Optimization Methods
|
|
|
- Conrad Hawkins
- 5 years ago
- Views:
Transcription
1 Optimization Methods
2 Categorization of Optimization Problems Continuous Optimization Discrete Optimization Combinatorial Optimization Variational Optimization Common Optimization Concepts in Computer Vision Energy Minimization Graphs Markov Random Fields Several general approaches to optimization are as follows: Analytical methods Graphical methods Experimental methods Numerical methods Several branches of mathematical programming have evolved, as follows: Linear programming Integer programming Quadratic programming Nonlinear programming Dynamic programming
3 1. THE OPTIMIZATION PROBLEM 1.1 Introduction 1.2 The Basic Optimization Problem 2. BASIC PRINCIPLES 2.1 Introduction 2.2 Gradient Information 3. GENERAL PROPERTIES OF ALGORITHMS 3.5 Descent Functions 3.6 Global Convergence 3.7 Rates of Convergence 4. ONE-DIMENSIONAL OPTIMIZATION 4.3 Fibonacci Search 4.4 Golden-Section Search2 4.5 Quadratic Interpolation Method 5. BASIC MULTIDIMENSIONAL GRADIENT METHODS 5.1 Introduction 5.2 Steepest-Descent Method 5.3 Newton Method 5.4 Gauss-Newton Method
4 CONJUGATE-DIRECTION METHODS 6.1 Introduction 6.2 Conjugate Directions 6.3 Basic Conjugate-Directions Method 6.4 Conjugate-Gradient Method 6.5 Minimization of Nonquadratic Functions QUASI-NEWTON METHODS 7.1 Introduction 7.2 The Basic Quasi-Newton Approach MINIMAX METHODS 8.1 Introduction 8.2 Problem Formulation 8.3 Minimax Algorithms APPLICATIONS OF UNCONSTRAINED OPTIMIZATION 9.1 Introduction 9.2 Point-Pattern Matching
5 FUNDAMENTALS OF CONSTRAINED OPTIMIZATION 10.1 Introduction 10.2 Constraints LINEAR PROGRAMMING PART I: THE SIMPLEX METHOD 11.1 Introduction 11.2 General Properties 11.3 Simplex Method LINEAR PROGRAMMING PART I: THE SIMPLEX METHOD 11.1 Introduction 11.2 General Properties 11.3 Simplex Method QUADRATIC AND CONVEX PROGRAMMING 13.1 Introduction 13.2 Convex QP Problems with Equality Constraints 13.3 Active-Set Methods for Strictly Convex QP Problems GENERAL NONLINEAR OPTIMIZATION PROBLEMS 15.1 Introduction 15.2 Sequential Quadratic Programming Methods
 Our aim is to find values of")

 it is equivalent to seeking a")
6 Problem specification Suppose we have a cost function (or objective function) Our aim is to find values of the parameters (decision variables) x that minimize this function Subject to the following constraints: equality: nonequality: If we seek a maximum of f(x) (profit function) it is equivalent to seeking a minimum of f(x)


7 Books to read Practical Optimization Philip E. Gill, Walter Murray, and Margaret H. Wright, Academic Press, 1981 Practical Optimization: Algorithms and Engineering Applications Andreas Antoniou and Wu-Sheng Lu 2007 Both cover unconstrained and constrained optimization. Very clear and comprehensive.

 www.nrbook.com NEOS Guide www-fp.mcs.anl.")
8 Further reading and web resources Numerical Recipes in C (or C++) : The Art of Scientific Computing William H. Press, Brian P. Flannery, Saul A. Teukolsky, William T. Vetterling Good chapter on optimization Available on line at (1992 ed.) (2007 ed.) NEOS Guide www-fp.mcs.anl.gov/otc/guide/ This powerpoint presentation
9 Introductory Items in OPTIMIZATION - Category of Optimization methods - Constrained vs Unconstrained - Feasible Region Gradient and Taylor Series Expansion Necessary and Sufficient Conditions Saddle Point Convex/concave functions 1-D search Dichotomous, Fibonacci Golden Section, DSC; Steepest Descent; Newton; Gauss-Newton Conjugate Gradient; Quasi-Newton; Minimax; Lagrange Multiplier; Simplex; Prinal-Dual, Quadratic programming; Semi-definite;
10 Types of minima f(x) strong local minimum weak local minimum strong global minimum strong local minimum feasible region x which of the minima is found depends on the starting point such minima often occur in real applications
 Approximation methods 1. Polynomial interpolation 2.")
11 Unconstrained univariate optimization Assume we can start close to the global minimum How to determine the minimum? Search methods (Dichotomous, Fibonacci, Golden-Section) Approximation methods 1. Polynomial interpolation 2. Newton method Combination of both (alg. of Davies, Swann, and Campey)
12 Search methods Start with the interval ( bracket ) [x L, x U ] such that the minimum x* lies inside. Evaluate f(x) at two point inside the bracket. Reduce the bracket. Repeat the process. Can be applied to any function and differentiability is not essential.
13 XL XU X1 Criteria 0 1 1/2 FA > FB 1/2 1 3/4 FA < FB 1/2 3/4 5/8 FA < FB 1/2 5/8 9/16 FA > FB 9/16 5/8 19/32 FA < FB 9/16 19/32 37/64 XL XU RANGE /2 1 1/2 1/2 3/4 1/4 1/2 5/8 1/8 9/16 5/8 1/16 9/16 19/32 1/32
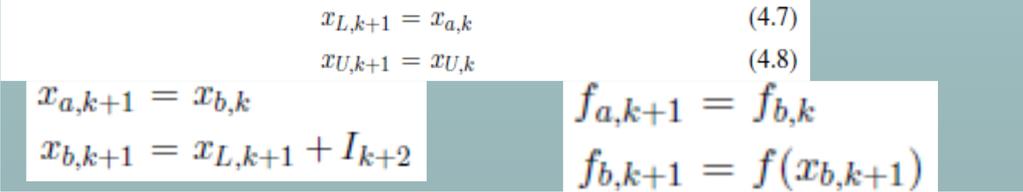
14


15

16
17


18
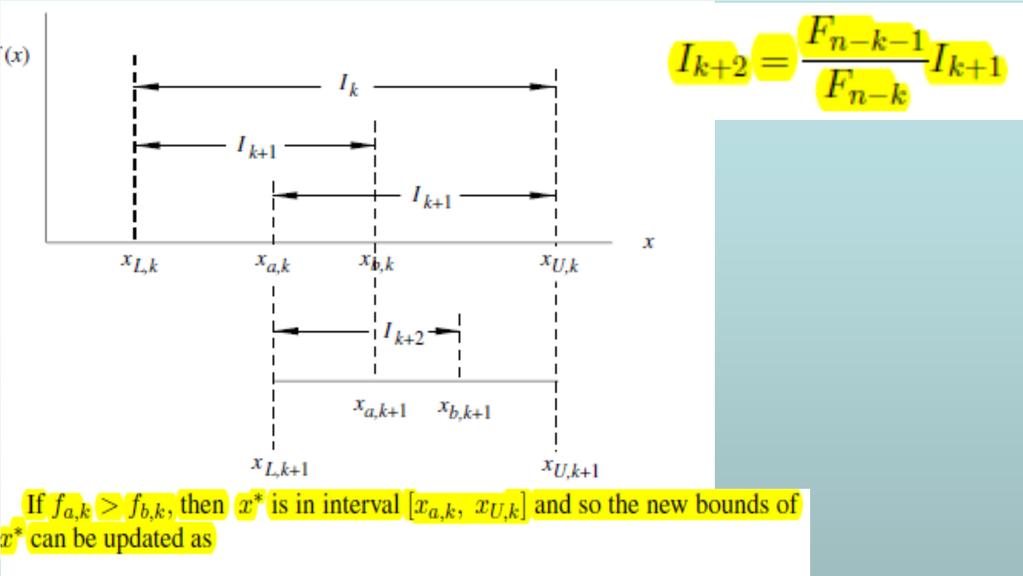
19 Search methods x U x L x L x L x x U U x L Dichotomous Fibonacci: I k+5 I k+4 I k+3 I k+2 I k+1 I k x L x L x U x U Golden-Section Search divides intervals by K =
20

21 1-D search
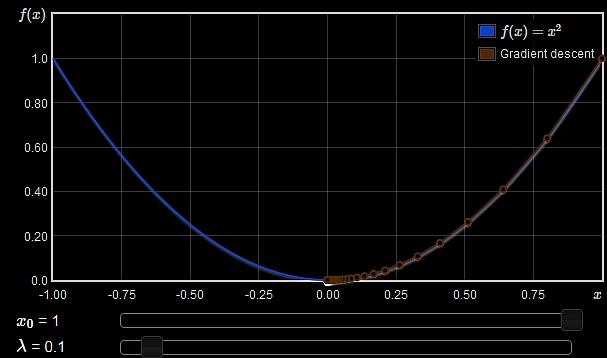
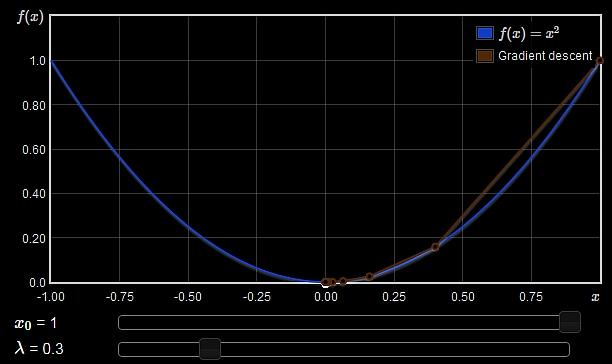
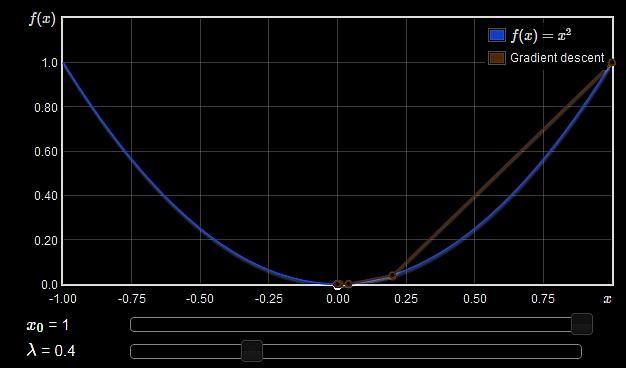
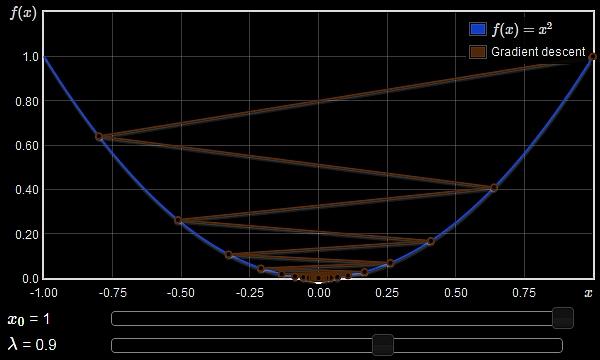
22 1D function As an example consider the function (assume we do not know the actual function expression from now on)
23 Gradient descent Given a starting location, x 0, examine df/dx and move in the downhill direction to generate a new estimate, x 1 = x 0 + δx How to determine the step size δx?
24 Polynomial interpolation Bracket the minimum. Fit a quadratic or cubic polynomial which interpolates f(x) at some points in the interval. Jump to the (easily obtained) minimum of the polynomial. Throw away the worst point and repeat the process.
25 Polynomial interpolation Quadratic interpolation using 3 points, 2 iterations Other methods to interpolate? 2 points and one gradient Cubic interpolation


26 Newton method Fit a quadratic approximation to f(x) using both gradient and curvature information at x. Expand f(x) locally using a Taylor series. Find the δx which minimizes this local quadratic approximation. Update x.
27 Newton method avoids the need to bracket the root quadratic convergence (decimal accuracy doubles at every iteration)
28 Newton method Global convergence of Newton s method is poor. Often fails if the starting point is too far from the minimum. in practice, must be used with a globalization strategy which reduces the step length until function decrease is assured

29 Extension to N (multivariate) dimensions How big N can be? problem sizes can vary from a handful of parameters to many thousands We will consider examples for N=2, so that cost function surfaces can be visualized.
30 An Optimization Algorithm Start at x 0, k = Compute a search direction p k 2. Compute a step length α k, such that f(x k + α k p k ) < f(x k ) 3. Update x k = x k + α k p k k = k+1 4. Check for convergence (stopping criteria) e.g. df/dx = 0 Reduces optimization in N dimensions to a series of (1D) line minimizations

 is the")
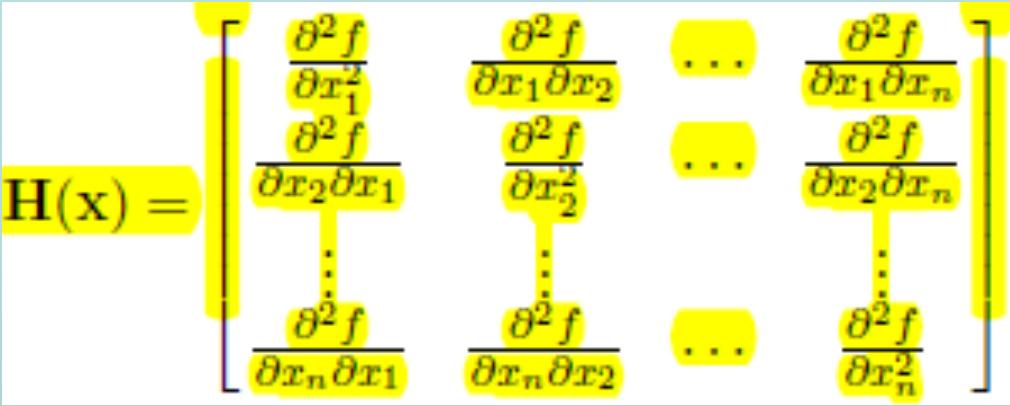
31 Taylor expansion A function may be approximated locally by its Taylor series expansion about a point x* where the gradient is the vector and the Hessian H(x*) is the symmetric matrix




32 Summary of Eqns. Studies so far




33
 = G ( x) = 2 x x")
 2 1] σ 3 2π σ 2 = g(")
")
34 δg G: Gaussian Function Take : G( x) = G ( x) = 2 x x exp( 3 2π σ 2 2σ [ 2 G ( x) ( x ) 2 1] σ 3 2π σ 2 = g( x*) = G( x*) = e 2πσ ) exp( 0 2 x 2σ 2 x 2σ ) δ 2 G

35 Quadratic functions The vector g and the Hessian H are constant. Second order approximation of any function by the Taylor expansion is a quadratic function. We will assume only quadratic functions for a while.
 about a")


36 Necessary conditions for a minimum Expand f(x) about a stationary point x* in direction p since at a stationary point At a stationary point the behavior is determined by H



37 H is a symmetric matrix, and so has orthogonal eigenvectors As α increases, f(x* + αu i ) increases, decreases or is unchanging according to whether λ i is positive, negative or zero


38 Examples of quadratic functions Case 1: both eigenvalues positive with positive definite minimum



39 Examples of quadratic functions Case 2: eigenvalues have different sign with indefinite saddle point


40 Examples of quadratic functions Case 3: one eigenvalues is zero with positive semidefinite parabolic cylinder

41 Optimization for quadratic functions Assume that H is positive definite There is a unique minimum at If N is large, it is not feasible to perform this inversion directly.


. For quadratic forms there is a closed form")
42 Steepest descent Basic principle is to minimize the N-dimensional function by a series of 1D line-minimizations: The steepest descent method chooses p k to be parallel to the gradient Step-size α k is chosen to minimize f(x k + α k p k ). For quadratic forms there is a closed form solution: Prove it!
.")
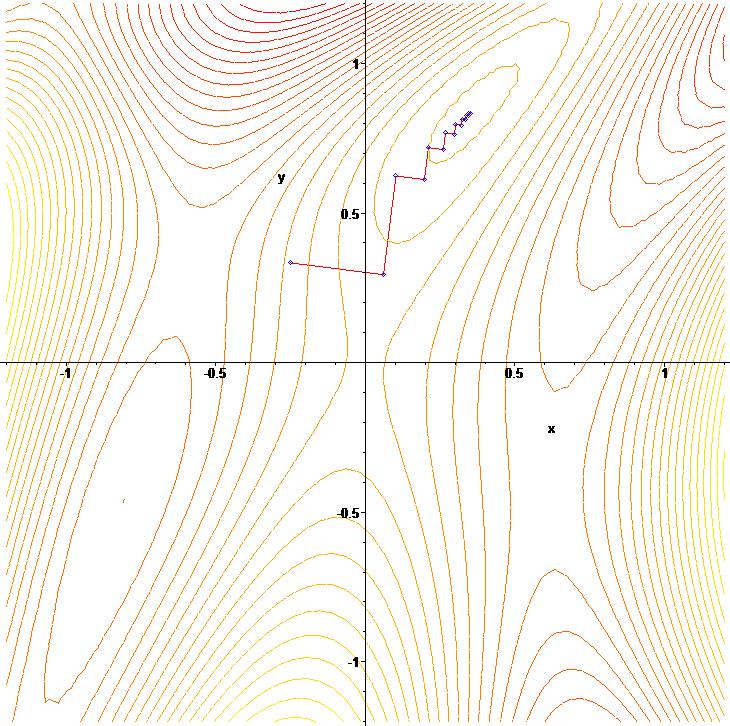
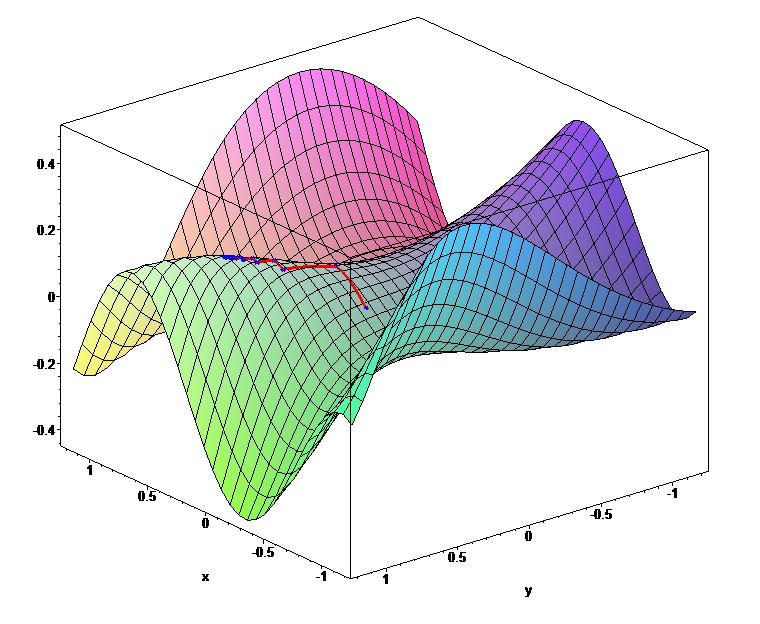
43 Steepest descent The gradient is everywhere perpendicular to the contour lines. After each line minimization the new gradient is always orthogonal to the previous step direction (true of any line minimization). Consequently, the iterates tend to zig-zag down the valley in a very inefficient manner
44 Steepest descent The 1D line minimization must be performed using one of the earlier methods (usually cubic polynomial interpolation) The zig-zag behaviour is clear in the zoomed view The algorithm crawls down the valley
45
46
47
48
 by its Taylor")


49 Newton method Expand f(x) by its Taylor series about the point x k where the gradient is the vector and the Hessian is the symmetric matrix
50 Newton method For a minimum we require that, and so with solution. This gives the iterative update If f(x) is quadratic, then the solution is found in one step. The method has quadratic convergence (as in the 1D case). The solution is guaranteed to be a downhill direction. Rather than jump straight to the minimum, it is better to perform a line minimization which ensures global convergence If H=I then this reduces to steepest descent.

51 Without second order knowledge (ie gradient descent), you can miss the narrow valley entirely with fixed sized steps in the direction of the gradient (i.e. fixed steps are too large). Even if you go into the valley, you would spend a great deal of time zig zagging back and forth the steep walls because the gradient at those walls would simply direct the descent to each side of the valley. Second order information (ie Hessian) allows you to take into account the curvature and take steps sized inverse to the 'steepness' (very steep -> small steps, very flat -> large steps).

52 Newton method - example The algorithm converges in only 18 iterations compared to the 98 for conjugate gradients. However, the method requires computing the Hessian matrix at each iteration this is not always feasible

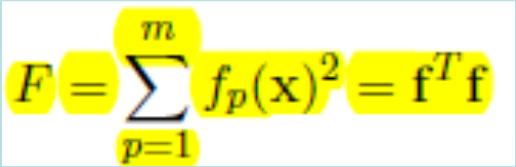
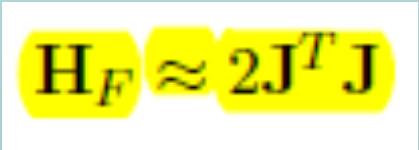


53 Gauss - Newton method
54 Method Alpha ( ) Calculation Intermediate Updates Convergence Condition Steepest- Descent Method (Method 1) Find, the value of that minimizes ( + ), using line search = + = = ( ) If <, then =, = Else = +1 Steepest- Descent Method (Method 2) Without Using Line Search = + = = ( ) Newton Method Find, the value of that minimizes ( + ), using line search = + = = ( ) -- --
55 Method Alpha ( ) Calculation Intermediate Updates Convergence Condition Steepest- Descent Method (Method 1) Steepest- Descent Method (Method 2) Find, the value of that minimizes ( + ), using line search Without Using Line Search = + = = ( ) If <, then =, = Else = +1 = + = = ( ) Newton Method Find, the value of that minimizes ( + ), using line search = + = = ( ) Gauss- Newton Method Find, the value of that minimizes F +, using line search = = = = + = =2 2 = ( ) = ( ) = ( ) = ( ) ( ) = ( ) If < then =, F = Else = +1

56 Conjugate gradient Each p k is chosen to be conjugate to all previous search directions with respect to the Hessian H: The resulting search directions are mutually linearly independent. Prove it! Remarkably, p k can be chosen using only knowledge of p k-1,, and

57

58 Conjugate gradient An N-dimensional quadratic form can be minimized in at most N conjugate descent steps. 3 different starting points. Minimum is reached in exactly 2 steps.


59 Optimization for General functions Apply methods developed using quadratic Taylor series expansion
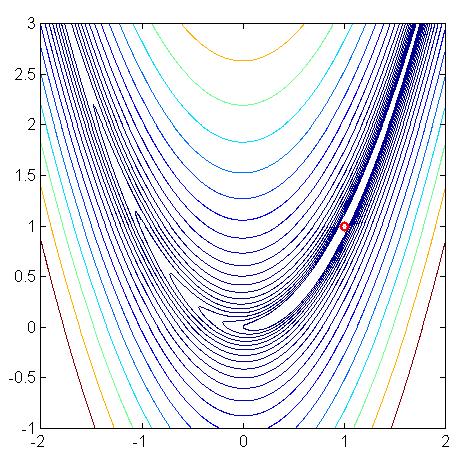
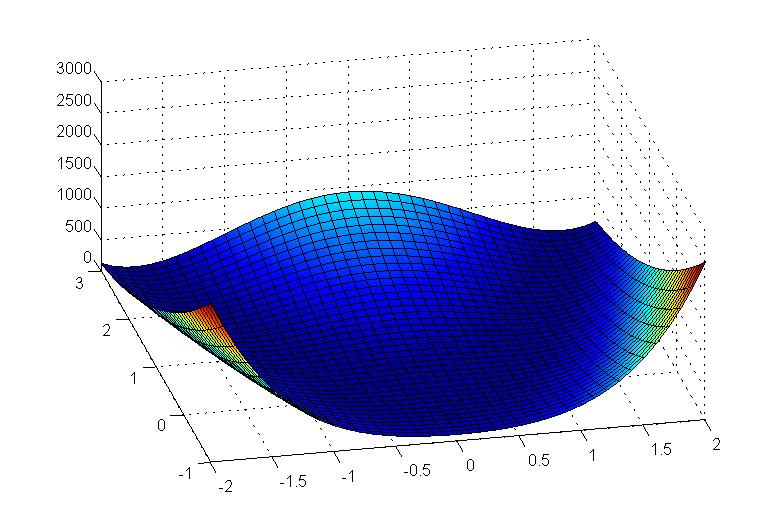
60 Rosenbrock s function Minimum at [1, 1]
61 Conjugate gradient Again, an explicit line minimization must be used at every step The algorithm converges in 98 iterations Far superior to steepest descent
62 Quasi-Newton methods If the problem size is large and the Hessian matrix is dense then it may be infeasible/inconvenient to compute it directly. Quasi-Newton methods avoid this problem by keeping a rolling estimate of H(x), updated at each iteration using new gradient information. Common schemes are due to Broyden, Goldfarb, Fletcher and Shanno (BFGS), and also Davidson, Fletcher and Powell (DFP). The idea is based on the fact that for quadratic functions holds and by accumulating g k s and x k s we can calculate H.

63 Quasi-Newton BFGS method Set H 0 = I. Update according to where The matrix inverse can also be computed in this way. Directions δ k s form a conjugate set. H k+1 is positive definite if H k is positive definite. The estimate H k is used to form a local quadratic approximation as before
64 BFGS example The method converges in 34 iterations, compared to 18 for the full-newton method
 If <, then =, = Else = +1 Fletcher- Reeves Line search = ; = + = ( ); = + -,,- Powell Line search = + ; = 0 0 0 0 0 = (")
65 Method ( ) Calculation Intermediate Updates Conv. Condition Conjugate Gradient Without Using Line Search = = ; = + = ; = + = ( ) If <, then =, = Else = +1 Fletcher- Reeves Line search = ; = + = ( ); = + -,,- Powell Line search = + ; = = ( ); -,,- Quasi- Newton Method Find, the value of that minimizes ( + ), using line search = + ; = ; = ; = / = + / = = + ( )( ) ( ) = If <, then =, = Else = +1
66 Method Alpha ( ) Calculation Intermediate Updates Convergence Condition Coordinate Descent Find, the value of that minimizes ( + ), using line search = + = = ( ) If <, then =, = Elseif k==n, then =, = 1 Else = +1 Conjugate Gradient Without Using Line Search = = = + = = + = ( ) If <, then =, = Else = +1 Quasi- Newton Method Find, the value of that minimizes ( + ), using line search = + = ; = = / = + / = = + ( )( ) ( ) = If <, then =, = Else = +1

67
 is a non-linear least squares")
68 Non-linear least squares It is very common in applications for a cost function f(x) to be the sum of a large number of squared residuals If each residual depends non-linearly on the parameters x then the minimization of f(x) is a non-linear least squares problem.




69 Non-linear least squares The M N Jacobian of the vector of residuals r is defined as Consider Hence



70 Non-linear least squares For the Hessian holds Gauss-Newton approximation Note that the second-order term in the Hessian is multiplied by the residuals r i. In most problems, the residuals will typically be small. Also, at the minimum, the residuals will typically be distributed with mean = 0. For these reasons, the second-order term is often ignored. Hence, explicit computation of the full Hessian can again be avoided.


71 Gauss-Newton example The minimization of the Rosenbrock function can be written as a least-squares problem with residual vector


72 Gauss-Newton example minimization with the Gauss-Newton approximation with line search takes only 11 iterations
73 Method Alpha ( ) Calculation Intermediate Updates Convergence Condition Steepest- Descent Method (Method 1) Steepest- Descent Method (Method 2) Find, the value of that minimizes ( + ), using line search Without Using Line Search = + = = ( ) If <, then =, = Else = +1 = + = = ( ) Newton Method Find, the value of that minimizes ( + ), using line search = + = = ( ) Gauss- Newton Method Find, the value of that minimizes F +, using line search = = = = + = =2 2 = ( ) = ( ) = ( ) = ( ) ( ) = ( ) If < then =, F = Else = +1



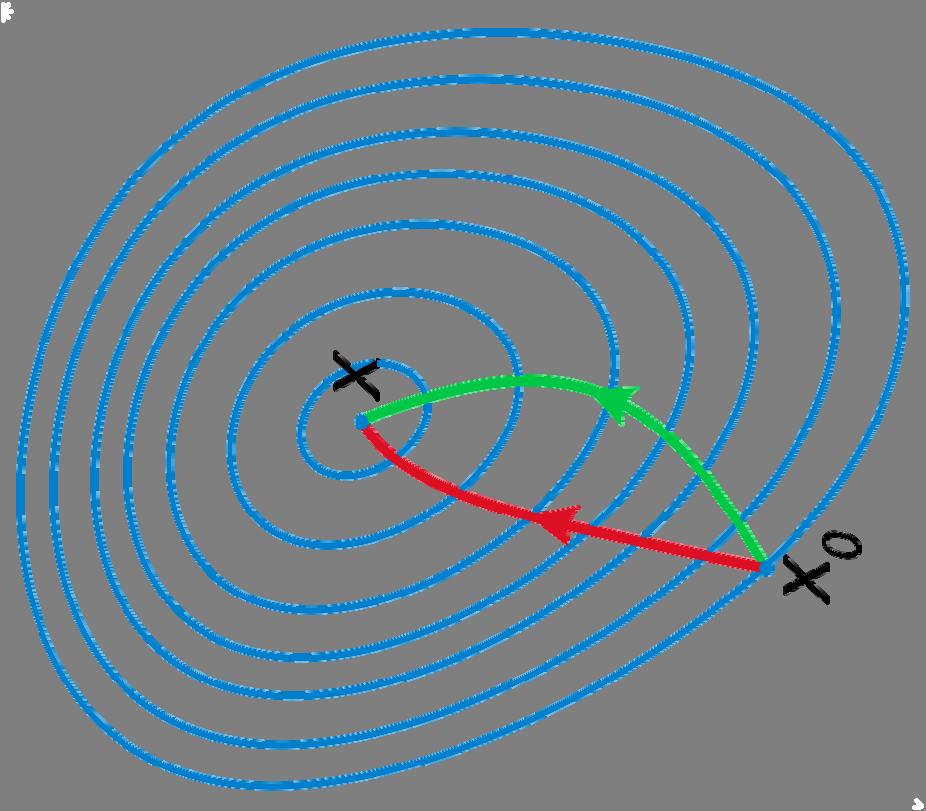
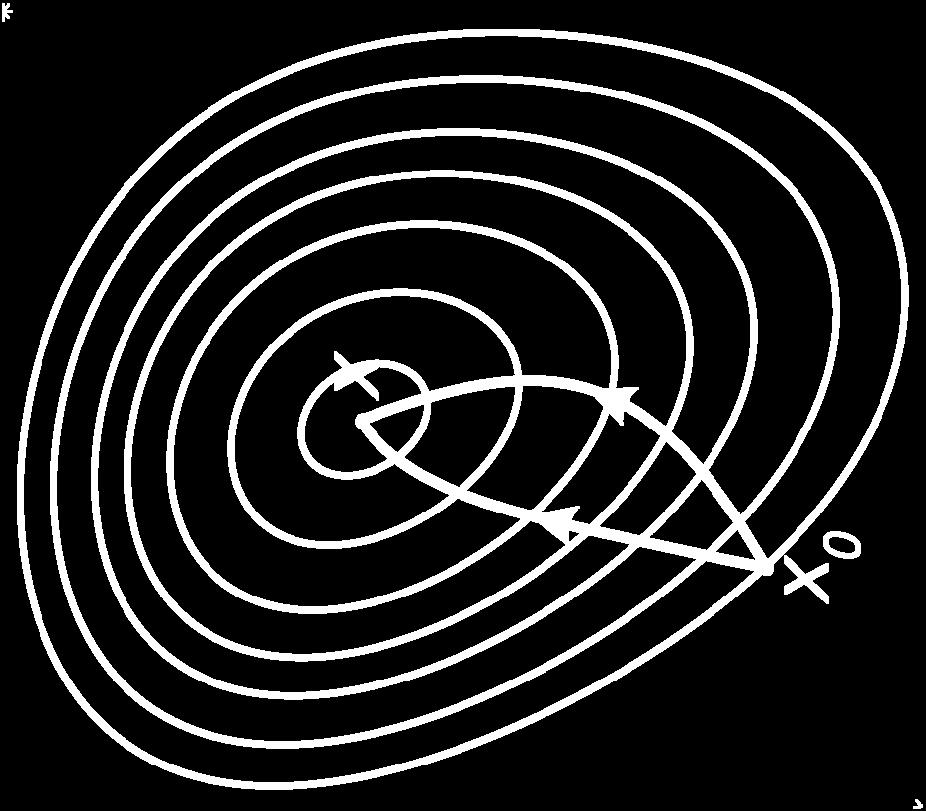
74 Steepest Descent vs Conjugate Gradient Newton vs Gradient Descent


75 The successive steps taken by the method of the gradient descent for optimizing the Rosenbrock functions
 Constant step length variant.")
76 Levenberg-Marquardt algorithm for optimizing the Rosenbrock function Newton's method for optimizing the Rosenbrock functions. (a) Constant step length variant. (b) Step length determined with an optimal line search strategy
77 Comparison CG Newton Quasi-Newton Gauss-Newton
78 Method ( ) Calculation Intermediate Updates Conv. Condition Conjugate Gradient Without Using Line Search = = ; = + = ; = + = ( ) If <, then =, = Else = +1 Newton Method Find, the value of that minimizes ( + ), using line search = + = = ( ) Gauss- Newton Method Use line search, for = = = = + ; = =2 ; 2 = ( ) = ( ) = ( ) = ( ); ( ) = ( ) If < then =, F = Else = +1 Quasi- Newton Method Find, the value of that minimizes ( + ), using line search = + ; = ; = ; = = + ; = = + ( )( ) ( ) = If <, then =, = Else = +1

79 Steepest Descent Fletcher Reeve s Conjugate Gradient Powels s Conjugate Gradient Quasi-Newton Newton s
80 Steepest Descent Fletcher Reeve s Conjugate Gradient Powels s Conjugate Gradient Quasi-Newton Newton s
81 Steepest Descent Fletcher Reeve s Conjugate Gradient Powels s Conjugate Gradient Newton s Quasi-Newton
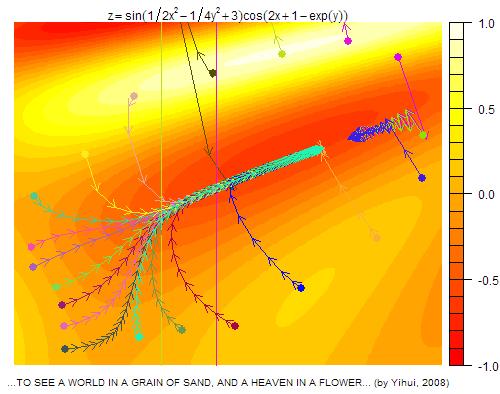
82

83
84 Deep learning via Hessian-free optimization James Martens University of Toronto, Ontario, M5S 1A1, Canada proceedings of the 27 th International Conference on Machine Learning,, Haifa, Israel, Copyright 2010
85 On Optimization Methods for Deep Learning Quoc V. Le Jiquan Ngiam Adam Coates Abhik Lahiri Bobby Prochnow Andrew Y. Ng; ICML 11 Successful unconstrained optimization methods include Newton-Raphson s method, BFGS methods, Conjugate Gradient methods and Stochastic Gradient Descent methods. These methods are usually associated with a line search method to ensure that the algorithms consistently improve the objective function. When it comes to large scale machine learning, the favorite optimization method is usually SGDs. Recent work on SGDs focuses on adaptive strategies for the learning rate for improving SGD convergence by approximating second-order information. In practice, plain SGDs with constant learning rates or learning rates of the form (α/β+t) are still popular thanks to their ease of implementation. These simple methods are even more common in deep learning because the optimization problems are nonconvex and the convergence properties of complex methods no longer hold.
86 Recent proposals for training deep networks argue for the use of layer-wise pre-training. Optimization techniques for training these models include Contrastive Divergence, Conjugate Gradient, stochastic diagonal Levenberg-Marquardt and Hessian-free optimization. Convolutional neural networks have traditionally employed SGDs with the stochastic diagonal Levenberg-Marquardt, which uses a diagonal approximation to the Hessian. In this paper, it is our goal to empirically study the pros and cons of off-the-shelf optimization algorithms in the context of unsupervised feature learning and deep learning. In that direction, we focus on comparing L-BFGS, CG and SGDs.
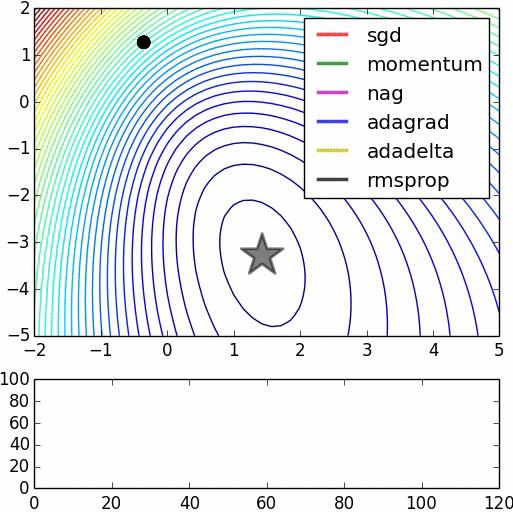
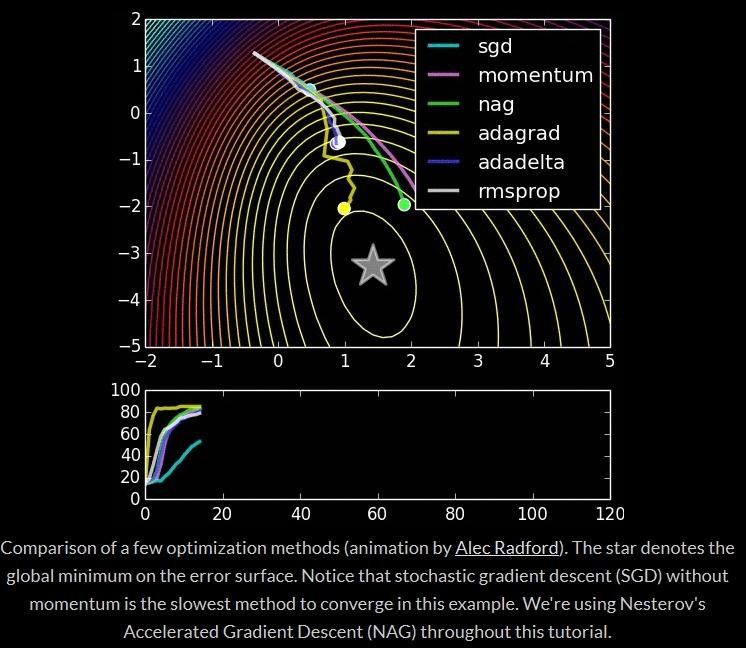
87


88 "Beale's function: Due to the large initial gradient, velocity based techniques shoot off and bounce around - adagrad almost goes unstable for the same reason. Algos that scale gradients/step sizes like adadelta and RMSProp proceed more like accelerated SGD and handle large gradients with more stability." Global Minimum:


89 "Long valley: Algos without scaling based on gradient information really struggle to break symmetry here - SGD gets no where and Nesterov Accelerated Gradient / Momentum exhibits oscillations until they build up velocity in the optimization direction. Algos that scale step size based on the gradient quickly break symmetry and begin descent." "Saddle point: Behavior around a saddle point. NAG/Momentum again like to explore around, almost taking a different path. Adadelta/Adagrad/RMSProp proceed like accelerated SGD.
90
91





92 Constrained Optimization Subject to: Equality constraints: Nonequality constraints: Constraints define a feasible region, which is nonempty. The idea is to convert it to an unconstrained optimization.
 at a local minimizer is equal")
 with Lagrange multipliers as the coefficients.")
93 Equality constraints Minimize f(x) subject to: for The gradient of f(x) at a local minimizer is equal to the linear combination of the gradients of a i (x) with Lagrange multipliers as the coefficients.
 subject to: for")

, which")

94 Inequality constraints Minimize f(x) subject to: for The gradient of f(x) at a local minimizer is equal to the linear combination of the gradients of c j (x), which are active ( c j (x) = 0 ) and Lagrange multipliers must be positive,
.")
95 Lagrangien We can introduce the function (Lagrangien) The necessary condition for the local minimizer is and it must be a feasible point (i.e. constraints are satisfied). These are Karush-Kuhn-Tucker conditions

96 General Nonlinear Optimization Minimize f(x) subject to: where the objective function and constraints are nonlinear. 1. For a given approximate Lagrangien by Taylor series QP problem 2. Solve QP descent direction 3. Perform line search in the direction 4. Update Lagrange multipliers 5. Repeat from Step 1.

97 General Nonlinear Optimization Lagrangien At the kth iterate: and we want to compute a set of increments: First order approximation of and constraints: These approximate KKT conditions corresponds to a QP program

98 Quadratic Programming (QP) Like in the unconstrained case, it is important to study quadratic functions. Why? Because general nonlinear problems are solved as a sequence of minimizations of their quadratic approximations. QP with constraints Minimize subject to linear constraints. H is symmetric and positive semidefinite.



99 QP with Equality Constraints Minimize Subject to: Ass.: A is p N and has full row rank (p<n) Convert to unconstrained problem by variable elimination: Z is the null space of A A + is the pseudo-inverse. Minimize This quadratic unconstrained problem can be solved, e.g., by Newton method.

100 QP with inequality constraints Minimize Subject to: First we check if the unconstrained minimizer is feasible. If yes we are done. If not we know that the minimizer must be on the boundary and we proceed with an active-set method. x k is the current feasible point is the index set of active constraints at x k Next iterate is given by






101 Active-set method How to find d k? To remain active thus The objective function at x k +d becomes where The major step is a QP sub-problem subject to: Two situations may occur: or

102 Active-set method We check if KKT conditions are satisfied and If YES we are done. If NO we remove the constraint from the active set with the most negative and solve the QP sub-problem again but this time with less active constraints. We can move to but some inactive constraints may be violated on the way. In this case, we move by till the first inactive constraint becomes active, update, and solve the QP sub-problem again but this time with more active constraints.


103 SQP example Minimize subject to:
Optimization Methods
 Optimization Methods Decision making Examples: determining which ingredients and in what quantities to add to a mixture being made so that it will meet specifications on its composition allocating available
Optimization Methods Decision making Examples: determining which ingredients and in what quantities to add to a mixture being made so that it will meet specifications on its composition allocating available
NonlinearOptimization
 1/35 NonlinearOptimization Pavel Kordík Department of Computer Systems Faculty of Information Technology Czech Technical University in Prague Jiří Kašpar, Pavel Tvrdík, 2011 Unconstrained nonlinear optimization,
1/35 NonlinearOptimization Pavel Kordík Department of Computer Systems Faculty of Information Technology Czech Technical University in Prague Jiří Kašpar, Pavel Tvrdík, 2011 Unconstrained nonlinear optimization,
Optimization: Nonlinear Optimization without Constraints. Nonlinear Optimization without Constraints 1 / 23
 Optimization: Nonlinear Optimization without Constraints Nonlinear Optimization without Constraints 1 / 23 Nonlinear optimization without constraints Unconstrained minimization min x f(x) where f(x) is
Optimization: Nonlinear Optimization without Constraints Nonlinear Optimization without Constraints 1 / 23 Nonlinear optimization without constraints Unconstrained minimization min x f(x) where f(x) is
Nonlinear Optimization: What s important?
 Nonlinear Optimization: What s important? Julian Hall 10th May 2012 Convexity: convex problems A local minimizer is a global minimizer A solution of f (x) = 0 (stationary point) is a minimizer A global
Nonlinear Optimization: What s important? Julian Hall 10th May 2012 Convexity: convex problems A local minimizer is a global minimizer A solution of f (x) = 0 (stationary point) is a minimizer A global
Scientific Computing: An Introductory Survey
 Scientific Computing: An Introductory Survey Chapter 6 Optimization Prof. Michael T. Heath Department of Computer Science University of Illinois at Urbana-Champaign Copyright c 2002. Reproduction permitted
Scientific Computing: An Introductory Survey Chapter 6 Optimization Prof. Michael T. Heath Department of Computer Science University of Illinois at Urbana-Champaign Copyright c 2002. Reproduction permitted
Scientific Computing: An Introductory Survey
 Scientific Computing: An Introductory Survey Chapter 6 Optimization Prof. Michael T. Heath Department of Computer Science University of Illinois at Urbana-Champaign Copyright c 2002. Reproduction permitted
Scientific Computing: An Introductory Survey Chapter 6 Optimization Prof. Michael T. Heath Department of Computer Science University of Illinois at Urbana-Champaign Copyright c 2002. Reproduction permitted
Numerical Optimization Professor Horst Cerjak, Horst Bischof, Thomas Pock Mat Vis-Gra SS09
 Numerical Optimization 1 Working Horse in Computer Vision Variational Methods Shape Analysis Machine Learning Markov Random Fields Geometry Common denominator: optimization problems 2 Overview of Methods
Numerical Optimization 1 Working Horse in Computer Vision Variational Methods Shape Analysis Machine Learning Markov Random Fields Geometry Common denominator: optimization problems 2 Overview of Methods
Machine Learning CS 4900/5900. Lecture 03. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Machine Learning CS 4900/5900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Machine Learning is Optimization Parametric ML involves minimizing an objective function
Machine Learning CS 4900/5900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Machine Learning is Optimization Parametric ML involves minimizing an objective function
Numerical Optimization Techniques
 Numerical Optimization Techniques Léon Bottou NEC Labs America COS 424 3/2/2010 Today s Agenda Goals Representation Capacity Control Operational Considerations Computational Considerations Classification,
Numerical Optimization Techniques Léon Bottou NEC Labs America COS 424 3/2/2010 Today s Agenda Goals Representation Capacity Control Operational Considerations Computational Considerations Classification,
Statistics 580 Optimization Methods
 Statistics 580 Optimization Methods Introduction Let fx be a given real-valued function on R p. The general optimization problem is to find an x ɛ R p at which fx attain a maximum or a minimum. It is of
Statistics 580 Optimization Methods Introduction Let fx be a given real-valued function on R p. The general optimization problem is to find an x ɛ R p at which fx attain a maximum or a minimum. It is of
Scientific Computing: Optimization
 Scientific Computing: Optimization Aleksandar Donev Courant Institute, NYU 1 donev@courant.nyu.edu 1 Course MATH-GA.2043 or CSCI-GA.2112, Spring 2012 March 8th, 2011 A. Donev (Courant Institute) Lecture
Scientific Computing: Optimization Aleksandar Donev Courant Institute, NYU 1 donev@courant.nyu.edu 1 Course MATH-GA.2043 or CSCI-GA.2112, Spring 2012 March 8th, 2011 A. Donev (Courant Institute) Lecture
Lecture Notes: Geometric Considerations in Unconstrained Optimization
 Lecture Notes: Geometric Considerations in Unconstrained Optimization James T. Allison February 15, 2006 The primary objectives of this lecture on unconstrained optimization are to: Establish connections
Lecture Notes: Geometric Considerations in Unconstrained Optimization James T. Allison February 15, 2006 The primary objectives of this lecture on unconstrained optimization are to: Establish connections
Nonlinear Programming
 Nonlinear Programming Kees Roos e-mail: C.Roos@ewi.tudelft.nl URL: http://www.isa.ewi.tudelft.nl/ roos LNMB Course De Uithof, Utrecht February 6 - May 8, A.D. 2006 Optimization Group 1 Outline for week
Nonlinear Programming Kees Roos e-mail: C.Roos@ewi.tudelft.nl URL: http://www.isa.ewi.tudelft.nl/ roos LNMB Course De Uithof, Utrecht February 6 - May 8, A.D. 2006 Optimization Group 1 Outline for week
Optimization II: Unconstrained Multivariable
 Optimization II: Unconstrained Multivariable CS 205A: Mathematical Methods for Robotics, Vision, and Graphics Doug James (and Justin Solomon) CS 205A: Mathematical Methods Optimization II: Unconstrained
Optimization II: Unconstrained Multivariable CS 205A: Mathematical Methods for Robotics, Vision, and Graphics Doug James (and Justin Solomon) CS 205A: Mathematical Methods Optimization II: Unconstrained
Quasi-Newton Methods
 Newton s Method Pros and Cons Quasi-Newton Methods MA 348 Kurt Bryan Newton s method has some very nice properties: It s extremely fast, at least once it gets near the minimum, and with the simple modifications
Newton s Method Pros and Cons Quasi-Newton Methods MA 348 Kurt Bryan Newton s method has some very nice properties: It s extremely fast, at least once it gets near the minimum, and with the simple modifications
EAD 115. Numerical Solution of Engineering and Scientific Problems. David M. Rocke Department of Applied Science
 EAD 115 Numerical Solution of Engineering and Scientific Problems David M. Rocke Department of Applied Science Multidimensional Unconstrained Optimization Suppose we have a function f() of more than one
EAD 115 Numerical Solution of Engineering and Scientific Problems David M. Rocke Department of Applied Science Multidimensional Unconstrained Optimization Suppose we have a function f() of more than one
Gradient Descent. Dr. Xiaowei Huang
 Gradient Descent Dr. Xiaowei Huang https://cgi.csc.liv.ac.uk/~xiaowei/ Up to now, Three machine learning algorithms: decision tree learning k-nn linear regression only optimization objectives are discussed,
Gradient Descent Dr. Xiaowei Huang https://cgi.csc.liv.ac.uk/~xiaowei/ Up to now, Three machine learning algorithms: decision tree learning k-nn linear regression only optimization objectives are discussed,
1 Numerical optimization
 Contents 1 Numerical optimization 5 1.1 Optimization of single-variable functions............ 5 1.1.1 Golden Section Search................... 6 1.1. Fibonacci Search...................... 8 1. Algorithms
Contents 1 Numerical optimization 5 1.1 Optimization of single-variable functions............ 5 1.1.1 Golden Section Search................... 6 1.1. Fibonacci Search...................... 8 1. Algorithms
Outline. Scientific Computing: An Introductory Survey. Optimization. Optimization Problems. Examples: Optimization Problems
 Outline Scientific Computing: An Introductory Survey Chapter 6 Optimization 1 Prof. Michael. Heath Department of Computer Science University of Illinois at Urbana-Champaign Copyright c 2002. Reproduction
Outline Scientific Computing: An Introductory Survey Chapter 6 Optimization 1 Prof. Michael. Heath Department of Computer Science University of Illinois at Urbana-Champaign Copyright c 2002. Reproduction
Constrained optimization. Unconstrained optimization. One-dimensional. Multi-dimensional. Newton with equality constraints. Active-set method.
 Optimization Unconstrained optimization One-dimensional Multi-dimensional Newton s method Basic Newton Gauss- Newton Quasi- Newton Descent methods Gradient descent Conjugate gradient Constrained optimization
Optimization Unconstrained optimization One-dimensional Multi-dimensional Newton s method Basic Newton Gauss- Newton Quasi- Newton Descent methods Gradient descent Conjugate gradient Constrained optimization
Lecture V. Numerical Optimization
 Lecture V Numerical Optimization Gianluca Violante New York University Quantitative Macroeconomics G. Violante, Numerical Optimization p. 1 /19 Isomorphism I We describe minimization problems: to maximize
Lecture V Numerical Optimization Gianluca Violante New York University Quantitative Macroeconomics G. Violante, Numerical Optimization p. 1 /19 Isomorphism I We describe minimization problems: to maximize
Optimization for neural networks
 0 - : Optimization for neural networks Prof. J.C. Kao, UCLA Optimization for neural networks We previously introduced the principle of gradient descent. Now we will discuss specific modifications we make
0 - : Optimization for neural networks Prof. J.C. Kao, UCLA Optimization for neural networks We previously introduced the principle of gradient descent. Now we will discuss specific modifications we make
Contents. Preface. 1 Introduction Optimization view on mathematical models NLP models, black-box versus explicit expression 3
 Contents Preface ix 1 Introduction 1 1.1 Optimization view on mathematical models 1 1.2 NLP models, black-box versus explicit expression 3 2 Mathematical modeling, cases 7 2.1 Introduction 7 2.2 Enclosing
Contents Preface ix 1 Introduction 1 1.1 Optimization view on mathematical models 1 1.2 NLP models, black-box versus explicit expression 3 2 Mathematical modeling, cases 7 2.1 Introduction 7 2.2 Enclosing
Programming, numerics and optimization
 Programming, numerics and optimization Lecture C-3: Unconstrained optimization II Łukasz Jankowski ljank@ippt.pan.pl Institute of Fundamental Technological Research Room 4.32, Phone +22.8261281 ext. 428
Programming, numerics and optimization Lecture C-3: Unconstrained optimization II Łukasz Jankowski ljank@ippt.pan.pl Institute of Fundamental Technological Research Room 4.32, Phone +22.8261281 ext. 428
AM 205: lecture 19. Last time: Conditions for optimality Today: Newton s method for optimization, survey of optimization methods
 AM 205: lecture 19 Last time: Conditions for optimality Today: Newton s method for optimization, survey of optimization methods Optimality Conditions: Equality Constrained Case As another example of equality
AM 205: lecture 19 Last time: Conditions for optimality Today: Newton s method for optimization, survey of optimization methods Optimality Conditions: Equality Constrained Case As another example of equality
Optimization. Totally not complete this is...don't use it yet...
 Optimization Totally not complete this is...don't use it yet... Bisection? Doing a root method is akin to doing a optimization method, but bi-section would not be an effective method - can detect sign
Optimization Totally not complete this is...don't use it yet... Bisection? Doing a root method is akin to doing a optimization method, but bi-section would not be an effective method - can detect sign
Numerical Optimization of Partial Differential Equations
 Numerical Optimization of Partial Differential Equations Part I: basic optimization concepts in R n Bartosz Protas Department of Mathematics & Statistics McMaster University, Hamilton, Ontario, Canada
Numerical Optimization of Partial Differential Equations Part I: basic optimization concepts in R n Bartosz Protas Department of Mathematics & Statistics McMaster University, Hamilton, Ontario, Canada
1 Numerical optimization
 Contents Numerical optimization 5. Optimization of single-variable functions.............................. 5.. Golden Section Search..................................... 6.. Fibonacci Search........................................
Contents Numerical optimization 5. Optimization of single-variable functions.............................. 5.. Golden Section Search..................................... 6.. Fibonacci Search........................................
5 Handling Constraints
 5 Handling Constraints Engineering design optimization problems are very rarely unconstrained. Moreover, the constraints that appear in these problems are typically nonlinear. This motivates our interest
5 Handling Constraints Engineering design optimization problems are very rarely unconstrained. Moreover, the constraints that appear in these problems are typically nonlinear. This motivates our interest
Numerisches Rechnen. (für Informatiker) M. Grepl P. Esser & G. Welper & L. Zhang. Institut für Geometrie und Praktische Mathematik RWTH Aachen
 M. Grepl P. Esser & G. Welper & L. Zhang. Institut für Geometrie und Praktische Mathematik RWTH Aachen") Numerisches Rechnen (für Informatiker) M. Grepl P. Esser & G. Welper & L. Zhang Institut für Geometrie und Praktische Mathematik RWTH Aachen Wintersemester 2011/12 IGPM, RWTH Aachen Numerisches Rechnen
Numerisches Rechnen (für Informatiker) M. Grepl P. Esser & G. Welper & L. Zhang Institut für Geometrie und Praktische Mathematik RWTH Aachen Wintersemester 2011/12 IGPM, RWTH Aachen Numerisches Rechnen
Optimization Methods for Machine Learning
 Optimization Methods for Machine Learning Sathiya Keerthi Microsoft Talks given at UC Santa Cruz February 21-23, 2017 The slides for the talks will be made available at: http://www.keerthis.com/ Introduction
Optimization Methods for Machine Learning Sathiya Keerthi Microsoft Talks given at UC Santa Cruz February 21-23, 2017 The slides for the talks will be made available at: http://www.keerthis.com/ Introduction
Optimization and Root Finding. Kurt Hornik
 Optimization and Root Finding Kurt Hornik Basics Root finding and unconstrained smooth optimization are closely related: Solving ƒ () = 0 can be accomplished via minimizing ƒ () 2 Slide 2 Basics Root finding
Optimization and Root Finding Kurt Hornik Basics Root finding and unconstrained smooth optimization are closely related: Solving ƒ () = 0 can be accomplished via minimizing ƒ () 2 Slide 2 Basics Root finding
Optimization Methods for Circuit Design
 Technische Universität München Department of Electrical Engineering and Information Technology Institute for Electronic Design Automation Optimization Methods for Circuit Design Compendium H. Graeb Version
Technische Universität München Department of Electrical Engineering and Information Technology Institute for Electronic Design Automation Optimization Methods for Circuit Design Compendium H. Graeb Version
Introduction to unconstrained optimization - direct search methods
 Introduction to unconstrained optimization - direct search methods Jussi Hakanen Post-doctoral researcher jussi.hakanen@jyu.fi Structure of optimization methods Typically Constraint handling converts the
Introduction to unconstrained optimization - direct search methods Jussi Hakanen Post-doctoral researcher jussi.hakanen@jyu.fi Structure of optimization methods Typically Constraint handling converts the
MATHEMATICS FOR COMPUTER VISION WEEK 8 OPTIMISATION PART 2. Dr Fabio Cuzzolin MSc in Computer Vision Oxford Brookes University Year
 MATHEMATICS FOR COMPUTER VISION WEEK 8 OPTIMISATION PART 2 1 Dr Fabio Cuzzolin MSc in Computer Vision Oxford Brookes University Year 2013-14 OUTLINE OF WEEK 8 topics: quadratic optimisation, least squares,
MATHEMATICS FOR COMPUTER VISION WEEK 8 OPTIMISATION PART 2 1 Dr Fabio Cuzzolin MSc in Computer Vision Oxford Brookes University Year 2013-14 OUTLINE OF WEEK 8 topics: quadratic optimisation, least squares,
Optimization II: Unconstrained Multivariable
 Optimization II: Unconstrained Multivariable CS 205A: Mathematical Methods for Robotics, Vision, and Graphics Justin Solomon CS 205A: Mathematical Methods Optimization II: Unconstrained Multivariable 1
Optimization II: Unconstrained Multivariable CS 205A: Mathematical Methods for Robotics, Vision, and Graphics Justin Solomon CS 205A: Mathematical Methods Optimization II: Unconstrained Multivariable 1
Multivariate Newton Minimanization
 Multivariate Newton Minimanization Optymalizacja syntezy biosurfaktantu Rhamnolipid Rhamnolipids are naturally occuring glycolipid produced commercially by the Pseudomonas aeruginosa species of bacteria.
Multivariate Newton Minimanization Optymalizacja syntezy biosurfaktantu Rhamnolipid Rhamnolipids are naturally occuring glycolipid produced commercially by the Pseudomonas aeruginosa species of bacteria.
AM 205: lecture 19. Last time: Conditions for optimality, Newton s method for optimization Today: survey of optimization methods
 AM 205: lecture 19 Last time: Conditions for optimality, Newton s method for optimization Today: survey of optimization methods Quasi-Newton Methods General form of quasi-newton methods: x k+1 = x k α
AM 205: lecture 19 Last time: Conditions for optimality, Newton s method for optimization Today: survey of optimization methods Quasi-Newton Methods General form of quasi-newton methods: x k+1 = x k α
Part 4: Active-set methods for linearly constrained optimization. Nick Gould (RAL)
") Part 4: Active-set methods for linearly constrained optimization Nick Gould RAL fx subject to Ax b Part C course on continuoue optimization LINEARLY CONSTRAINED MINIMIZATION fx subject to Ax { } b where
Part 4: Active-set methods for linearly constrained optimization Nick Gould RAL fx subject to Ax b Part C course on continuoue optimization LINEARLY CONSTRAINED MINIMIZATION fx subject to Ax { } b where
Scientific Computing: An Introductory Survey
 Scientific Computing: An Introductory Survey Chapter 6 Optimization Prof. Michael T. Heath Department of Computer Science University of Illinois at Urbana-Champaign Copyright c 2002. Reproduction permitted
Scientific Computing: An Introductory Survey Chapter 6 Optimization Prof. Michael T. Heath Department of Computer Science University of Illinois at Urbana-Champaign Copyright c 2002. Reproduction permitted
Optimization 2. CS5240 Theoretical Foundations in Multimedia. Leow Wee Kheng
 Optimization 2 CS5240 Theoretical Foundations in Multimedia Leow Wee Kheng Department of Computer Science School of Computing National University of Singapore Leow Wee Kheng (NUS) Optimization 2 1 / 38
Optimization 2 CS5240 Theoretical Foundations in Multimedia Leow Wee Kheng Department of Computer Science School of Computing National University of Singapore Leow Wee Kheng (NUS) Optimization 2 1 / 38
Numerical Optimization. Review: Unconstrained Optimization
 Numerical Optimization Finding the best feasible solution Edward P. Gatzke Department of Chemical Engineering University of South Carolina Ed Gatzke (USC CHE ) Numerical Optimization ECHE 589, Spring 2011
Numerical Optimization Finding the best feasible solution Edward P. Gatzke Department of Chemical Engineering University of South Carolina Ed Gatzke (USC CHE ) Numerical Optimization ECHE 589, Spring 2011
Numerical Optimization: Basic Concepts and Algorithms
 May 27th 2015 Numerical Optimization: Basic Concepts and Algorithms R. Duvigneau R. Duvigneau - Numerical Optimization: Basic Concepts and Algorithms 1 Outline Some basic concepts in optimization Some
May 27th 2015 Numerical Optimization: Basic Concepts and Algorithms R. Duvigneau R. Duvigneau - Numerical Optimization: Basic Concepts and Algorithms 1 Outline Some basic concepts in optimization Some
Review of Classical Optimization
 Part II Review of Classical Optimization Multidisciplinary Design Optimization of Aircrafts 51 2 Deterministic Methods 2.1 One-Dimensional Unconstrained Minimization 2.1.1 Motivation Most practical optimization
Part II Review of Classical Optimization Multidisciplinary Design Optimization of Aircrafts 51 2 Deterministic Methods 2.1 One-Dimensional Unconstrained Minimization 2.1.1 Motivation Most practical optimization
Unconstrained Multivariate Optimization
 Unconstrained Multivariate Optimization Multivariate optimization means optimization of a scalar function of a several variables: and has the general form: y = () min ( ) where () is a nonlinear scalar-valued
Unconstrained Multivariate Optimization Multivariate optimization means optimization of a scalar function of a several variables: and has the general form: y = () min ( ) where () is a nonlinear scalar-valued
Conjugate Directions for Stochastic Gradient Descent
 Conjugate Directions for Stochastic Gradient Descent Nicol N Schraudolph Thore Graepel Institute of Computational Science ETH Zürich, Switzerland {schraudo,graepel}@infethzch Abstract The method of conjugate
Conjugate Directions for Stochastic Gradient Descent Nicol N Schraudolph Thore Graepel Institute of Computational Science ETH Zürich, Switzerland {schraudo,graepel}@infethzch Abstract The method of conjugate
Exploring the energy landscape
 Exploring the energy landscape ChE210D Today's lecture: what are general features of the potential energy surface and how can we locate and characterize minima on it Derivatives of the potential energy
Exploring the energy landscape ChE210D Today's lecture: what are general features of the potential energy surface and how can we locate and characterize minima on it Derivatives of the potential energy
ISM206 Lecture Optimization of Nonlinear Objective with Linear Constraints
 ISM206 Lecture Optimization of Nonlinear Objective with Linear Constraints Instructor: Prof. Kevin Ross Scribe: Nitish John October 18, 2011 1 The Basic Goal The main idea is to transform a given constrained
ISM206 Lecture Optimization of Nonlinear Objective with Linear Constraints Instructor: Prof. Kevin Ross Scribe: Nitish John October 18, 2011 1 The Basic Goal The main idea is to transform a given constrained
Performance Surfaces and Optimum Points
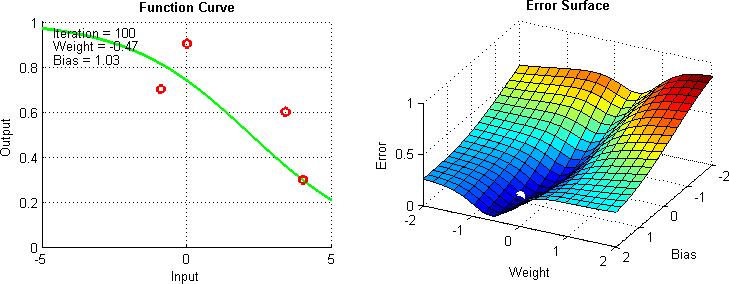
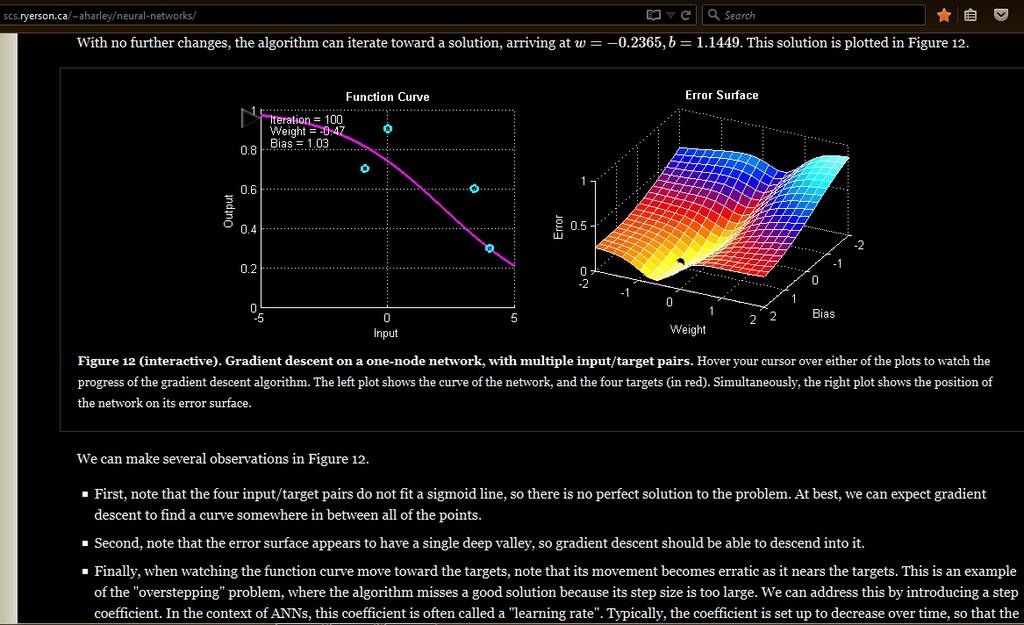
 CSC 302 1.5 Neural Networks Performance Surfaces and Optimum Points 1 Entrance Performance learning is another important class of learning law. Network parameters are adjusted to optimize the performance
CSC 302 1.5 Neural Networks Performance Surfaces and Optimum Points 1 Entrance Performance learning is another important class of learning law. Network parameters are adjusted to optimize the performance
Chapter 4. Unconstrained optimization
 Chapter 4. Unconstrained optimization Version: 28-10-2012 Material: (for details see) Chapter 11 in [FKS] (pp.251-276) A reference e.g. L.11.2 refers to the corresponding Lemma in the book [FKS] PDF-file
Chapter 4. Unconstrained optimization Version: 28-10-2012 Material: (for details see) Chapter 11 in [FKS] (pp.251-276) A reference e.g. L.11.2 refers to the corresponding Lemma in the book [FKS] PDF-file
Higher-Order Methods
 Higher-Order Methods Stephen J. Wright 1 2 Computer Sciences Department, University of Wisconsin-Madison. PCMI, July 2016 Stephen Wright (UW-Madison) Higher-Order Methods PCMI, July 2016 1 / 25 Smooth
Higher-Order Methods Stephen J. Wright 1 2 Computer Sciences Department, University of Wisconsin-Madison. PCMI, July 2016 Stephen Wright (UW-Madison) Higher-Order Methods PCMI, July 2016 1 / 25 Smooth
Newton s Method. Ryan Tibshirani Convex Optimization /36-725
 Newton s Method Ryan Tibshirani Convex Optimization 10-725/36-725 1 Last time: dual correspondences Given a function f : R n R, we define its conjugate f : R n R, Properties and examples: f (y) = max x
Newton s Method Ryan Tibshirani Convex Optimization 10-725/36-725 1 Last time: dual correspondences Given a function f : R n R, we define its conjugate f : R n R, Properties and examples: f (y) = max x
Determination of Feasible Directions by Successive Quadratic Programming and Zoutendijk Algorithms: A Comparative Study
 International Journal of Mathematics And Its Applications Vol.2 No.4 (2014), pp.47-56. ISSN: 2347-1557(online) Determination of Feasible Directions by Successive Quadratic Programming and Zoutendijk Algorithms:
International Journal of Mathematics And Its Applications Vol.2 No.4 (2014), pp.47-56. ISSN: 2347-1557(online) Determination of Feasible Directions by Successive Quadratic Programming and Zoutendijk Algorithms:
1 Introduction
 2018-06-12 1 Introduction The title of this course is Numerical Methods for Data Science. What does that mean? Before we dive into the course technical material, let s put things into context. I will not
2018-06-12 1 Introduction The title of this course is Numerical Methods for Data Science. What does that mean? Before we dive into the course technical material, let s put things into context. I will not
Maximum Likelihood Estimation
 Maximum Likelihood Estimation Prof. C. F. Jeff Wu ISyE 8813 Section 1 Motivation What is parameter estimation? A modeler proposes a model M(θ) for explaining some observed phenomenon θ are the parameters
Maximum Likelihood Estimation Prof. C. F. Jeff Wu ISyE 8813 Section 1 Motivation What is parameter estimation? A modeler proposes a model M(θ) for explaining some observed phenomenon θ are the parameters
Lecture 7 Unconstrained nonlinear programming
 Lecture 7 Unconstrained nonlinear programming Weinan E 1,2 and Tiejun Li 2 1 Department of Mathematics, Princeton University, weinan@princeton.edu 2 School of Mathematical Sciences, Peking University,
Lecture 7 Unconstrained nonlinear programming Weinan E 1,2 and Tiejun Li 2 1 Department of Mathematics, Princeton University, weinan@princeton.edu 2 School of Mathematical Sciences, Peking University,
Static unconstrained optimization
 Static unconstrained optimization 2 In unconstrained optimization an objective function is minimized without any additional restriction on the decision variables, i.e. min f(x) x X ad (2.) with X ad R
Static unconstrained optimization 2 In unconstrained optimization an objective function is minimized without any additional restriction on the decision variables, i.e. min f(x) x X ad (2.) with X ad R
Practical Optimization: Basic Multidimensional Gradient Methods
 Practical Optimization: Basic Multidimensional Gradient Methods László Kozma Lkozma@cis.hut.fi Helsinki University of Technology S-88.4221 Postgraduate Seminar on Signal Processing 22. 10. 2008 Contents
Practical Optimization: Basic Multidimensional Gradient Methods László Kozma Lkozma@cis.hut.fi Helsinki University of Technology S-88.4221 Postgraduate Seminar on Signal Processing 22. 10. 2008 Contents
Mathematical optimization
 Optimization Mathematical optimization Determine the best solutions to certain mathematically defined problems that are under constrained determine optimality criteria determine the convergence of the
Optimization Mathematical optimization Determine the best solutions to certain mathematically defined problems that are under constrained determine optimality criteria determine the convergence of the
Algorithms for Constrained Optimization
 1 / 42 Algorithms for Constrained Optimization ME598/494 Lecture Max Yi Ren Department of Mechanical Engineering, Arizona State University April 19, 2015 2 / 42 Outline 1. Convergence 2. Sequential quadratic
1 / 42 Algorithms for Constrained Optimization ME598/494 Lecture Max Yi Ren Department of Mechanical Engineering, Arizona State University April 19, 2015 2 / 42 Outline 1. Convergence 2. Sequential quadratic
Minimization of Static! Cost Functions!
 Minimization of Static Cost Functions Robert Stengel Optimal Control and Estimation, MAE 546, Princeton University, 2017 J = Static cost function with constant control parameter vector, u Conditions for
Minimization of Static Cost Functions Robert Stengel Optimal Control and Estimation, MAE 546, Princeton University, 2017 J = Static cost function with constant control parameter vector, u Conditions for
Convex Optimization CMU-10725
 Convex Optimization CMU-10725 Quasi Newton Methods Barnabás Póczos & Ryan Tibshirani Quasi Newton Methods 2 Outline Modified Newton Method Rank one correction of the inverse Rank two correction of the
Convex Optimization CMU-10725 Quasi Newton Methods Barnabás Póczos & Ryan Tibshirani Quasi Newton Methods 2 Outline Modified Newton Method Rank one correction of the inverse Rank two correction of the
Lecture 7: Minimization or maximization of functions (Recipes Chapter 10)
") Lecture 7: Minimization or maximization of functions (Recipes Chapter 10) Actively studied subject for several reasons: Commonly encountered problem: e.g. Hamilton s and Lagrange s principles, economics
Lecture 7: Minimization or maximization of functions (Recipes Chapter 10) Actively studied subject for several reasons: Commonly encountered problem: e.g. Hamilton s and Lagrange s principles, economics
CE 191: Civil and Environmental Engineering Systems Analysis. LEC 05 : Optimality Conditions
 CE 191: Civil and Environmental Engineering Systems Analysis LEC : Optimality Conditions Professor Scott Moura Civil & Environmental Engineering University of California, Berkeley Fall 214 Prof. Moura
CE 191: Civil and Environmental Engineering Systems Analysis LEC : Optimality Conditions Professor Scott Moura Civil & Environmental Engineering University of California, Berkeley Fall 214 Prof. Moura
8 Numerical methods for unconstrained problems
 8 Numerical methods for unconstrained problems Optimization is one of the important fields in numerical computation, beside solving differential equations and linear systems. We can see that these fields
8 Numerical methods for unconstrained problems Optimization is one of the important fields in numerical computation, beside solving differential equations and linear systems. We can see that these fields
(One Dimension) Problem: for a function f(x), find x 0 such that f(x 0 ) = 0. f(x)
 Problem: for a function f(x), find x 0 such that f(x 0 ) = 0. f(x)") Solving Nonlinear Equations & Optimization One Dimension Problem: or a unction, ind 0 such that 0 = 0. 0 One Root: The Bisection Method This one s guaranteed to converge at least to a singularity, i not
Solving Nonlinear Equations & Optimization One Dimension Problem: or a unction, ind 0 such that 0 = 0. 0 One Root: The Bisection Method This one s guaranteed to converge at least to a singularity, i not
EAD 115. Numerical Solution of Engineering and Scientific Problems. David M. Rocke Department of Applied Science
 EAD 115 Numerical Solution of Engineering and Scientific Problems David M. Rocke Department of Applied Science Taylor s Theorem Can often approximate a function by a polynomial The error in the approximation
EAD 115 Numerical Solution of Engineering and Scientific Problems David M. Rocke Department of Applied Science Taylor s Theorem Can often approximate a function by a polynomial The error in the approximation
Lecture 6 Optimization for Deep Neural Networks
 Lecture 6 Optimization for Deep Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 12, 2017 Things we will look at today Stochastic Gradient Descent Things
Lecture 6 Optimization for Deep Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 12, 2017 Things we will look at today Stochastic Gradient Descent Things
Constrained Optimization
 1 / 22 Constrained Optimization ME598/494 Lecture Max Yi Ren Department of Mechanical Engineering, Arizona State University March 30, 2015 2 / 22 1. Equality constraints only 1.1 Reduced gradient 1.2 Lagrange
1 / 22 Constrained Optimization ME598/494 Lecture Max Yi Ren Department of Mechanical Engineering, Arizona State University March 30, 2015 2 / 22 1. Equality constraints only 1.1 Reduced gradient 1.2 Lagrange
Methods that avoid calculating the Hessian. Nonlinear Optimization; Steepest Descent, Quasi-Newton. Steepest Descent
 Nonlinear Optimization Steepest Descent and Niclas Börlin Department of Computing Science Umeå University niclas.borlin@cs.umu.se A disadvantage with the Newton method is that the Hessian has to be derived
Nonlinear Optimization Steepest Descent and Niclas Börlin Department of Computing Science Umeå University niclas.borlin@cs.umu.se A disadvantage with the Newton method is that the Hessian has to be derived
Optimization for Training I. First-Order Methods Training algorithm
 Optimization for Training I First-Order Methods Training algorithm 2 OPTIMIZATION METHODS Topics: Types of optimization methods. Practical optimization methods breakdown into two categories: 1. First-order
Optimization for Training I First-Order Methods Training algorithm 2 OPTIMIZATION METHODS Topics: Types of optimization methods. Practical optimization methods breakdown into two categories: 1. First-order
Nonlinear Optimization Methods for Machine Learning
 Nonlinear Optimization Methods for Machine Learning Jorge Nocedal Northwestern University University of California, Davis, Sept 2018 1 Introduction We don t really know, do we? a) Deep neural networks
Nonlinear Optimization Methods for Machine Learning Jorge Nocedal Northwestern University University of California, Davis, Sept 2018 1 Introduction We don t really know, do we? a) Deep neural networks
4TE3/6TE3. Algorithms for. Continuous Optimization
 4TE3/6TE3 Algorithms for Continuous Optimization (Algorithms for Constrained Nonlinear Optimization Problems) Tamás TERLAKY Computing and Software McMaster University Hamilton, November 2005 terlaky@mcmaster.ca
4TE3/6TE3 Algorithms for Continuous Optimization (Algorithms for Constrained Nonlinear Optimization Problems) Tamás TERLAKY Computing and Software McMaster University Hamilton, November 2005 terlaky@mcmaster.ca
Numerical Analysis of Electromagnetic Fields
 Pei-bai Zhou Numerical Analysis of Electromagnetic Fields With 157 Figures Springer-Verlag Berlin Heidelberg New York London Paris Tokyo Hong Kong Barcelona Budapest Contents Part 1 Universal Concepts
Pei-bai Zhou Numerical Analysis of Electromagnetic Fields With 157 Figures Springer-Verlag Berlin Heidelberg New York London Paris Tokyo Hong Kong Barcelona Budapest Contents Part 1 Universal Concepts
5 Quasi-Newton Methods
 Unconstrained Convex Optimization 26 5 Quasi-Newton Methods If the Hessian is unavailable... Notation: H = Hessian matrix. B is the approximation of H. C is the approximation of H 1. Problem: Solve min
Unconstrained Convex Optimization 26 5 Quasi-Newton Methods If the Hessian is unavailable... Notation: H = Hessian matrix. B is the approximation of H. C is the approximation of H 1. Problem: Solve min
Numerical optimization. Numerical optimization. Longest Shortest where Maximal Minimal. Fastest. Largest. Optimization problems
 1 Numerical optimization Alexander & Michael Bronstein, 2006-2009 Michael Bronstein, 2010 tosca.cs.technion.ac.il/book Numerical optimization 048921 Advanced topics in vision Processing and Analysis of
1 Numerical optimization Alexander & Michael Bronstein, 2006-2009 Michael Bronstein, 2010 tosca.cs.technion.ac.il/book Numerical optimization 048921 Advanced topics in vision Processing and Analysis of
Math 273a: Optimization Netwon s methods
 Math 273a: Optimization Netwon s methods Instructor: Wotao Yin Department of Mathematics, UCLA Fall 2015 some material taken from Chong-Zak, 4th Ed. Main features of Newton s method Uses both first derivatives
Math 273a: Optimization Netwon s methods Instructor: Wotao Yin Department of Mathematics, UCLA Fall 2015 some material taken from Chong-Zak, 4th Ed. Main features of Newton s method Uses both first derivatives
Gradient-Based Optimization
 Multidisciplinary Design Optimization 48 Chapter 3 Gradient-Based Optimization 3. Introduction In Chapter we described methods to minimize (or at least decrease) a function of one variable. While problems
Multidisciplinary Design Optimization 48 Chapter 3 Gradient-Based Optimization 3. Introduction In Chapter we described methods to minimize (or at least decrease) a function of one variable. While problems
Written Examination
 Division of Scientific Computing Department of Information Technology Uppsala University Optimization Written Examination 202-2-20 Time: 4:00-9:00 Allowed Tools: Pocket Calculator, one A4 paper with notes
Division of Scientific Computing Department of Information Technology Uppsala University Optimization Written Examination 202-2-20 Time: 4:00-9:00 Allowed Tools: Pocket Calculator, one A4 paper with notes
Optimization. Escuela de Ingeniería Informática de Oviedo. (Dpto. de Matemáticas-UniOvi) Numerical Computation Optimization 1 / 30
 Numerical Computation Optimization 1 / 30") Optimization Escuela de Ingeniería Informática de Oviedo (Dpto. de Matemáticas-UniOvi) Numerical Computation Optimization 1 / 30 Unconstrained optimization Outline 1 Unconstrained optimization 2 Constrained
Optimization Escuela de Ingeniería Informática de Oviedo (Dpto. de Matemáticas-UniOvi) Numerical Computation Optimization 1 / 30 Unconstrained optimization Outline 1 Unconstrained optimization 2 Constrained
Numerical optimization
 Numerical optimization Lecture 4 Alexander & Michael Bronstein tosca.cs.technion.ac.il/book Numerical geometry of non-rigid shapes Stanford University, Winter 2009 2 Longest Slowest Shortest Minimal Maximal
Numerical optimization Lecture 4 Alexander & Michael Bronstein tosca.cs.technion.ac.il/book Numerical geometry of non-rigid shapes Stanford University, Winter 2009 2 Longest Slowest Shortest Minimal Maximal
Day 3 Lecture 3. Optimizing deep networks
 Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
IPAM Summer School Optimization methods for machine learning. Jorge Nocedal
 IPAM Summer School 2012 Tutorial on Optimization methods for machine learning Jorge Nocedal Northwestern University Overview 1. We discuss some characteristics of optimization problems arising in deep
IPAM Summer School 2012 Tutorial on Optimization methods for machine learning Jorge Nocedal Northwestern University Overview 1. We discuss some characteristics of optimization problems arising in deep
Physics 403. Segev BenZvi. Numerical Methods, Maximum Likelihood, and Least Squares. Department of Physics and Astronomy University of Rochester
 Physics 403 Numerical Methods, Maximum Likelihood, and Least Squares Segev BenZvi Department of Physics and Astronomy University of Rochester Table of Contents 1 Review of Last Class Quadratic Approximation
Physics 403 Numerical Methods, Maximum Likelihood, and Least Squares Segev BenZvi Department of Physics and Astronomy University of Rochester Table of Contents 1 Review of Last Class Quadratic Approximation
Improving the Convergence of Back-Propogation Learning with Second Order Methods
 the of Back-Propogation Learning with Second Order Methods Sue Becker and Yann le Cun, Sept 1988 Kasey Bray, October 2017 Table of Contents 1 with Back-Propagation 2 the of BP 3 A Computationally Feasible
the of Back-Propogation Learning with Second Order Methods Sue Becker and Yann le Cun, Sept 1988 Kasey Bray, October 2017 Table of Contents 1 with Back-Propagation 2 the of BP 3 A Computationally Feasible
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Non-Convex Optimization. CS6787 Lecture 7 Fall 2017
 Non-Convex Optimization CS6787 Lecture 7 Fall 2017 First some words about grading I sent out a bunch of grades on the course management system Everyone should have all their grades in Not including paper
Non-Convex Optimization CS6787 Lecture 7 Fall 2017 First some words about grading I sent out a bunch of grades on the course management system Everyone should have all their grades in Not including paper
Optimality Conditions
 Chapter 2 Optimality Conditions 2.1 Global and Local Minima for Unconstrained Problems When a minimization problem does not have any constraints, the problem is to find the minimum of the objective function.
Chapter 2 Optimality Conditions 2.1 Global and Local Minima for Unconstrained Problems When a minimization problem does not have any constraints, the problem is to find the minimum of the objective function.
arxiv: v1 [math.oc] 10 Apr 2017
![arxiv: v1 [math.oc] 10 Apr 2017](/thumbs/93/111917857.jpg "arxiv: v1 [math.oc] 10 Apr 2017") A Method to Guarantee Local Convergence for Sequential Quadratic Programming with Poor Hessian Approximation Tuan T. Nguyen, Mircea Lazar and Hans Butler arxiv:1704.03064v1 math.oc] 10 Apr 2017 Abstract
A Method to Guarantee Local Convergence for Sequential Quadratic Programming with Poor Hessian Approximation Tuan T. Nguyen, Mircea Lazar and Hans Butler arxiv:1704.03064v1 math.oc] 10 Apr 2017 Abstract
Tutorial on: Optimization I. (from a deep learning perspective) Jimmy Ba
 Jimmy Ba") Tutorial on: Optimization I (from a deep learning perspective) Jimmy Ba Outline Random search v.s. gradient descent Finding better search directions Design white-box optimization methods to improve computation
Tutorial on: Optimization I (from a deep learning perspective) Jimmy Ba Outline Random search v.s. gradient descent Finding better search directions Design white-box optimization methods to improve computation
Support Vector Machines: Maximum Margin Classifiers
 Support Vector Machines: Maximum Margin Classifiers Machine Learning and Pattern Recognition: September 16, 2008 Piotr Mirowski Based on slides by Sumit Chopra and Fu-Jie Huang 1 Outline What is behind
Support Vector Machines: Maximum Margin Classifiers Machine Learning and Pattern Recognition: September 16, 2008 Piotr Mirowski Based on slides by Sumit Chopra and Fu-Jie Huang 1 Outline What is behind
Optimisation in Higher Dimensions
 CHAPTER 6 Optimisation in Higher Dimensions Beyond optimisation in 1D, we will study two directions. First, the equivalent in nth dimension, x R n such that f(x ) f(x) for all x R n. Second, constrained
CHAPTER 6 Optimisation in Higher Dimensions Beyond optimisation in 1D, we will study two directions. First, the equivalent in nth dimension, x R n such that f(x ) f(x) for all x R n. Second, constrained
Lectures 9 and 10: Constrained optimization problems and their optimality conditions
 Lectures 9 and 10: Constrained optimization problems and their optimality conditions Coralia Cartis, Mathematical Institute, University of Oxford C6.2/B2: Continuous Optimization Lectures 9 and 10: Constrained
Lectures 9 and 10: Constrained optimization problems and their optimality conditions Coralia Cartis, Mathematical Institute, University of Oxford C6.2/B2: Continuous Optimization Lectures 9 and 10: Constrained
Chapter 2. Optimization. Gradients, convexity, and ALS
 Chapter 2 Optimization Gradients, convexity, and ALS Contents Background Gradient descent Stochastic gradient descent Newton s method Alternating least squares KKT conditions 2 Motivation We can solve
Chapter 2 Optimization Gradients, convexity, and ALS Contents Background Gradient descent Stochastic gradient descent Newton s method Alternating least squares KKT conditions 2 Motivation We can solve
Convex Optimization. Problem set 2. Due Monday April 26th
 Convex Optimization Problem set 2 Due Monday April 26th 1 Gradient Decent without Line-search In this problem we will consider gradient descent with predetermined step sizes. That is, instead of determining
Convex Optimization Problem set 2 Due Monday April 26th 1 Gradient Decent without Line-search In this problem we will consider gradient descent with predetermined step sizes. That is, instead of determining
MS&E 318 (CME 338) Large-Scale Numerical Optimization
 Large-Scale Numerical Optimization") Stanford University, Management Science & Engineering (and ICME) MS&E 318 (CME 338) Large-Scale Numerical Optimization 1 Origins Instructor: Michael Saunders Spring 2015 Notes 9: Augmented Lagrangian Methods
Stanford University, Management Science & Engineering (and ICME) MS&E 318 (CME 338) Large-Scale Numerical Optimization 1 Origins Instructor: Michael Saunders Spring 2015 Notes 9: Augmented Lagrangian Methods
NUMERICAL MATHEMATICS AND COMPUTING
 NUMERICAL MATHEMATICS AND COMPUTING Fourth Edition Ward Cheney David Kincaid The University of Texas at Austin 9 Brooks/Cole Publishing Company I(T)P An International Thomson Publishing Company Pacific
NUMERICAL MATHEMATICS AND COMPUTING Fourth Edition Ward Cheney David Kincaid The University of Texas at Austin 9 Brooks/Cole Publishing Company I(T)P An International Thomson Publishing Company Pacific
Chapter 3 Numerical Methods
 Chapter 3 Numerical Methods Part 2 3.2 Systems of Equations 3.3 Nonlinear and Constrained Optimization 1 Outline 3.2 Systems of Equations 3.3 Nonlinear and Constrained Optimization Summary 2 Outline 3.2
Chapter 3 Numerical Methods Part 2 3.2 Systems of Equations 3.3 Nonlinear and Constrained Optimization 1 Outline 3.2 Systems of Equations 3.3 Nonlinear and Constrained Optimization Summary 2 Outline 3.2
Computational Finance
 Department of Mathematics at University of California, San Diego Computational Finance Optimization Techniques [Lecture 2] Michael Holst January 9, 2017 Contents 1 Optimization Techniques 3 1.1 Examples
Department of Mathematics at University of California, San Diego Computational Finance Optimization Techniques [Lecture 2] Michael Holst January 9, 2017 Contents 1 Optimization Techniques 3 1.1 Examples
Overview of gradient descent optimization algorithms. HYUNG IL KOO Based on
 Overview of gradient descent optimization algorithms HYUNG IL KOO Based on http://sebastianruder.com/optimizing-gradient-descent/ Problem Statement Machine Learning Optimization Problem Training samples:
Overview of gradient descent optimization algorithms HYUNG IL KOO Based on http://sebastianruder.com/optimizing-gradient-descent/ Problem Statement Machine Learning Optimization Problem Training samples: