Binomial Logis5c Regression with glm()
|
|
|
- Daniel Alvin Hoover
- 5 years ago
- Views:
Transcription
1 Friday 10/10/2014
2 Binomial Logis5c Regression with glm()
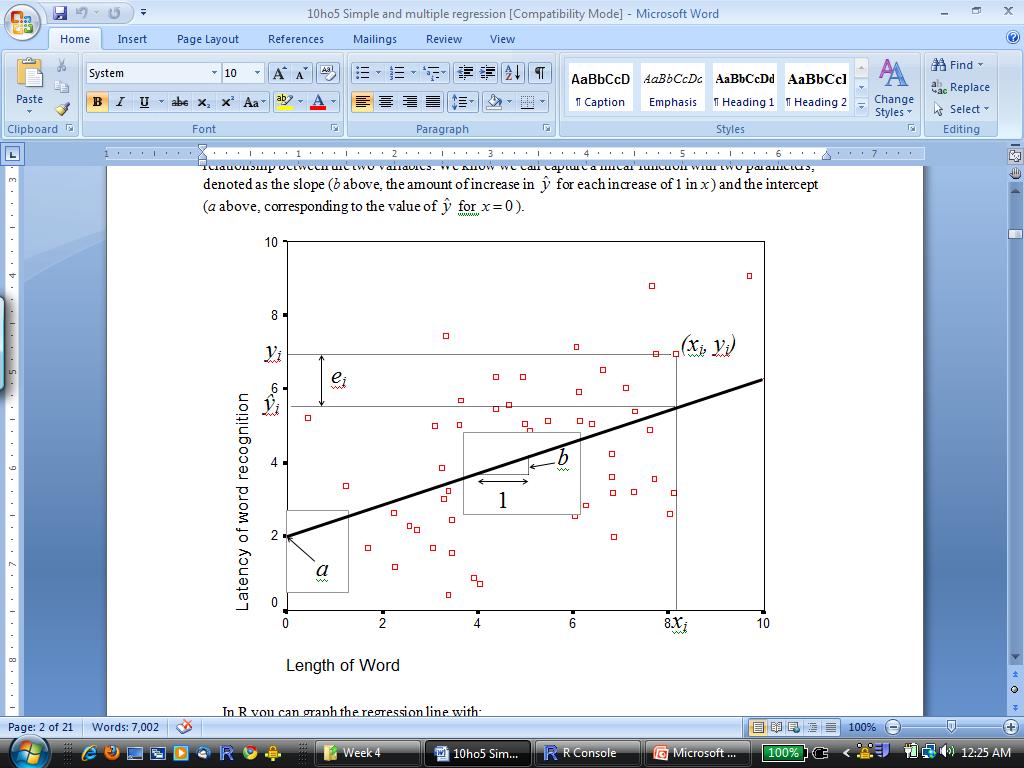
3 > plot(x,y) > abline(reg=lm(y~x))
4 Binomial Logis5c Regression numsessions relapse No relapse 1.15 No relapse 1.87 No relapse.62 No relapse -.47 Relapse.88 No relapse -.99 Relapse.81 No relapse.44 No relapse Relapse.52 No relapse.14 Relapse -.49 Relapse.60 No relapse -.03 No relapse -.43 Relapse -.94 Relapse -.06 Relapse -.84 Relapse Relapse
5
6 The Logis5c Func5on 1 e x 1+ e x 0 x
7 The Exponen5al Func5on e x e = log(e x ) = x e log(x) = x e x * e Y = e x+y e 0 = 1 > curve(exp(x),-5,+5) > rbind(-3:3,round(exp(-3:3),2)) [,1] [,2] [,3] [,4] [,5] [,6] [,7] [1,] [2,]
) The Logis5c Func5on 0 1")
8 y p p e p p p e p e p e p e pe p e e p e e p y y y y y y y y y y ˆ 1 log 1 ) (1 * ) (1 1 ˆ ˆ ˆ ˆ ˆ ˆ ˆ ˆ ˆ ˆ = = = = = + = + + = x x e e 1+ logit = log(p/(1- p)) The Logis5c Func5on 0 1 x
9 > glm(relapse~numsessions,family="binomial") Call: glm(formula = relapse ~ numsessions, family = "binomial") Coefficients: (Intercept) numsessions Degrees of Freedom: 19 Total (i.e. Null); 18 Residual Null Deviance: Residual Deviance: AIC: p( relapse) log 1 ( ) p relapse = * Numsessions.186 At numsess = 0 (i.e. at the mean) p( relapse) log 1 p( relapse) =.186 p relapse) 1 p( relapse) (. 186 = e =.83 At numsess = 1 p relapse) 1 p( relapse) ( = e =.10 At numsess = - 1 p relapse) 1 p( relapse) ( = e = 6.73
10 e 1+ e yˆ e p = 1+ e * Numsessions p ( relapse) = * Numsessions yˆ At mean numssessions (0) p(relapse) = 45% At high numssessions (+1) p(relapse) = 9% At low numssessions (- 1) p(relapse) = 87% a< ; b< numsessions<-seq(-3,3,by=.01) p_relapse<-exp(a+b*numsessions)/(1+exp(a+b*numsessions)) plot(numsessions,p_relapse,cex=.5,col="blue")
11 b = - 20 b = - 5 b = - 1 b = +5
12 Mul5ple Regression
13 Mul5ple Regression y ˆ = a + bx ˆ = b b x b x b x y yˆ = bi xi + b 0
14 ID GPA SAT GPA Reco (College) (%) (High) id coll_gpa sat recs hs_gpa > round(cor(data0),2) ID coll_gpa sat recs hs_gpa ID coll_gpa sat recs hs_gpa
15 > summary(lm(coll_gpa~sat,data=data0)) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) ** sat *** --- Residual standard error: on 18 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 1 and 18 DF, p-value: > summary(lm(coll_gpa~sat+recs,data=data0)) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) ** sat *** recs * --- Residual standard error: on 17 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: 15.5 on 2 and 17 DF, p-value: > summary(lm(coll_gpa~sat+hs_gpa,data=data0)) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) ** sat * hs_gpa * --- Residual standard error: on 17 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 2 and 17 DF, p-value:
16 sat hs_gpa model2$residuals hs_gpa coll_gpa model2$residuals (SAT controlling for hs_gpa)
![> round(cor(hs_gpa,model2$residuals),3) [1] 0 > summary(lm(coll_gpa~model2$resid)) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) 3.3650 0.0887 37.938 <2e-16 *** model2$resid 0.0138 0.](/docs-images/91/107111396/images/17-2.jpg "0090 1.533 0.143 --- Residual standard error: 0.3967 on 18 degrees of freedom Multiple R-squared: 0.1155,Adjusted R-squared: 0.06638 F-statistic: 2.351 on 1 and 18 DF, p-value: 0.")
17 > round(cor(hs_gpa,model2$residuals),3) [1] 0 > summary(lm(coll_gpa~model2$resid)) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) <2e-16 *** model2$resid Residual standard error: on 18 degrees of freedom Multiple R-squared: ,Adjusted R-squared: F-statistic: on 1 and 18 DF, p-value: Standardized Coefficients b s β i i i = s 0 Residual Variance MS Re sidual ( Y = MSError = N Yˆ) p 1 2 See lm.beta() in package QuantPsyc Note that this is the square of the residual standard error above or the standard error of the esmmate (s Y.X )
18 > summary(lm(coll_gpa~hs_gpa+sat+recs,data=data0)) Call: lm(formula = coll_gpa ~ hs_gpa + sat + recs, data = data0) Residuals: Min 1Q Median 3Q Max Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) ** hs_gpa sat * recs * --- Signif. codes: 0 *** ** 0.01 * Residual standard error: on 16 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 3 and 16 DF, p-value: > confint(lm(coll_gpa~sat+hs_gpa,data=data0)) 2.5 % 97.5 % (Intercept) hs_gpa sat recs
19 R = r YY ˆ This is the mulmple correlamon coefficient. > cor(coll_gpa,lm(coll_gpa~sat+hs_gpa)$fitted) [1] > cor(coll_gpa,lm(coll_gpa~sat+hs_gpa)$fitted)^2 [1] > summary(lm(coll_gpa~sat+hs_gpa,data=data0)) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) ** sat * hs_gpa * --- Residual standard error: on 17 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 2 and 17 DF, p-value:
20 r YY R ˆ = 1 1) )( ( = p N N R adjr ) (1 1) ( 2 2 R p R p N F =, with (p, N-p-1) degrees of freedom. ) )(1 ( ) 1)( ( 1) /( ) ) /( ( ), ( f r f f r f f N r f R r f R R f N f N SSE r f SSR SSR F = =
21 F ( f r, N f 1) = ( SSR f SSE f SSR r ) /( f /( N f 1) r) = ( N ( f f 1)( R 2 f r)(1 R 2 f R ) 2 r ) > length(coef(model2))-1->f > length(coef(model3))-1->r > length(data0$coll_gpa)->n > summary(model2)[8][[1]]->r2f > summary(model3)[8][[1]]->r2r > > (N-f-1)*(R2f-R2r)/((f-r)*(1-R2f)) [1] > anova(model2,model3) Analysis of Variance Table Model 1: coll_gpa ~ hs_gpa + sat + recs Model 2: coll_gpa ~ sat + recs Res.Df RSS Df Sum of Sq F Pr(>F) Signif. codes: 0 *** ** 0.01 *
 {round((cor(x,y)-cor(x,z)*cor(y,z))/sqrt((1- cor(x,z)^2)*(1-cor(y,z)^2)),2)} > ls() [1] \"bm.partial\" \"data1\" > bm.partial(data1$icecream,data1$drownings,data1$heat) [1] 0.")
22 Par5al Correla5on > round(cor(data1),2) r y1 2 = r y1 (1 r r r y2 )(1 r 2 y2 ) icecream drownings heat icecream drownings heat > bm.partial<-function(x,y,z) {round((cor(x,y)-cor(x,z)*cor(y,z))/sqrt((1- cor(x,z)^2)*(1-cor(y,z)^2)),2)} > ls() [1] "bm.partial" "data1" > bm.partial(data1$icecream,data1$drownings,data1$heat) [1] 0.08 # Now I am repeating it with the formula from the psych package > library(psych) > partial.r(data1,1:2,3) icecream drownings icecream drownings # Note that we obtain the same result by correlating residuals: > cor(lm(icecream~heat,data=data1)$residuals,lm(drownings~heat,data=data1)$residuals) [1]
 {round((cor(x,y)-cor(x,z)*cor(y,z))/sqrt((1- cor(y,z)^2)),2)} > bm.semipartial(racetime,practicetime,practicetrack) [1] 0.")
23 Semi- Par5al (Part) Correla5on r 0(1 2) = ( r 01 r 02 (1 r r ) ) > round(cor(data2),2) racetime practicetime practicetrack racetime practicetime practicetrack > bm.semipartial<-function(x,y,z) {round((cor(x,y)-cor(x,z)*cor(y,z))/sqrt((1- cor(y,z)^2)),2)} > bm.semipartial(racetime,practicetime,practicetrack) [1] 0.39 # Note that you get a very similar result by correlating a residual with racetime # But in contrast to the partial correl, only one of the two terms is a residual here. > cor(data2$racetime,lm(practicetime~practicetrack,data=data2)$residuals) [1]

24 Breaking Down the SS X 0 a e b c f d g X 1 X 2
25 R 2 can be high while none of the predictors are significant! > summary(lm(y2~x3+x4,data=data3)) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) X X Residual standard error: 2.31 on 24 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 2 and 24 DF, p-value: 5.68e-09 > cor(data3[,7:9]) X3 X4 Y2 X X Y Y 2 a b c X 3 d X 4
26 > summary(lm(y~x1,data=data3)) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) X * --- Residual standard error: on 25 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 1 and 25 DF, p-value: > summary(lm(y~x2,data=data3)) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) X ** --- Residual standard error: on 25 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 1 and 25 DF, p-value: > summary(lm(y~x1+x2,data=data3)) Coefficients: NoMce how the coefficient for X2 goes up even as it gets less significant. Estimate Std. Error t value Pr(> t ) (Intercept) X X * --- Residual standard error: on 24 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 2 and 24 DF, p-value:
27 X X2.1 (Residuals) X X1


28 > lm(x1~x2,data=data3)$residuals->data3$x1.2 X1 X2 Y X2.1 X1.2 X X Y X X
29 > summary(lm(y~x1.2,data=data3)) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) ** X Residual standard error: on 25 degrees of freedom Multiple R-squared: 2.438e-05, Adjusted R-squared: F-statistic: on 1 and 25 DF, p-value: > summary(lm(y~x2.1,data=data3)) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) *** X Residual standard error: on 25 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 1 and 25 DF, p-value: > summary(lm(y~x1+x2.1,data=data3)) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) X * X * --- Residual standard error: on 24 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 2 and 24 DF, p-value:
30 > summary(lm(y~x1.2+x2.1,data=data3)) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) *** X * X ** --- Residual standard error: on 24 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 2 and 24 DF, p-value: Y 68% X 2 14% 18% X 1 Predictors: X1 X1.2 X2 X2.1 Intercept R 2 X1 14.5* X2 1.2** X1 and X * X **.00 X **.14 X1 and X * 1.2* X2 and X ** X1.2 and X * 2.7** 45.3**.32
31 Monday 10/13/2014
32 > names(model1) [1] "coefficients" "residuals" "effects" "rank" "fitted.values" [6] "assign" "qr" "df.residual" "xlevels" "call" [11] "terms" "model" > model1$fitted > model1$residuals > model1$df [1] 18
33 WARNING: anova(lm()) parmmons the sum of square sequenmally so order of predictor maaers! > summary(lm(y~x1)) (Intercept) *** x * > summary(lm(y~x2)) (Intercept) e-11 *** x > summary(lm(y~x1+x2)) (Intercept) *** x x > summary(lm(y~x2+x1)) (Intercept) *** x x Signif. codes: 0 *** ** 0.01 * Residual standard error: on 97 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 2 and 97 DF, p-value: In lm() the order does not maaer
) Df Sum Sq Mean Sq F value Pr(>F) x1 1 49.")
34 > summary(lm(y~x2+x1)) (Intercept) *** x x Signif. codes: 0 *** ** 0.01 * Residual standard error: on 97 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 2 and 97 DF, p-value: > anova(lm(y~x1+x2)) Df Sum Sq Mean Sq F value Pr(>F) x * x Residuals Now the order maaers! > anova(lm(y~x2+x1)) Df Sum Sq Mean Sq F value Pr(>F) x x Residuals
35 10 predict() > model1$call lm(formula = coll_gpa ~ hs_gpa) > predict(model1,list(hs_gpa=3.4)) Y X > model2$call lm(formula = coll_gpa ~ hs_gpa + sat + recs, data = data0) > predict(model2,list(hs_gpa=c(3.4,2.9),sat=c(60,90),recs=c(4,5))) > predict(model2,list(hs_gpa=c(3.4,2.9),sat=c(60,90),recs=c(4,5)), interval="confidence") fit lwr upr > predict(model2,list(hs_gpa=c(3.4,2.9),sat=c(60,90),recs=c(4,5)) interval="prediction") fit lwr upr For a discussion of predicmon vs. confidence intervals see: hap://en.wikipedia.org/wiki/predicmon_interval
36 > with(data0,plot(coll_gpa,hs_gpa)) > abline(model1) abline()
37 hap://cran.r- project.org/web/packages/scaaerplot3d/index.html (The easiest thing to do is to install it within R, or download the.zip here.) scaaerplot3d() with(data0,scatterplot3d(sat,recs,coll_gpa))
38 scaaerplot3d() with(data0,scatterplot3d(sat,recs,coll_gpa,pch=16,color="red"))
39 scaaerplot3d() with(data0,scatterplot3d(sat,recs,coll_gpa,pch=16,color="red",type="h"))
40 scaaerplot3d()$plane3d() > model3$call lm(formula = coll_gpa ~ sat + recs, data = data0) > with(data0,scatterplot3d(sat,recs,coll_gpa,pch=16,color="red",type="h"))->my3d > names(my3d) [1] "xyz.convert" "points3d" "plane3d" "box3d" > my3d$plane3d(model3)
41 Dummy Coding
 x y Min. :1.00 Min. : 1.020 1st Qu.:1.00 1st Qu.: 5.325 Median :2.00 Median : 6.510 Mean :2.16 Mean : 6.409 3rd Qu.:3.00 3rd Qu.: 7.965 Max. :3.00 Max.")
42 Imagine a study with 50 par5cipants split unevenly into 3 groups (X) and measured on a dv Y. > str(d) 'data.frame': 50 obs. of 2 variables: $ x: num $ y: num > summary(d) x y Min. :1.00 Min. : st Qu.:1.00 1st Qu.: Median :2.00 Median : Mean :2.16 Mean : rd Qu.:3.00 3rd Qu.: Max. :3.00 Max. : > table(d$x) > round(tapply(d$y,d$x,mean),2)
43 In this first pass we treat X as if it was a con5nuous variable. > summary(lm(y~x,data=d)) Call: lm(formula = y ~ x, data = d) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) e-08 *** x * --- Signif. codes: 0 *** ** 0.01 * Residual standard error: on 48 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 1 and 48 DF, p-value:
44 > as.factor(d$x)->d$x > summary(lm(y~x,data=d)) Call: lm(formula = y ~ x, data = d) Residuals: Min 1Q Median 3Q Max y ˆ = b + b x2 + b x Where x2 and x3 each take the values 0 or 1. Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) e-14 *** x * x * --- Signif. codes: 0 *** ** 0.01 * Residual standard error: 1.99 on 47 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 2 and 47 DF, p-value: > tapply(d$y,d$x,mean)->means > means[2]-means[1] > means[3]-means[1] Now when X is a factor, lm() gives two dummy codes corresponding to the difference in means from Group 1.
45 > factor(sample(c("control","before","after"),50,replace=t))->d$z > str(d) 'data.frame': 50 obs. of 3 variables: $ x: Factor w/ 3 levels 1", 2", 3": $ y: num $ z: Factor w/ 3 levels "After","Before",..: > summary(lm(y~z,data=d)) Call: lm(formula = y ~ z, data = d) Residuals: Min 1Q Median 3Q Max As is illustrated here, the reference group is the one earliest in the alphabet*, which can be arbitrary [* on values, not labels; here Level 1 is Ader ] Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) <2e-16 *** zbefore zcontrol Signif. codes: 0 *** ** 0.01 * Residual standard error: on 47 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 2 and 47 DF, p-value:
46 > contrasts(d$x) > d[d$x==1,4]<-0 > d[d$x==2,4]<-1 > d[d$x==3,4]<-0 > d[d$x==1,5]<-0 > d[d$x==2,5]<-0 > d[d$x==3,5]<-1 y ˆ = b + b1 x2 + b2 0 x Where x2 and x3 each take the values 0 or 1. > str(d) 'data.frame': 50 obs. of 5 variables: $ x : Factor w/ 3 levels "1","2","3": $ y : num $ z : Factor w/ 3 levels "After","Before",.. $ myx2: num $ myx3: num I want to show you that the contrasts used by R is the same thing as you entered your own dummy coding. 3 > d x y z myx2 myx Control Control After Control Before Before After Control Before After After After Before After Before After Control After After After Before After After Before After Control Before After 0 1 ( )
47 > summary(lm(y~myx2+myx3,data=d)) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) e-14 *** myx * myx * --- Signif. codes: 0 *** ** 0.01 * Residual standard error: 1.99 on 47 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 2 and 47 DF, p-value: > summary(lm(y~x,data=d)) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) e-14 *** x * x * --- Signif. codes: 0 *** ** 0.01 * These two numerical dummy codes give the same result as X as a factor. Residual standard error: 1.99 on 47 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 2 and 47 DF, p-value: y ˆ = b0 + b1 x2 + b2 x Where x2 and x3 each take the values 0 or 1. 3

48 > summary(lm(y~x-1,data=d)) Call: lm(formula = y ~ x - 1, data = d) Coefficients: Estimate Std. Error t value Pr(> t ) x e-14 *** x e-15 *** x < 2e-16 *** --- Signif. codes: 0 *** ** 0.01 * Residual standard error: 1.99 on 47 degrees of freedom Multiple R-squared: 0.918, Adjusted R-squared: F-statistic: on 3 and 47 DF, p-value: < 2.2e-16 > means > 1.99/sqrt(tapply(d$y,d$x,length)) R lets you remove the intercept all 3 means are now tested against zero, using the residual s.e..
49 > summary(lm(y~1,data=d)) On the other hand, the model with only 1 has only an intercept in other words the grand mean. Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) <2e-16 *** Residual standard error: on 49 degrees of freedom > mean(d$y) [1] > sd(d$y) [1] > sd(d$y)/sqrt(49) [1] > sd(d$y)/sqrt(50) [1]
50 R uses the contrasts() command to specify how categorical variables should be handled. TradiMonally this transformamon of categorical variables with k values (k>2) into k- 1 numerical variables is called dummy coding, of which there are 3 major types: 1 Dummy coding 2 Effect coding 3 Contrast coding
 #Bind as rows [,1] [,2] [,3] A \"A1\" \"A2\" \"A3\" B \"B1\" \"B2\" \"B3 > cbind(a,b) #Bind as columns A B [1,] \"A1\" \"B1\" [2,] \"A2\" \"B2\" [3,]")
51 > c('a1','a2','a3')->a > c('b1','b2','b3')->b Let me first remind you quickly how we can make a matrix from vectors using rbind() or cbind(). > rbind(a,b) #Bind as rows [,1] [,2] [,3] A "A1" "A2" "A3" B "B1" "B2" "B3 > cbind(a,b) #Bind as columns A B [1,] "A1" "B1" [2,] "A2" "B2" [3,] "A3" "B3"
) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) 5.2950 0.4974 10.645 4.1e-14 *** x2 1.8290 0.8020 2.280 0.0272 * x3 1.5592 0.6421 2.428 0.")
52 > #Dummy coding (default) > contrasts(d$x) Dummy coding can be simply adjusted by inpu5ng a new matrix of codes into contrast(). Here this is the default matrix. > summary(lm(y~x,data=d)) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) e-14 *** x * x * Residual standard error: 1.99 on 47 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 2 and 47 DF, p-value: > means[2]-means[1] > means[3]-means[1]
![> #Dummy coding (default) > contrasts(d$x)<-cbind(c(1,0,0),c(0,0,1)) > contrasts(d$x) [,1] [,2] Even if you s5ck to simple dummy 1 1 0 coding, you can change which 2 0 0 group is the reference group.](/docs-images/91/107111396/images/53-2.jpg "3 0 1 > summary(lm(y~x,data=d)) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) 7.1240 0.6292 11.32 5e-15 *** x1-1.8290 0.8020-2.28 0.0272 * x2-0.2698 0.7489-0.36 0.")
53 > #Dummy coding (default) > contrasts(d$x)<-cbind(c(1,0,0),c(0,0,1)) > contrasts(d$x) [,1] [,2] Even if you s5ck to simple dummy coding, you can change which group is the reference group > summary(lm(y~x,data=d)) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) e-15 *** x * x Residual standard error: 1.99 on 47 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 2 and 47 DF, p-value: > means[1]-means[2] > means[3]-means[2]
![> cbind(c(1,0,0),c(0,1,0),c(0,0,1))->c > contrasts(d$x)<-c > contrasts(d$x) [,1] [,2]](/docs-images/91/107111396/images/54-2.jpg "1 1 0 2 0 1 3 0 0 No5ce what happens when you try to put more than (k- 1) dummy codes.")
54 > cbind(c(1,0,0),c(0,1,0),c(0,0,1))->c > contrasts(d$x)<-c > contrasts(d$x) [,1] [,2] No5ce what happens when you try to put more than (k- 1) dummy codes.
55 > #Dummy coding (default) > contrasts(d$x) > #Effect coding > contrasts(d$x)<-cbind(c(-1,1,0),c(-1,0,1)) > contrasts(d$x) [,1] [,2]

56 > #Effect coding > contrasts(d$x)<-cbind(c(-1,1,0),c(-1,0,1)) > summary(lm(y~x,data=d)) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) <2e-16 *** x x Signif. codes: 0 *** ** 0.01 * Residual standard error: 1.99 on 47 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 2 and 47 DF, p-value: > mean(d$y) [1] > mean(means) [1] > means[2]-mean(means) > means[3]-mean(means) Effect coding tests departures from the unweighted grand mean.
57 Contrast coding is best to capture Planned contrasts, a priori predic5ons you have made about the pamern of your means
58 Rules for contrast weights Contrast Contrast = a = a x 1 x a a x 2 x = +... = a 1. i a x 2. i i x i 1 Weights sum to zero 2 Orthogonal contrasts k i= 1 k i= 1 a j. i = 0 a1. ia2. i= 0 3 With k groups there are (k 1) orthogonal contrasts
59 > #Dummy coding (default) > contrasts(d$x) > #Effect coding > contrasts(d$x)<-cbind(c(-1,1,0),c(-1,0,1)) > contrasts(d$x) [,1] [,2] > #Contrast coding > contrasts(d$x)<-cbind(c(-2,1,1),c(0,-1,1)) > contrasts(d$x) [,1] [,2]

60 > #Contrast coding > contrasts(d$x)<-cbind(c(-2,1,1),c(0,-1,1)) > summary(lm(y~x,data=d)) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) <2e-16 *** x ** x Signif. codes: 0 *** ** 0.01 * Residual standard error: 1.99 on 47 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 2 and 47 DF, p-value: > mean(means) [1] > (-2)^2+(+1)^2+(+1)^2 [1] 6 > (-2*means[1]+means[2]+means[3])/ > (-means[2]+means[3])/ Contrast coding tests more surgical a priori predic5ons.

61 Contrast coding tests more surgical a priori predic5ons, and can be more complicated: Control Threat 1 Threat 2 Self- Affirma5on
R Output for Linear Models using functions lm(), gls() & glm()
, gls() & glm()") LM 04 lm(), gls() &glm() 1 R Output for Linear Models using functions lm(), gls() & glm() Different kinds of output related to linear models can be obtained in R using function lm() {stats} in the base
LM 04 lm(), gls() &glm() 1 R Output for Linear Models using functions lm(), gls() & glm() Different kinds of output related to linear models can be obtained in R using function lm() {stats} in the base
1 Use of indicator random variables. (Chapter 8)
") 1 Use of indicator random variables. (Chapter 8) let I(A) = 1 if the event A occurs, and I(A) = 0 otherwise. I(A) is referred to as the indicator of the event A. The notation I A is often used. 1 2 Fitting
1 Use of indicator random variables. (Chapter 8) let I(A) = 1 if the event A occurs, and I(A) = 0 otherwise. I(A) is referred to as the indicator of the event A. The notation I A is often used. 1 2 Fitting
Chapter 11: Linear Regression and Correla4on. Correla4on
 Chapter 11: Linear Regression and Correla4on Regression analysis is a sta3s3cal tool that u3lizes the rela3on between two or more quan3ta3ve variables so that one variable can be predicted from the other,
Chapter 11: Linear Regression and Correla4on Regression analysis is a sta3s3cal tool that u3lizes the rela3on between two or more quan3ta3ve variables so that one variable can be predicted from the other,
Homework 9 Sample Solution
 Homework 9 Sample Solution # 1 (Ex 9.12, Ex 9.23) Ex 9.12 (a) Let p vitamin denote the probability of having cold when a person had taken vitamin C, and p placebo denote the probability of having cold
Homework 9 Sample Solution # 1 (Ex 9.12, Ex 9.23) Ex 9.12 (a) Let p vitamin denote the probability of having cold when a person had taken vitamin C, and p placebo denote the probability of having cold
Biostatistics 380 Multiple Regression 1. Multiple Regression
 Biostatistics 0 Multiple Regression ORIGIN 0 Multiple Regression Multiple Regression is an extension of the technique of linear regression to describe the relationship between a single dependent (response)
Biostatistics 0 Multiple Regression ORIGIN 0 Multiple Regression Multiple Regression is an extension of the technique of linear regression to describe the relationship between a single dependent (response)
Module 4: Regression Methods: Concepts and Applications
 Module 4: Regression Methods: Concepts and Applications Example Analysis Code Rebecca Hubbard, Mary Lou Thompson July 11-13, 2018 Install R Go to http://cran.rstudio.com/ (http://cran.rstudio.com/) Click
Module 4: Regression Methods: Concepts and Applications Example Analysis Code Rebecca Hubbard, Mary Lou Thompson July 11-13, 2018 Install R Go to http://cran.rstudio.com/ (http://cran.rstudio.com/) Click
Multiple Regression Introduction to Statistics Using R (Psychology 9041B)
") Multiple Regression Introduction to Statistics Using R (Psychology 9041B) Paul Gribble Winter, 2016 1 Correlation, Regression & Multiple Regression 1.1 Bivariate correlation The Pearson product-moment
Multiple Regression Introduction to Statistics Using R (Psychology 9041B) Paul Gribble Winter, 2016 1 Correlation, Regression & Multiple Regression 1.1 Bivariate correlation The Pearson product-moment
1 Multiple Regression
 1 Multiple Regression In this section, we extend the linear model to the case of several quantitative explanatory variables. There are many issues involved in this problem and this section serves only
1 Multiple Regression In this section, we extend the linear model to the case of several quantitative explanatory variables. There are many issues involved in this problem and this section serves only
Garvan Ins)tute Biosta)s)cal Workshop 16/6/2015. Tuan V. Nguyen. Garvan Ins)tute of Medical Research Sydney, Australia
tute Biosta)s)cal Workshop 16/6/2015. Tuan V. Nguyen. Garvan Ins)tute of Medical Research Sydney, Australia") Garvan Ins)tute Biosta)s)cal Workshop 16/6/2015 Tuan V. Nguyen Tuan V. Nguyen Garvan Ins)tute of Medical Research Sydney, Australia Introduction to linear regression analysis Purposes Ideas of regression
Garvan Ins)tute Biosta)s)cal Workshop 16/6/2015 Tuan V. Nguyen Tuan V. Nguyen Garvan Ins)tute of Medical Research Sydney, Australia Introduction to linear regression analysis Purposes Ideas of regression
Chapter 8: Correlation & Regression
 Chapter 8: Correlation & Regression We can think of ANOVA and the two-sample t-test as applicable to situations where there is a response variable which is quantitative, and another variable that indicates
Chapter 8: Correlation & Regression We can think of ANOVA and the two-sample t-test as applicable to situations where there is a response variable which is quantitative, and another variable that indicates
Workshop 7.4a: Single factor ANOVA
 -1- Workshop 7.4a: Single factor ANOVA Murray Logan November 23, 2016 Table of contents 1 Revision 1 2 Anova Parameterization 2 3 Partitioning of variance (ANOVA) 10 4 Worked Examples 13 1. Revision 1.1.
-1- Workshop 7.4a: Single factor ANOVA Murray Logan November 23, 2016 Table of contents 1 Revision 1 2 Anova Parameterization 2 3 Partitioning of variance (ANOVA) 10 4 Worked Examples 13 1. Revision 1.1.
Stat 5102 Final Exam May 14, 2015
 Stat 5102 Final Exam May 14, 2015 Name Student ID The exam is closed book and closed notes. You may use three 8 1 11 2 sheets of paper with formulas, etc. You may also use the handouts on brand name distributions
Stat 5102 Final Exam May 14, 2015 Name Student ID The exam is closed book and closed notes. You may use three 8 1 11 2 sheets of paper with formulas, etc. You may also use the handouts on brand name distributions
Inference for Regression
 Inference for Regression Section 9.4 Cathy Poliak, Ph.D. cathy@math.uh.edu Office in Fleming 11c Department of Mathematics University of Houston Lecture 13b - 3339 Cathy Poliak, Ph.D. cathy@math.uh.edu
Inference for Regression Section 9.4 Cathy Poliak, Ph.D. cathy@math.uh.edu Office in Fleming 11c Department of Mathematics University of Houston Lecture 13b - 3339 Cathy Poliak, Ph.D. cathy@math.uh.edu
Generalised linear models. Response variable can take a number of different formats
 Generalised linear models Response variable can take a number of different formats Structure Limitations of linear models and GLM theory GLM for count data GLM for presence \ absence data GLM for proportion
Generalised linear models Response variable can take a number of different formats Structure Limitations of linear models and GLM theory GLM for count data GLM for presence \ absence data GLM for proportion
STAT 3022 Spring 2007
 Simple Linear Regression Example These commands reproduce what we did in class. You should enter these in R and see what they do. Start by typing > set.seed(42) to reset the random number generator so
Simple Linear Regression Example These commands reproduce what we did in class. You should enter these in R and see what they do. Start by typing > set.seed(42) to reset the random number generator so
ST430 Exam 2 Solutions
 ST430 Exam 2 Solutions Date: November 9, 2015 Name: Guideline: You may use one-page (front and back of a standard A4 paper) of notes. No laptop or textbook are permitted but you may use a calculator. Giving
ST430 Exam 2 Solutions Date: November 9, 2015 Name: Guideline: You may use one-page (front and back of a standard A4 paper) of notes. No laptop or textbook are permitted but you may use a calculator. Giving
Section 4.6 Simple Linear Regression
 Section 4.6 Simple Linear Regression Objectives ˆ Basic philosophy of SLR and the regression assumptions ˆ Point & interval estimation of the model parameters, and how to make predictions ˆ Point and interval
Section 4.6 Simple Linear Regression Objectives ˆ Basic philosophy of SLR and the regression assumptions ˆ Point & interval estimation of the model parameters, and how to make predictions ˆ Point and interval
Part II { Oneway Anova, Simple Linear Regression and ANCOVA with R
 Part II { Oneway Anova, Simple Linear Regression and ANCOVA with R Gilles Lamothe February 21, 2017 Contents 1 Anova with one factor 2 1.1 The data.......................................... 2 1.2 A visual
Part II { Oneway Anova, Simple Linear Regression and ANCOVA with R Gilles Lamothe February 21, 2017 Contents 1 Anova with one factor 2 1.1 The data.......................................... 2 1.2 A visual
Regression on Faithful with Section 9.3 content
 Regression on Faithful with Section 9.3 content The faithful data frame contains 272 obervational units with variables waiting and eruptions measuring, in minutes, the amount of wait time between eruptions,
Regression on Faithful with Section 9.3 content The faithful data frame contains 272 obervational units with variables waiting and eruptions measuring, in minutes, the amount of wait time between eruptions,
Stat 5303 (Oehlert): Analysis of CR Designs; January
: Analysis of CR Designs; January") Stat 5303 (Oehlert): Analysis of CR Designs; January 2016 1 > resin
Stat 5303 (Oehlert): Analysis of CR Designs; January 2016 1 > resin
Variance Decomposition and Goodness of Fit
 Variance Decomposition and Goodness of Fit 1. Example: Monthly Earnings and Years of Education In this tutorial, we will focus on an example that explores the relationship between total monthly earnings
Variance Decomposition and Goodness of Fit 1. Example: Monthly Earnings and Years of Education In this tutorial, we will focus on an example that explores the relationship between total monthly earnings
cor(dataset$measurement1, dataset$measurement2, method= pearson ) cor.test(datavector1, datavector2, method= pearson )
 cor.test(datavector1, datavector2, method= pearson )") Tutorial 7: Correlation and Regression Correlation Used to test whether two variables are linearly associated. A correlation coefficient (r) indicates the strength and direction of the association. A correlation
Tutorial 7: Correlation and Regression Correlation Used to test whether two variables are linearly associated. A correlation coefficient (r) indicates the strength and direction of the association. A correlation
MODELS WITHOUT AN INTERCEPT
 Consider the balanced two factor design MODELS WITHOUT AN INTERCEPT Factor A 3 levels, indexed j 0, 1, 2; Factor B 5 levels, indexed l 0, 1, 2, 3, 4; n jl 4 replicate observations for each factor level
Consider the balanced two factor design MODELS WITHOUT AN INTERCEPT Factor A 3 levels, indexed j 0, 1, 2; Factor B 5 levels, indexed l 0, 1, 2, 3, 4; n jl 4 replicate observations for each factor level
Extensions of One-Way ANOVA.
 Extensions of One-Way ANOVA http://www.pelagicos.net/classes_biometry_fa18.htm What do I want You to Know What are two main limitations of ANOVA? What two approaches can follow a significant ANOVA? How
Extensions of One-Way ANOVA http://www.pelagicos.net/classes_biometry_fa18.htm What do I want You to Know What are two main limitations of ANOVA? What two approaches can follow a significant ANOVA? How
Example: 1982 State SAT Scores (First year state by state data available)
") Lecture 11 Review Section 3.5 from last Monday (on board) Overview of today s example (on board) Section 3.6, Continued: Nested F tests, review on board first Section 3.4: Interaction for quantitative
Lecture 11 Review Section 3.5 from last Monday (on board) Overview of today s example (on board) Section 3.6, Continued: Nested F tests, review on board first Section 3.4: Interaction for quantitative
Psychology 405: Psychometric Theory
 Psychology 405: Psychometric Theory Homework Problem Set #2 Department of Psychology Northwestern University Evanston, Illinois USA April, 2017 1 / 15 Outline The problem, part 1) The Problem, Part 2)
Psychology 405: Psychometric Theory Homework Problem Set #2 Department of Psychology Northwestern University Evanston, Illinois USA April, 2017 1 / 15 Outline The problem, part 1) The Problem, Part 2)
Tests of Linear Restrictions
 Tests of Linear Restrictions 1. Linear Restricted in Regression Models In this tutorial, we consider tests on general linear restrictions on regression coefficients. In other tutorials, we examine some
Tests of Linear Restrictions 1. Linear Restricted in Regression Models In this tutorial, we consider tests on general linear restrictions on regression coefficients. In other tutorials, we examine some
Biostatistics for physicists fall Correlation Linear regression Analysis of variance
 Biostatistics for physicists fall 2015 Correlation Linear regression Analysis of variance Correlation Example: Antibody level on 38 newborns and their mothers There is a positive correlation in antibody
Biostatistics for physicists fall 2015 Correlation Linear regression Analysis of variance Correlation Example: Antibody level on 38 newborns and their mothers There is a positive correlation in antibody
General Linear Statistical Models - Part III
 General Linear Statistical Models - Part III Statistics 135 Autumn 2005 Copyright c 2005 by Mark E. Irwin Interaction Models Lets examine two models involving Weight and Domestic in the cars93 dataset.
General Linear Statistical Models - Part III Statistics 135 Autumn 2005 Copyright c 2005 by Mark E. Irwin Interaction Models Lets examine two models involving Weight and Domestic in the cars93 dataset.
Using R in 200D Luke Sonnet
 Using R in 200D Luke Sonnet Contents Working with data frames 1 Working with variables........................................... 1 Analyzing data............................................... 3 Random
Using R in 200D Luke Sonnet Contents Working with data frames 1 Working with variables........................................... 1 Analyzing data............................................... 3 Random
Chapter 8 Conclusion
 1 Chapter 8 Conclusion Three questions about test scores (score) and student-teacher ratio (str): a) After controlling for differences in economic characteristics of different districts, does the effect
1 Chapter 8 Conclusion Three questions about test scores (score) and student-teacher ratio (str): a) After controlling for differences in economic characteristics of different districts, does the effect
BMI 541/699 Lecture 22
 BMI 541/699 Lecture 22 Where we are: 1. Introduction and Experimental Design 2. Exploratory Data Analysis 3. Probability 4. T-based methods for continous variables 5. Power and sample size for t-based
BMI 541/699 Lecture 22 Where we are: 1. Introduction and Experimental Design 2. Exploratory Data Analysis 3. Probability 4. T-based methods for continous variables 5. Power and sample size for t-based
Analysis of variance. Gilles Guillot. September 30, Gilles Guillot September 30, / 29
 Analysis of variance Gilles Guillot gigu@dtu.dk September 30, 2013 Gilles Guillot (gigu@dtu.dk) September 30, 2013 1 / 29 1 Introductory example 2 One-way ANOVA 3 Two-way ANOVA 4 Two-way ANOVA with interactions
Analysis of variance Gilles Guillot gigu@dtu.dk September 30, 2013 Gilles Guillot (gigu@dtu.dk) September 30, 2013 1 / 29 1 Introductory example 2 One-way ANOVA 3 Two-way ANOVA 4 Two-way ANOVA with interactions
Confidence Interval for the mean response
 Week 3: Prediction and Confidence Intervals at specified x. Testing lack of fit with replicates at some x's. Inference for the correlation. Introduction to regression with several explanatory variables.
Week 3: Prediction and Confidence Intervals at specified x. Testing lack of fit with replicates at some x's. Inference for the correlation. Introduction to regression with several explanatory variables.
> nrow(hmwk1) # check that the number of observations is correct [1] 36 > attach(hmwk1) # I like to attach the data to avoid the '$' addressing
![> nrow(hmwk1) # check that the number of observations is correct [1] 36 > attach(hmwk1) # I like to attach the data to avoid the '$' addressing](/thumbs/78/76787047.jpg "> nrow(hmwk1) # check that the number of observations is correct [1] 36 > attach(hmwk1) # I like to attach the data to avoid the '$' addressing") Homework #1 Key Spring 2014 Psyx 501, Montana State University Prof. Colleen F Moore Preliminary comments: The design is a 4x3 factorial between-groups. Non-athletes do aerobic training for 6, 4 or 2 weeks,
Homework #1 Key Spring 2014 Psyx 501, Montana State University Prof. Colleen F Moore Preliminary comments: The design is a 4x3 factorial between-groups. Non-athletes do aerobic training for 6, 4 or 2 weeks,
Extensions of One-Way ANOVA.
 Extensions of One-Way ANOVA http://www.pelagicos.net/classes_biometry_fa17.htm What do I want You to Know What are two main limitations of ANOVA? What two approaches can follow a significant ANOVA? How
Extensions of One-Way ANOVA http://www.pelagicos.net/classes_biometry_fa17.htm What do I want You to Know What are two main limitations of ANOVA? What two approaches can follow a significant ANOVA? How
STAT 572 Assignment 5 - Answers Due: March 2, 2007
 1. The file glue.txt contains a data set with the results of an experiment on the dry sheer strength (in pounds per square inch) of birch plywood, bonded with 5 different resin glues A, B, C, D, and E.
1. The file glue.txt contains a data set with the results of an experiment on the dry sheer strength (in pounds per square inch) of birch plywood, bonded with 5 different resin glues A, B, C, D, and E.
Variance Decomposition in Regression James M. Murray, Ph.D. University of Wisconsin - La Crosse Updated: October 04, 2017
 Variance Decomposition in Regression James M. Murray, Ph.D. University of Wisconsin - La Crosse Updated: October 04, 2017 PDF file location: http://www.murraylax.org/rtutorials/regression_anovatable.pdf
Variance Decomposition in Regression James M. Murray, Ph.D. University of Wisconsin - La Crosse Updated: October 04, 2017 PDF file location: http://www.murraylax.org/rtutorials/regression_anovatable.pdf
Regression and the 2-Sample t
 Regression and the 2-Sample t James H. Steiger Department of Psychology and Human Development Vanderbilt University James H. Steiger (Vanderbilt University) Regression and the 2-Sample t 1 / 44 Regression
Regression and the 2-Sample t James H. Steiger Department of Psychology and Human Development Vanderbilt University James H. Steiger (Vanderbilt University) Regression and the 2-Sample t 1 / 44 Regression
1 Introduction 1. 2 The Multiple Regression Model 1
 Multiple Linear Regression Contents 1 Introduction 1 2 The Multiple Regression Model 1 3 Setting Up a Multiple Regression Model 2 3.1 Introduction.............................. 2 3.2 Significance Tests
Multiple Linear Regression Contents 1 Introduction 1 2 The Multiple Regression Model 1 3 Setting Up a Multiple Regression Model 2 3.1 Introduction.............................. 2 3.2 Significance Tests
STAT 215 Confidence and Prediction Intervals in Regression
 STAT 215 Confidence and Prediction Intervals in Regression Colin Reimer Dawson Oberlin College 24 October 2016 Outline Regression Slope Inference Partitioning Variability Prediction Intervals Reminder:
STAT 215 Confidence and Prediction Intervals in Regression Colin Reimer Dawson Oberlin College 24 October 2016 Outline Regression Slope Inference Partitioning Variability Prediction Intervals Reminder:
13 Simple Linear Regression
 B.Sc./Cert./M.Sc. Qualif. - Statistics: Theory and Practice 3 Simple Linear Regression 3. An industrial example A study was undertaken to determine the effect of stirring rate on the amount of impurity
B.Sc./Cert./M.Sc. Qualif. - Statistics: Theory and Practice 3 Simple Linear Regression 3. An industrial example A study was undertaken to determine the effect of stirring rate on the amount of impurity
Example: Poisondata. 22s:152 Applied Linear Regression. Chapter 8: ANOVA
 s:5 Applied Linear Regression Chapter 8: ANOVA Two-way ANOVA Used to compare populations means when the populations are classified by two factors (or categorical variables) For example sex and occupation
s:5 Applied Linear Regression Chapter 8: ANOVA Two-way ANOVA Used to compare populations means when the populations are classified by two factors (or categorical variables) For example sex and occupation
Week 7 Multiple factors. Ch , Some miscellaneous parts
 Week 7 Multiple factors Ch. 18-19, Some miscellaneous parts Multiple Factors Most experiments will involve multiple factors, some of which will be nuisance variables Dealing with these factors requires
Week 7 Multiple factors Ch. 18-19, Some miscellaneous parts Multiple Factors Most experiments will involve multiple factors, some of which will be nuisance variables Dealing with these factors requires
Introduction to Regression in R Part II: Multivariate Linear Regression
 UCLA Department of Statistics Statistical Consulting Center Introduction to Regression in R Part II: Multivariate Linear Regression Denise Ferrari denise@stat.ucla.edu May 14, 2009 Outline 1 Preliminaries
UCLA Department of Statistics Statistical Consulting Center Introduction to Regression in R Part II: Multivariate Linear Regression Denise Ferrari denise@stat.ucla.edu May 14, 2009 Outline 1 Preliminaries
Regression. Bret Hanlon and Bret Larget. December 8 15, Department of Statistics University of Wisconsin Madison.
 Regression Bret Hanlon and Bret Larget Department of Statistics University of Wisconsin Madison December 8 15, 2011 Regression 1 / 55 Example Case Study The proportion of blackness in a male lion s nose
Regression Bret Hanlon and Bret Larget Department of Statistics University of Wisconsin Madison December 8 15, 2011 Regression 1 / 55 Example Case Study The proportion of blackness in a male lion s nose
STA 108 Applied Linear Models: Regression Analysis Spring Solution for Homework #6
 STA 8 Applied Linear Models: Regression Analysis Spring 011 Solution for Homework #6 6. a) = 11 1 31 41 51 1 3 4 5 11 1 31 41 51 β = β1 β β 3 b) = 1 1 1 1 1 11 1 31 41 51 1 3 4 5 β = β 0 β1 β 6.15 a) Stem-and-leaf
STA 8 Applied Linear Models: Regression Analysis Spring 011 Solution for Homework #6 6. a) = 11 1 31 41 51 1 3 4 5 11 1 31 41 51 β = β1 β β 3 b) = 1 1 1 1 1 11 1 31 41 51 1 3 4 5 β = β 0 β1 β 6.15 a) Stem-and-leaf
We d like to know the equation of the line shown (the so called best fit or regression line).
.") Linear Regression in R. Example. Let s create a data frame. > exam1 = c(100,90,90,85,80,75,60) > exam2 = c(95,100,90,80,95,60,40) > students = c("asuka", "Rei", "Shinji", "Mari", "Hikari", "Toji", "Kensuke")
Linear Regression in R. Example. Let s create a data frame. > exam1 = c(100,90,90,85,80,75,60) > exam2 = c(95,100,90,80,95,60,40) > students = c("asuka", "Rei", "Shinji", "Mari", "Hikari", "Toji", "Kensuke")
Chapter 8: Correlation & Regression
 Chapter 8: Correlation & Regression We can think of ANOVA and the two-sample t-test as applicable to situations where there is a response variable which is quantitative, and another variable that indicates
Chapter 8: Correlation & Regression We can think of ANOVA and the two-sample t-test as applicable to situations where there is a response variable which is quantitative, and another variable that indicates
Multiple Regression: Example
 Multiple Regression: Example Cobb-Douglas Production Function The Cobb-Douglas production function for observed economic data i = 1,..., n may be expressed as where O i is output l i is labour input c
Multiple Regression: Example Cobb-Douglas Production Function The Cobb-Douglas production function for observed economic data i = 1,..., n may be expressed as where O i is output l i is labour input c
FACTORIAL DESIGNS and NESTED DESIGNS
 Experimental Design and Statistical Methods Workshop FACTORIAL DESIGNS and NESTED DESIGNS Jesús Piedrafita Arilla jesus.piedrafita@uab.cat Departament de Ciència Animal i dels Aliments Items Factorial
Experimental Design and Statistical Methods Workshop FACTORIAL DESIGNS and NESTED DESIGNS Jesús Piedrafita Arilla jesus.piedrafita@uab.cat Departament de Ciència Animal i dels Aliments Items Factorial
No other aids are allowed. For example you are not allowed to have any other textbook or past exams.
 UNIVERSITY OF TORONTO SCARBOROUGH Department of Computer and Mathematical Sciences Sample Exam Note: This is one of our past exams, In fact the only past exam with R. Before that we were using SAS. In
UNIVERSITY OF TORONTO SCARBOROUGH Department of Computer and Mathematical Sciences Sample Exam Note: This is one of our past exams, In fact the only past exam with R. Before that we were using SAS. In
Introduction and Background to Multilevel Analysis
 Introduction and Background to Multilevel Analysis Dr. J. Kyle Roberts Southern Methodist University Simmons School of Education and Human Development Department of Teaching and Learning Background and
Introduction and Background to Multilevel Analysis Dr. J. Kyle Roberts Southern Methodist University Simmons School of Education and Human Development Department of Teaching and Learning Background and
Interactions in Logistic Regression
 Interactions in Logistic Regression > # UCBAdmissions is a 3-D table: Gender by Dept by Admit > # Same data in another format: > # One col for Yes counts, another for No counts. > Berkeley = read.table("http://www.utstat.toronto.edu/~brunner/312f12/
Interactions in Logistic Regression > # UCBAdmissions is a 3-D table: Gender by Dept by Admit > # Same data in another format: > # One col for Yes counts, another for No counts. > Berkeley = read.table("http://www.utstat.toronto.edu/~brunner/312f12/
Stat 412/512 TWO WAY ANOVA. Charlotte Wickham. stat512.cwick.co.nz. Feb
 Stat 42/52 TWO WAY ANOVA Feb 6 25 Charlotte Wickham stat52.cwick.co.nz Roadmap DONE: Understand what a multiple regression model is. Know how to do inference on single and multiple parameters. Some extra
Stat 42/52 TWO WAY ANOVA Feb 6 25 Charlotte Wickham stat52.cwick.co.nz Roadmap DONE: Understand what a multiple regression model is. Know how to do inference on single and multiple parameters. Some extra
SCHOOL OF MATHEMATICS AND STATISTICS
 RESTRICTED OPEN BOOK EXAMINATION (Not to be removed from the examination hall) Data provided: Statistics Tables by H.R. Neave MAS5052 SCHOOL OF MATHEMATICS AND STATISTICS Basic Statistics Spring Semester
RESTRICTED OPEN BOOK EXAMINATION (Not to be removed from the examination hall) Data provided: Statistics Tables by H.R. Neave MAS5052 SCHOOL OF MATHEMATICS AND STATISTICS Basic Statistics Spring Semester
Generalized Linear Models in R
 Generalized Linear Models in R NO ORDER Kenneth K. Lopiano, Garvesh Raskutti, Dan Yang last modified 28 4 2013 1 Outline 1. Background and preliminaries 2. Data manipulation and exercises 3. Data structures
Generalized Linear Models in R NO ORDER Kenneth K. Lopiano, Garvesh Raskutti, Dan Yang last modified 28 4 2013 1 Outline 1. Background and preliminaries 2. Data manipulation and exercises 3. Data structures
Lab 3 A Quick Introduction to Multiple Linear Regression Psychology The Multiple Linear Regression Model
 Lab 3 A Quick Introduction to Multiple Linear Regression Psychology 310 Instructions.Work through the lab, saving the output as you go. You will be submitting your assignment as an R Markdown document.
Lab 3 A Quick Introduction to Multiple Linear Regression Psychology 310 Instructions.Work through the lab, saving the output as you go. You will be submitting your assignment as an R Markdown document.
BIOL 458 BIOMETRY Lab 9 - Correlation and Bivariate Regression
 BIOL 458 BIOMETRY Lab 9 - Correlation and Bivariate Regression Introduction to Correlation and Regression The procedures discussed in the previous ANOVA labs are most useful in cases where we are interested
BIOL 458 BIOMETRY Lab 9 - Correlation and Bivariate Regression Introduction to Correlation and Regression The procedures discussed in the previous ANOVA labs are most useful in cases where we are interested
Linear Regression. In this lecture we will study a particular type of regression model: the linear regression model
 1 Linear Regression 2 Linear Regression In this lecture we will study a particular type of regression model: the linear regression model We will first consider the case of the model with one predictor
1 Linear Regression 2 Linear Regression In this lecture we will study a particular type of regression model: the linear regression model We will first consider the case of the model with one predictor
Statistics - Lecture Three. Linear Models. Charlotte Wickham 1.
 Statistics - Lecture Three Charlotte Wickham wickham@stat.berkeley.edu http://www.stat.berkeley.edu/~wickham/ Linear Models 1. The Theory 2. Practical Use 3. How to do it in R 4. An example 5. Extensions
Statistics - Lecture Three Charlotte Wickham wickham@stat.berkeley.edu http://www.stat.berkeley.edu/~wickham/ Linear Models 1. The Theory 2. Practical Use 3. How to do it in R 4. An example 5. Extensions
22s:152 Applied Linear Regression. Take random samples from each of m populations.
 22s:152 Applied Linear Regression Chapter 8: ANOVA NOTE: We will meet in the lab on Monday October 10. One-way ANOVA Focuses on testing for differences among group means. Take random samples from each
22s:152 Applied Linear Regression Chapter 8: ANOVA NOTE: We will meet in the lab on Monday October 10. One-way ANOVA Focuses on testing for differences among group means. Take random samples from each
STK4900/ Lecture 3. Program
 STK4900/9900 - Lecture 3 Program 1. Multiple regression: Data structure and basic questions 2. The multiple linear regression model 3. Categorical predictors 4. Planned experiments and observational studies
STK4900/9900 - Lecture 3 Program 1. Multiple regression: Data structure and basic questions 2. The multiple linear regression model 3. Categorical predictors 4. Planned experiments and observational studies
Booklet of Code and Output for STAC32 Final Exam
 Booklet of Code and Output for STAC32 Final Exam December 7, 2017 Figure captions are below the Figures they refer to. LowCalorie LowFat LowCarbo Control 8 2 3 2 9 4 5 2 6 3 4-1 7 5 2 0 3 1 3 3 Figure
Booklet of Code and Output for STAC32 Final Exam December 7, 2017 Figure captions are below the Figures they refer to. LowCalorie LowFat LowCarbo Control 8 2 3 2 9 4 5 2 6 3 4-1 7 5 2 0 3 1 3 3 Figure
Logistic Regression - problem 6.14
 Logistic Regression - problem 6.14 Let x 1, x 2,, x m be given values of an input variable x and let Y 1,, Y m be independent binomial random variables whose distributions depend on the corresponding values
Logistic Regression - problem 6.14 Let x 1, x 2,, x m be given values of an input variable x and let Y 1,, Y m be independent binomial random variables whose distributions depend on the corresponding values
Chapter 8: Correlation & Regression
 Chapter 8: Correlation & Regression We can think of ANOVA and the two-sample t-test as applicable to situations where there is a response variable which is quantitative, and another variable that indicates
Chapter 8: Correlation & Regression We can think of ANOVA and the two-sample t-test as applicable to situations where there is a response variable which is quantitative, and another variable that indicates
22s:152 Applied Linear Regression. There are a couple commonly used models for a one-way ANOVA with m groups. Chapter 8: ANOVA
 22s:152 Applied Linear Regression Chapter 8: ANOVA NOTE: We will meet in the lab on Monday October 10. One-way ANOVA Focuses on testing for differences among group means. Take random samples from each
22s:152 Applied Linear Regression Chapter 8: ANOVA NOTE: We will meet in the lab on Monday October 10. One-way ANOVA Focuses on testing for differences among group means. Take random samples from each
Statistics Lab #6 Factorial ANOVA
 Statistics Lab #6 Factorial ANOVA PSYCH 710 Initialize R Initialize R by entering the following commands at the prompt. You must type the commands exactly as shown. options(contrasts=c("contr.sum","contr.poly")
Statistics Lab #6 Factorial ANOVA PSYCH 710 Initialize R Initialize R by entering the following commands at the prompt. You must type the commands exactly as shown. options(contrasts=c("contr.sum","contr.poly")
Ch 2: Simple Linear Regression
 Ch 2: Simple Linear Regression 1. Simple Linear Regression Model A simple regression model with a single regressor x is y = β 0 + β 1 x + ɛ, where we assume that the error ɛ is independent random component
Ch 2: Simple Linear Regression 1. Simple Linear Regression Model A simple regression model with a single regressor x is y = β 0 + β 1 x + ɛ, where we assume that the error ɛ is independent random component
1 Forecasting House Starts
 1396, Time Series, Week 5, Fall 2007 1 In this handout, we will see the application example on chapter 5. We use the same example as illustrated in the textbook and fit the data with several models of
1396, Time Series, Week 5, Fall 2007 1 In this handout, we will see the application example on chapter 5. We use the same example as illustrated in the textbook and fit the data with several models of
Linear Regression. Furthermore, it is simple.
 Linear Regression While linear regression has limited value in the classification problem, it is often very useful in predicting a numerical response, on a linear or ratio scale. Furthermore, it is simple.
Linear Regression While linear regression has limited value in the classification problem, it is often very useful in predicting a numerical response, on a linear or ratio scale. Furthermore, it is simple.
MODULE 6 LOGISTIC REGRESSION. Module Objectives:
 MODULE 6 LOGISTIC REGRESSION Module Objectives: 1. 147 6.1. LOGIT TRANSFORMATION MODULE 6. LOGISTIC REGRESSION Logistic regression models are used when a researcher is investigating the relationship between
MODULE 6 LOGISTIC REGRESSION Module Objectives: 1. 147 6.1. LOGIT TRANSFORMATION MODULE 6. LOGISTIC REGRESSION Logistic regression models are used when a researcher is investigating the relationship between
Estimated Simple Regression Equation
 Simple Linear Regression A simple linear regression model that describes the relationship between two variables x and y can be expressed by the following equation. The numbers α and β are called parameters,
Simple Linear Regression A simple linear regression model that describes the relationship between two variables x and y can be expressed by the following equation. The numbers α and β are called parameters,
MS&E 226: Small Data
 MS&E 226: Small Data Lecture 15: Examples of hypothesis tests (v5) Ramesh Johari ramesh.johari@stanford.edu 1 / 32 The recipe 2 / 32 The hypothesis testing recipe In this lecture we repeatedly apply the
MS&E 226: Small Data Lecture 15: Examples of hypothesis tests (v5) Ramesh Johari ramesh.johari@stanford.edu 1 / 32 The recipe 2 / 32 The hypothesis testing recipe In this lecture we repeatedly apply the
Chapter 16: Understanding Relationships Numerical Data
 Chapter 16: Understanding Relationships Numerical Data These notes reflect material from our text, Statistics, Learning from Data, First Edition, by Roxy Peck, published by CENGAGE Learning, 2015. Linear
Chapter 16: Understanding Relationships Numerical Data These notes reflect material from our text, Statistics, Learning from Data, First Edition, by Roxy Peck, published by CENGAGE Learning, 2015. Linear
Booklet of Code and Output for STAD29/STA 1007 Midterm Exam
 Booklet of Code and Output for STAD29/STA 1007 Midterm Exam List of Figures in this document by page: List of Figures 1 Packages................................ 2 2 Hospital infection risk data (some).................
Booklet of Code and Output for STAD29/STA 1007 Midterm Exam List of Figures in this document by page: List of Figures 1 Packages................................ 2 2 Hospital infection risk data (some).................
Multiple Regression Part I STAT315, 19-20/3/2014
 Multiple Regression Part I STAT315, 19-20/3/2014 Regression problem Predictors/independent variables/features Or: Error which can never be eliminated. Our task is to estimate the regression function f.
Multiple Regression Part I STAT315, 19-20/3/2014 Regression problem Predictors/independent variables/features Or: Error which can never be eliminated. Our task is to estimate the regression function f.
Statistics 203 Introduction to Regression Models and ANOVA Practice Exam
 Statistics 203 Introduction to Regression Models and ANOVA Practice Exam Prof. J. Taylor You may use your 4 single-sided pages of notes This exam is 7 pages long. There are 4 questions, first 3 worth 10
Statistics 203 Introduction to Regression Models and ANOVA Practice Exam Prof. J. Taylor You may use your 4 single-sided pages of notes This exam is 7 pages long. There are 4 questions, first 3 worth 10
Correlation Analysis
 Simple Regression Correlation Analysis Correlation analysis is used to measure strength of the association (linear relationship) between two variables Correlation is only concerned with strength of the
Simple Regression Correlation Analysis Correlation analysis is used to measure strength of the association (linear relationship) between two variables Correlation is only concerned with strength of the
Model Building Chap 5 p251
 Model Building Chap 5 p251 Models with one qualitative variable, 5.7 p277 Example 4 Colours : Blue, Green, Lemon Yellow and white Row Blue Green Lemon Insects trapped 1 0 0 1 45 2 0 0 1 59 3 0 0 1 48 4
Model Building Chap 5 p251 Models with one qualitative variable, 5.7 p277 Example 4 Colours : Blue, Green, Lemon Yellow and white Row Blue Green Lemon Insects trapped 1 0 0 1 45 2 0 0 1 59 3 0 0 1 48 4
Simple Linear Regression
 Simple Linear Regression MATH 282A Introduction to Computational Statistics University of California, San Diego Instructor: Ery Arias-Castro http://math.ucsd.edu/ eariasca/math282a.html MATH 282A University
Simple Linear Regression MATH 282A Introduction to Computational Statistics University of California, San Diego Instructor: Ery Arias-Castro http://math.ucsd.edu/ eariasca/math282a.html MATH 282A University
Lecture 3: Inference in SLR
 Lecture 3: Inference in SLR STAT 51 Spring 011 Background Reading KNNL:.1.6 3-1 Topic Overview This topic will cover: Review of hypothesis testing Inference about 1 Inference about 0 Confidence Intervals
Lecture 3: Inference in SLR STAT 51 Spring 011 Background Reading KNNL:.1.6 3-1 Topic Overview This topic will cover: Review of hypothesis testing Inference about 1 Inference about 0 Confidence Intervals
Linear Regression Models P8111
 Linear Regression Models P8111 Lecture 25 Jeff Goldsmith April 26, 2016 1 of 37 Today s Lecture Logistic regression / GLMs Model framework Interpretation Estimation 2 of 37 Linear regression Course started
Linear Regression Models P8111 Lecture 25 Jeff Goldsmith April 26, 2016 1 of 37 Today s Lecture Logistic regression / GLMs Model framework Interpretation Estimation 2 of 37 Linear regression Course started
Multivariate Statistics in Ecology and Quantitative Genetics Summary
 Multivariate Statistics in Ecology and Quantitative Genetics Summary Dirk Metzler & Martin Hutzenthaler http://evol.bio.lmu.de/_statgen 5. August 2011 Contents Linear Models Generalized Linear Models Mixed-effects
Multivariate Statistics in Ecology and Quantitative Genetics Summary Dirk Metzler & Martin Hutzenthaler http://evol.bio.lmu.de/_statgen 5. August 2011 Contents Linear Models Generalized Linear Models Mixed-effects
5. Linear Regression
 5. Linear Regression Outline.................................................................... 2 Simple linear regression 3 Linear model............................................................. 4
5. Linear Regression Outline.................................................................... 2 Simple linear regression 3 Linear model............................................................. 4
Regression and Models with Multiple Factors. Ch. 17, 18
 Regression and Models with Multiple Factors Ch. 17, 18 Mass 15 20 25 Scatter Plot 70 75 80 Snout-Vent Length Mass 15 20 25 Linear Regression 70 75 80 Snout-Vent Length Least-squares The method of least
Regression and Models with Multiple Factors Ch. 17, 18 Mass 15 20 25 Scatter Plot 70 75 80 Snout-Vent Length Mass 15 20 25 Linear Regression 70 75 80 Snout-Vent Length Least-squares The method of least
Log-linear Models for Contingency Tables
 Log-linear Models for Contingency Tables Statistics 149 Spring 2006 Copyright 2006 by Mark E. Irwin Log-linear Models for Two-way Contingency Tables Example: Business Administration Majors and Gender A
Log-linear Models for Contingency Tables Statistics 149 Spring 2006 Copyright 2006 by Mark E. Irwin Log-linear Models for Two-way Contingency Tables Example: Business Administration Majors and Gender A
Stat 401B Final Exam Fall 2016
 Stat 40B Final Exam Fall 0 I have neither given nor received unauthorized assistance on this exam. Name Signed Date Name Printed ATTENTION! Incorrect numerical answers unaccompanied by supporting reasoning
Stat 40B Final Exam Fall 0 I have neither given nor received unauthorized assistance on this exam. Name Signed Date Name Printed ATTENTION! Incorrect numerical answers unaccompanied by supporting reasoning
Using R formulae to test for main effects in the presence of higher-order interactions
 Using R formulae to test for main effects in the presence of higher-order interactions Roger Levy arxiv:1405.2094v2 [stat.me] 15 Jan 2018 January 16, 2018 Abstract Traditional analysis of variance (ANOVA)
Using R formulae to test for main effects in the presence of higher-order interactions Roger Levy arxiv:1405.2094v2 [stat.me] 15 Jan 2018 January 16, 2018 Abstract Traditional analysis of variance (ANOVA)
Stat 401B Final Exam Fall 2015
 Stat 401B Final Exam Fall 015 I have neither given nor received unauthorized assistance on this exam. Name Signed Date Name Printed ATTENTION! Incorrect numerical answers unaccompanied by supporting reasoning
Stat 401B Final Exam Fall 015 I have neither given nor received unauthorized assistance on this exam. Name Signed Date Name Printed ATTENTION! Incorrect numerical answers unaccompanied by supporting reasoning
Inference for the Regression Coefficient
 Inference for the Regression Coefficient Recall, b 0 and b 1 are the estimates of the slope β 1 and intercept β 0 of population regression line. We can shows that b 0 and b 1 are the unbiased estimates
Inference for the Regression Coefficient Recall, b 0 and b 1 are the estimates of the slope β 1 and intercept β 0 of population regression line. We can shows that b 0 and b 1 are the unbiased estimates
The Statistical Sleuth in R: Chapter 13
 The Statistical Sleuth in R: Chapter 13 Linda Loi Kate Aloisio Ruobing Zhang Nicholas J. Horton June 15, 2016 Contents 1 Introduction 1 2 Intertidal seaweed grazers 2 2.1 Data coding, summary statistics
The Statistical Sleuth in R: Chapter 13 Linda Loi Kate Aloisio Ruobing Zhang Nicholas J. Horton June 15, 2016 Contents 1 Introduction 1 2 Intertidal seaweed grazers 2 2.1 Data coding, summary statistics
Multiple Linear Regression (solutions to exercises)
") Chapter 6 1 Chapter 6 Multiple Linear Regression (solutions to exercises) Chapter 6 CONTENTS 2 Contents 6 Multiple Linear Regression (solutions to exercises) 1 6.1 Nitrate concentration..........................
Chapter 6 1 Chapter 6 Multiple Linear Regression (solutions to exercises) Chapter 6 CONTENTS 2 Contents 6 Multiple Linear Regression (solutions to exercises) 1 6.1 Nitrate concentration..........................
UNIVERSITY OF TORONTO SCARBOROUGH Department of Computer and Mathematical Sciences Midterm Test, October 2013
 UNIVERSITY OF TORONTO SCARBOROUGH Department of Computer and Mathematical Sciences Midterm Test, October 2013 STAC67H3 Regression Analysis Duration: One hour and fifty minutes Last Name: First Name: Student
UNIVERSITY OF TORONTO SCARBOROUGH Department of Computer and Mathematical Sciences Midterm Test, October 2013 STAC67H3 Regression Analysis Duration: One hour and fifty minutes Last Name: First Name: Student
Inference. ME104: Linear Regression Analysis Kenneth Benoit. August 15, August 15, 2012 Lecture 3 Multiple linear regression 1 1 / 58
 Inference ME104: Linear Regression Analysis Kenneth Benoit August 15, 2012 August 15, 2012 Lecture 3 Multiple linear regression 1 1 / 58 Stata output resvisited. reg votes1st spend_total incumb minister
Inference ME104: Linear Regression Analysis Kenneth Benoit August 15, 2012 August 15, 2012 Lecture 3 Multiple linear regression 1 1 / 58 Stata output resvisited. reg votes1st spend_total incumb minister
Transcript of Mick Crawley s R course 2010 Imperial College London, Silwood Park
 Transcript of Mick Crawley s R course 2010 Imperial College London, Silwood Park Emanuel G Heitlinger Disclaimer: The following document is a private transcript of Mick Crawley s R-course. I am a participant
Transcript of Mick Crawley s R course 2010 Imperial College London, Silwood Park Emanuel G Heitlinger Disclaimer: The following document is a private transcript of Mick Crawley s R-course. I am a participant
Inferences on Linear Combinations of Coefficients
 Inferences on Linear Combinations of Coefficients Note on required packages: The following code required the package multcomp to test hypotheses on linear combinations of regression coefficients. If you
Inferences on Linear Combinations of Coefficients Note on required packages: The following code required the package multcomp to test hypotheses on linear combinations of regression coefficients. If you
Multiple Regression and Regression Model Adequacy
 Multiple Regression and Regression Model Adequacy Joseph J. Luczkovich, PhD February 14, 2014 Introduction Regression is a technique to mathematically model the linear association between two or more variables,
Multiple Regression and Regression Model Adequacy Joseph J. Luczkovich, PhD February 14, 2014 Introduction Regression is a technique to mathematically model the linear association between two or more variables,
Checking the Poisson assumption in the Poisson generalized linear model
 Checking the Poisson assumption in the Poisson generalized linear model The Poisson regression model is a generalized linear model (glm) satisfying the following assumptions: The responses y i are independent
Checking the Poisson assumption in the Poisson generalized linear model The Poisson regression model is a generalized linear model (glm) satisfying the following assumptions: The responses y i are independent
Stat 401B Exam 2 Fall 2015
 Stat 401B Exam Fall 015 I have neither given nor received unauthorized assistance on this exam. Name Signed Date Name Printed ATTENTION! Incorrect numerical answers unaccompanied by supporting reasoning
Stat 401B Exam Fall 015 I have neither given nor received unauthorized assistance on this exam. Name Signed Date Name Printed ATTENTION! Incorrect numerical answers unaccompanied by supporting reasoning