizin Berlin Genomics: Lecture #5 WS 2014/2015 Today Burrows Wheeler FM index
Mapping Burrows Wheeler and Reference Based Assembly Institut für Medizinische Genetik und Humangenetik Charité Universitätsmedizin Berlin Genomics: Lecture #5 WS 2014/2015 Today Burrows Wheeler FM index
UNIT I INFORMATION THEORY. I k log 2
 UNIT I INFORMATION THEORY Claude Shannon 1916-2001 Creator of Information Theory, lays the foundation for implementing logic in digital circuits as part of his Masters Thesis! (1939) and published a paper
UNIT I INFORMATION THEORY Claude Shannon 1916-2001 Creator of Information Theory, lays the foundation for implementing logic in digital circuits as part of his Masters Thesis! (1939) and published a paper
An O(N) Semi-Predictive Universal Encoder via the BWT
 Semi-Predictive Universal Encoder via the BWT") An O(N) Semi-Predictive Universal Encoder via the BWT Dror Baron and Yoram Bresler Abstract We provide an O(N) algorithm for a non-sequential semi-predictive encoder whose pointwise redundancy with respect
An O(N) Semi-Predictive Universal Encoder via the BWT Dror Baron and Yoram Bresler Abstract We provide an O(N) algorithm for a non-sequential semi-predictive encoder whose pointwise redundancy with respect
Integer Sorting on the word-ram
 Integer Sorting on the word-rm Uri Zwick Tel viv University May 2015 Last updated: June 30, 2015 Integer sorting Memory is composed of w-bit words. rithmetical, logical and shift operations on w-bit words
Integer Sorting on the word-rm Uri Zwick Tel viv University May 2015 Last updated: June 30, 2015 Integer sorting Memory is composed of w-bit words. rithmetical, logical and shift operations on w-bit words
Fast String Kernels. Alexander J. Smola Machine Learning Group, RSISE The Australian National University Canberra, ACT 0200
 Fast String Kernels Alexander J. Smola Machine Learning Group, RSISE The Australian National University Canberra, ACT 0200 Alex.Smola@anu.edu.au joint work with S.V.N. Vishwanathan Slides (soon) available
Fast String Kernels Alexander J. Smola Machine Learning Group, RSISE The Australian National University Canberra, ACT 0200 Alex.Smola@anu.edu.au joint work with S.V.N. Vishwanathan Slides (soon) available
Efficient Fully-Compressed Sequence Representations
 Algorithmica (2014) 69:232 268 DOI 10.1007/s00453-012-9726-3 Efficient Fully-Compressed Sequence Representations Jérémy Barbay Francisco Claude Travis Gagie Gonzalo Navarro Yakov Nekrich Received: 4 February
Algorithmica (2014) 69:232 268 DOI 10.1007/s00453-012-9726-3 Efficient Fully-Compressed Sequence Representations Jérémy Barbay Francisco Claude Travis Gagie Gonzalo Navarro Yakov Nekrich Received: 4 February
Burrows-Wheeler Transforms in Linear Time and Linear Bits
 Burrows-Wheeler Transforms in Linear Time and Linear Bits Russ Cox (following Hon, Sadakane, Sung, Farach, and others) 18.417 Final Project BWT in Linear Time and Linear Bits Three main parts to the result.
Burrows-Wheeler Transforms in Linear Time and Linear Bits Russ Cox (following Hon, Sadakane, Sung, Farach, and others) 18.417 Final Project BWT in Linear Time and Linear Bits Three main parts to the result.
Define M to be a binary n by m matrix such that:
 The Shift-And Method Define M to be a binary n by m matrix such that: M(i,j) = iff the first i characters of P exactly match the i characters of T ending at character j. M(i,j) = iff P[.. i] T[j-i+.. j]
The Shift-And Method Define M to be a binary n by m matrix such that: M(i,j) = iff the first i characters of P exactly match the i characters of T ending at character j. M(i,j) = iff P[.. i] T[j-i+.. j]
Data Compression Techniques
 Data Compression Techniques Part 2: Text Compression Lecture 5: Context-Based Compression Juha Kärkkäinen 14.11.2017 1 / 19 Text Compression We will now look at techniques for text compression. These techniques
Data Compression Techniques Part 2: Text Compression Lecture 5: Context-Based Compression Juha Kärkkäinen 14.11.2017 1 / 19 Text Compression We will now look at techniques for text compression. These techniques
A Four-Stage Algorithm for Updating a Burrows-Wheeler Transform
 A Four-Stage Algorithm for Updating a Burrows-Wheeler ransform M. Salson a,1,. Lecroq a, M. Léonard a, L. Mouchard a,b, a Université de Rouen, LIIS EA 4108, 76821 Mont Saint Aignan, France b Algorithm
A Four-Stage Algorithm for Updating a Burrows-Wheeler ransform M. Salson a,1,. Lecroq a, M. Léonard a, L. Mouchard a,b, a Université de Rouen, LIIS EA 4108, 76821 Mont Saint Aignan, France b Algorithm
CHAPTER 8 COMPRESSION ENTROPY ESTIMATION OF HEART RATE VARIABILITY AND COMPUTATION OF ITS RENORMALIZED ENTROPY
 108 CHAPTER 8 COMPRESSION ENTROPY ESTIMATION OF HEART RATE VARIABILITY AND COMPUTATION OF ITS RENORMALIZED ENTROPY 8.1 INTRODUCTION Klimontovich s S-theorem offers an approach to compare two different
108 CHAPTER 8 COMPRESSION ENTROPY ESTIMATION OF HEART RATE VARIABILITY AND COMPUTATION OF ITS RENORMALIZED ENTROPY 8.1 INTRODUCTION Klimontovich s S-theorem offers an approach to compare two different
Space-Efficient Re-Pair Compression
 Space-Efficient Re-Pair Compression Philip Bille, Inge Li Gørtz, and Nicola Prezza Technical University of Denmark, DTU Compute {phbi,inge,npre}@dtu.dk Abstract Re-Pair [5] is an effective grammar-based
Space-Efficient Re-Pair Compression Philip Bille, Inge Li Gørtz, and Nicola Prezza Technical University of Denmark, DTU Compute {phbi,inge,npre}@dtu.dk Abstract Re-Pair [5] is an effective grammar-based
Asymptotic Optimal Lossless Compression via the CSE Technique
 2011 First International Conference on Data Compression, Communications and Processing Asymptotic Optimal Lossless Compression via the CSE Technique Hidetoshi Yokoo Department of Computer Science Gunma
2011 First International Conference on Data Compression, Communications and Processing Asymptotic Optimal Lossless Compression via the CSE Technique Hidetoshi Yokoo Department of Computer Science Gunma
At the Roots of Dictionary Compression: String Attractors
 At the Roots of Dictionary Compression: String Attractors Dominik Kempa Department of Computer Science, University of Helsinki Helsinki, Finland dkempa@cs.helsinki.fi ABSTRACT A well-known fact in the
At the Roots of Dictionary Compression: String Attractors Dominik Kempa Department of Computer Science, University of Helsinki Helsinki, Finland dkempa@cs.helsinki.fi ABSTRACT A well-known fact in the
Data Compression Using a Sort-Based Context Similarity Measure
 Data Compression Using a Sort-Based Context Similarity easure HIDETOSHI YOKOO Department of Computer Science, Gunma University, Kiryu, Gunma 76, Japan Email: yokoo@cs.gunma-u.ac.jp Every symbol in the
Data Compression Using a Sort-Based Context Similarity easure HIDETOSHI YOKOO Department of Computer Science, Gunma University, Kiryu, Gunma 76, Japan Email: yokoo@cs.gunma-u.ac.jp Every symbol in the
A Space-Efficient Frameworks for Top-k String Retrieval
 A Space-Efficient Frameworks for Top-k String Retrieval Wing-Kai Hon, National Tsing Hua University Rahul Shah, Louisiana State University Sharma V. Thankachan, Louisiana State University Jeffrey Scott
A Space-Efficient Frameworks for Top-k String Retrieval Wing-Kai Hon, National Tsing Hua University Rahul Shah, Louisiana State University Sharma V. Thankachan, Louisiana State University Jeffrey Scott
Complexity Theory VU , SS The Polynomial Hierarchy. Reinhard Pichler
 Complexity Theory Complexity Theory VU 181.142, SS 2018 6. The Polynomial Hierarchy Reinhard Pichler Institut für Informationssysteme Arbeitsbereich DBAI Technische Universität Wien 15 May, 2018 Reinhard
Complexity Theory Complexity Theory VU 181.142, SS 2018 6. The Polynomial Hierarchy Reinhard Pichler Institut für Informationssysteme Arbeitsbereich DBAI Technische Universität Wien 15 May, 2018 Reinhard
Outline. Complexity Theory EXACT TSP. The Class DP. Definition. Problem EXACT TSP. Complexity of EXACT TSP. Proposition VU 181.
 Complexity Theory Complexity Theory Outline Complexity Theory VU 181.142, SS 2018 6. The Polynomial Hierarchy Reinhard Pichler Institut für Informationssysteme Arbeitsbereich DBAI Technische Universität
Complexity Theory Complexity Theory Outline Complexity Theory VU 181.142, SS 2018 6. The Polynomial Hierarchy Reinhard Pichler Institut für Informationssysteme Arbeitsbereich DBAI Technische Universität
Università degli studi di Udine
 Università degli studi di Udine Computing LZ77 in Run-Compressed Space This is a pre print version of the following article: Original Computing LZ77 in Run-Compressed Space / Policriti, Alberto; Prezza,
Università degli studi di Udine Computing LZ77 in Run-Compressed Space This is a pre print version of the following article: Original Computing LZ77 in Run-Compressed Space / Policriti, Alberto; Prezza,
arxiv: v3 [cs.ds] 6 Sep 2018
![arxiv: v3 [cs.ds] 6 Sep 2018](/thumbs/94/121093748.jpg "arxiv: v3 [cs.ds] 6 Sep 2018") Universal Compressed Text Indexing 1 Gonzalo Navarro 2 arxiv:1803.09520v3 [cs.ds] 6 Sep 2018 Abstract Center for Biotechnology and Bioengineering (CeBiB), Department of Computer Science, University of
Universal Compressed Text Indexing 1 Gonzalo Navarro 2 arxiv:1803.09520v3 [cs.ds] 6 Sep 2018 Abstract Center for Biotechnology and Bioengineering (CeBiB), Department of Computer Science, University of
Bandwidth: Communicate large complex & highly detailed 3D models through lowbandwidth connection (e.g. VRML over the Internet)
") Compression Motivation Bandwidth: Communicate large complex & highly detailed 3D models through lowbandwidth connection (e.g. VRML over the Internet) Storage: Store large & complex 3D models (e.g. 3D scanner
Compression Motivation Bandwidth: Communicate large complex & highly detailed 3D models through lowbandwidth connection (e.g. VRML over the Internet) Storage: Store large & complex 3D models (e.g. 3D scanner
On Universal Types. Gadiel Seroussi Hewlett-Packard Laboratories Palo Alto, California, USA. University of Minnesota, September 14, 2004
 On Universal Types Gadiel Seroussi Hewlett-Packard Laboratories Palo Alto, California, USA University of Minnesota, September 14, 2004 Types for Parametric Probability Distributions A = finite alphabet,
On Universal Types Gadiel Seroussi Hewlett-Packard Laboratories Palo Alto, California, USA University of Minnesota, September 14, 2004 Types for Parametric Probability Distributions A = finite alphabet,
Converting SLP to LZ78 in almost Linear Time
 CPM 2013 Converting SLP to LZ78 in almost Linear Time Hideo Bannai 1, Paweł Gawrychowski 2, Shunsuke Inenaga 1, Masayuki Takeda 1 1. Kyushu University 2. Max-Planck-Institut für Informatik Recompress SLP
CPM 2013 Converting SLP to LZ78 in almost Linear Time Hideo Bannai 1, Paweł Gawrychowski 2, Shunsuke Inenaga 1, Masayuki Takeda 1 1. Kyushu University 2. Max-Planck-Institut für Informatik Recompress SLP
ON THE BIT-COMPLEXITY OF LEMPEL-ZIV COMPRESSION
 ON THE BIT-COMPLEXITY OF LEMPEL-ZIV COMPRESSION PAOLO FERRAGINA, IGOR NITTO, AND ROSSANO VENTURINI Abstract. One of the most famous and investigated lossless data-compression schemes is the one introduced
ON THE BIT-COMPLEXITY OF LEMPEL-ZIV COMPRESSION PAOLO FERRAGINA, IGOR NITTO, AND ROSSANO VENTURINI Abstract. One of the most famous and investigated lossless data-compression schemes is the one introduced
The Burrows-Wheeler Transform: Theory and Practice
 The Burrows-Wheeler Transform: Theory and Practice Giovanni Manzini 1,2 1 Dipartimento di Scienze e Tecnologie Avanzate, Università del Piemonte Orientale Amedeo Avogadro, I-15100 Alessandria, Italy. 2
The Burrows-Wheeler Transform: Theory and Practice Giovanni Manzini 1,2 1 Dipartimento di Scienze e Tecnologie Avanzate, Università del Piemonte Orientale Amedeo Avogadro, I-15100 Alessandria, Italy. 2
String Searching with Ranking Constraints and Uncertainty
 Louisiana State University LSU Digital Commons LSU Doctoral Dissertations Graduate School 2015 String Searching with Ranking Constraints and Uncertainty Sudip Biswas Louisiana State University and Agricultural
Louisiana State University LSU Digital Commons LSU Doctoral Dissertations Graduate School 2015 String Searching with Ranking Constraints and Uncertainty Sudip Biswas Louisiana State University and Agricultural
Inverting the Burrows-Wheeler Transform
 FUNCTIONAL PEARL Inverting the Burrows-Wheeler Transform Richard Bird and Shin-Cheng Mu 1 Programming Research Group, Oxford University Wolfson Building, Parks Road, Oxford, OX1 3QD, UK Abstract The objective
FUNCTIONAL PEARL Inverting the Burrows-Wheeler Transform Richard Bird and Shin-Cheng Mu 1 Programming Research Group, Oxford University Wolfson Building, Parks Road, Oxford, OX1 3QD, UK Abstract The objective
arxiv: v2 [cs.ds] 8 Apr 2016
![arxiv: v2 [cs.ds] 8 Apr 2016](/thumbs/87/96775989.jpg "arxiv: v2 [cs.ds] 8 Apr 2016") Optimal Dynamic Strings Paweł Gawrychowski 1, Adam Karczmarz 1, Tomasz Kociumaka 1, Jakub Łącki 2, and Piotr Sankowski 1 1 Institute of Informatics, University of Warsaw, Poland [gawry,a.karczmarz,kociumaka,sank]@mimuw.edu.pl
Optimal Dynamic Strings Paweł Gawrychowski 1, Adam Karczmarz 1, Tomasz Kociumaka 1, Jakub Łącki 2, and Piotr Sankowski 1 1 Institute of Informatics, University of Warsaw, Poland [gawry,a.karczmarz,kociumaka,sank]@mimuw.edu.pl
String Indexing for Patterns with Wildcards
 MASTER S THESIS String Indexing for Patterns with Wildcards Hjalte Wedel Vildhøj and Søren Vind Technical University of Denmark August 8, 2011 Abstract We consider the problem of indexing a string t of
MASTER S THESIS String Indexing for Patterns with Wildcards Hjalte Wedel Vildhøj and Søren Vind Technical University of Denmark August 8, 2011 Abstract We consider the problem of indexing a string t of
Notes on Logarithmic Lower Bounds in the Cell Probe Model
 Notes on Logarithmic Lower Bounds in the Cell Probe Model Kevin Zatloukal November 10, 2010 1 Overview Paper is by Mihai Pâtraşcu and Erik Demaine. Both were at MIT at the time. (Mihai is now at AT&T Labs.)
Notes on Logarithmic Lower Bounds in the Cell Probe Model Kevin Zatloukal November 10, 2010 1 Overview Paper is by Mihai Pâtraşcu and Erik Demaine. Both were at MIT at the time. (Mihai is now at AT&T Labs.)
Computation Theory Finite Automata
 Computation Theory Dept. of Computing ITT Dublin October 14, 2010 Computation Theory I 1 We would like a model that captures the general nature of computation Consider two simple problems: 2 Design a program
Computation Theory Dept. of Computing ITT Dublin October 14, 2010 Computation Theory I 1 We would like a model that captures the general nature of computation Consider two simple problems: 2 Design a program
Succinct Data Structures for Text and Information Retrieval
 Succinct Data Structures for Text and Information Retrieval Simon Gog 1 Matthias Petri 2 1 Institute of Theoretical Informatics Karslruhe Insitute of Technology 2 Computing and Information Systems The
Succinct Data Structures for Text and Information Retrieval Simon Gog 1 Matthias Petri 2 1 Institute of Theoretical Informatics Karslruhe Insitute of Technology 2 Computing and Information Systems The
Text Compression. Jayadev Misra The University of Texas at Austin December 5, A Very Incomplete Introduction to Information Theory 2
 Text Compression Jayadev Misra The University of Texas at Austin December 5, 2003 Contents 1 Introduction 1 2 A Very Incomplete Introduction to Information Theory 2 3 Huffman Coding 5 3.1 Uniquely Decodable
Text Compression Jayadev Misra The University of Texas at Austin December 5, 2003 Contents 1 Introduction 1 2 A Very Incomplete Introduction to Information Theory 2 3 Huffman Coding 5 3.1 Uniquely Decodable
A Repetitive Corpus Testbed
 Chapter 3 A Repetitive Corpus Testbed In this chapter we present a corpus of repetitive texts. These texts are categorized according to the source they come from into the following: Artificial Texts, Pseudo-
Chapter 3 A Repetitive Corpus Testbed In this chapter we present a corpus of repetitive texts. These texts are categorized according to the source they come from into the following: Artificial Texts, Pseudo-
Jumbled String Matching: Motivations, Variants, Algorithms
 Jumbled String Matching: Motivations, Variants, Algorithms Zsuzsanna Lipták University of Verona (Italy) Workshop Combinatorial structures for sequence analysis in bioinformatics Milano-Bicocca, 27 Nov
Jumbled String Matching: Motivations, Variants, Algorithms Zsuzsanna Lipták University of Verona (Italy) Workshop Combinatorial structures for sequence analysis in bioinformatics Milano-Bicocca, 27 Nov
Bloom Filters, Minhashes, and Other Random Stuff
 Bloom Filters, Minhashes, and Other Random Stuff Brian Brubach University of Maryland, College Park StringBio 2018, University of Central Florida What? Probabilistic Space-efficient Fast Not exact Why?
Bloom Filters, Minhashes, and Other Random Stuff Brian Brubach University of Maryland, College Park StringBio 2018, University of Central Florida What? Probabilistic Space-efficient Fast Not exact Why?
Fast Sorting and Selection. A Lower Bound for Worst Case
 Presentation for use with the textbook, Algorithm Design and Applications, by M. T. Goodrich and R. Tamassia, Wiley, 0 Fast Sorting and Selection USGS NEIC. Public domain government image. A Lower Bound
Presentation for use with the textbook, Algorithm Design and Applications, by M. T. Goodrich and R. Tamassia, Wiley, 0 Fast Sorting and Selection USGS NEIC. Public domain government image. A Lower Bound
Data Structures in Java
 Data Structures in Java Lecture 20: Algorithm Design Techniques 12/2/2015 Daniel Bauer 1 Algorithms and Problem Solving Purpose of algorithms: find solutions to problems. Data Structures provide ways of
Data Structures in Java Lecture 20: Algorithm Design Techniques 12/2/2015 Daniel Bauer 1 Algorithms and Problem Solving Purpose of algorithms: find solutions to problems. Data Structures provide ways of
A simpler analysis of Burrows Wheeler-based compression
 Theoretical Computer Science 387 (2007) 220 235 www.elsevier.com/locate/tcs A simpler analysis of Burrows Wheeler-based compression Haim Kaplan, Shir Landau, Elad Verbin School of Computer Science, Tel
Theoretical Computer Science 387 (2007) 220 235 www.elsevier.com/locate/tcs A simpler analysis of Burrows Wheeler-based compression Haim Kaplan, Shir Landau, Elad Verbin School of Computer Science, Tel
Module 5 EMBEDDED WAVELET CODING. Version 2 ECE IIT, Kharagpur
 Module 5 EMBEDDED WAVELET CODING Lesson 13 Zerotree Approach. Instructional Objectives At the end of this lesson, the students should be able to: 1. Explain the principle of embedded coding. 2. Show the
Module 5 EMBEDDED WAVELET CODING Lesson 13 Zerotree Approach. Instructional Objectives At the end of this lesson, the students should be able to: 1. Explain the principle of embedded coding. 2. Show the
Simple Compression Code Supporting Random Access and Fast String Matching
 Simple Compression Code Supporting Random Access and Fast String Matching Kimmo Fredriksson and Fedor Nikitin Department of Computer Science and Statistics, University of Joensuu PO Box 111, FIN 80101
Simple Compression Code Supporting Random Access and Fast String Matching Kimmo Fredriksson and Fedor Nikitin Department of Computer Science and Statistics, University of Joensuu PO Box 111, FIN 80101
Dictionary Matching in Elastic-Degenerate Texts with Applications in Searching VCF Files On-line
 Dictionary Matching in Elastic-Degenerate Texts with Applications in Searching VF Files On-line MatBio 18 Solon P. Pissis and Ahmad Retha King s ollege London 02-Aug-2018 Solon P. Pissis and Ahmad Retha
Dictionary Matching in Elastic-Degenerate Texts with Applications in Searching VF Files On-line MatBio 18 Solon P. Pissis and Ahmad Retha King s ollege London 02-Aug-2018 Solon P. Pissis and Ahmad Retha
Data Compression Techniques
 Data Compression Techniques Part 1: Entropy Coding Lecture 4: Asymmetric Numeral Systems Juha Kärkkäinen 08.11.2017 1 / 19 Asymmetric Numeral Systems Asymmetric numeral systems (ANS) is a recent entropy
Data Compression Techniques Part 1: Entropy Coding Lecture 4: Asymmetric Numeral Systems Juha Kärkkäinen 08.11.2017 1 / 19 Asymmetric Numeral Systems Asymmetric numeral systems (ANS) is a recent entropy
CS 455/555: Mathematical preliminaries
 CS 455/555: Mathematical preliminaries Stefan D. Bruda Winter 2019 SETS AND RELATIONS Sets: Operations: intersection, union, difference, Cartesian product Big, powerset (2 A ) Partition (π 2 A, π, i j
CS 455/555: Mathematical preliminaries Stefan D. Bruda Winter 2019 SETS AND RELATIONS Sets: Operations: intersection, union, difference, Cartesian product Big, powerset (2 A ) Partition (π 2 A, π, i j
SUCCINCT DATA STRUCTURES
 SUCCINCT DATA STRUCTURES by Ankur Gupta Department of Computer Science Duke University Date: Approved: Jeffrey Scott Vitter, Supervisor Pankaj Agarwal Roberto Grossi Xiaobai Sun Dissertation submitted
SUCCINCT DATA STRUCTURES by Ankur Gupta Department of Computer Science Duke University Date: Approved: Jeffrey Scott Vitter, Supervisor Pankaj Agarwal Roberto Grossi Xiaobai Sun Dissertation submitted