Artificial Intelligence for HVAC Systems
|
|
|
- Angela York
- 5 years ago
- Views:
Transcription
1 Artificial Intelligence for HVAC Systems V. Ziebart, ACSS IAMP ZHAW
2 Motivation More than 80% of the energy consumed in Swiss households is used for room heating & cooling and domestic hot water.* The increasing combined use of various energy conversion and storage technologies (PT, solar thermal collectors, heat pumps, combustion, batteries, hot water storage, ice storage systems) requires intelligent and optimal control systems. Reinforcement Learning (RL) showed promising performance in different fields (AlphaZero, computer games). RL is a data-driven approach. Can RL be used as control method for HVAC**-Systems? (optimality, learning behavior, robustness, * Energieverbrauch in der Schweiz und weltweit, EnergieSchweiz, Bundesamt für Energie BFE Dienst Aus-und Weiterbildung, Juli 2015 ** HVAC: heating, ventilation, air conditioning



3 Model of Building and Heating System Weather data of 11 Swiss cities T amb T forecast Occupation pattern T air T ch T floor COP of heat pump PID 1 T PID 2 cellar T s1 heat pump T s2 Enery price T soil night rate 0.5 date rate 1
4 Reinforcement Learning Control policy π qsa (, ) = value function : qπ(, s a) = Επ GtSt = s, At = a k return : Gt = γ R k = 0 discount rate : γ [0,1] t+ k+ 1 Schematic from: Richard S. Sutton and Andrew G. Barto, An introduction to reinforcement learning, 2018
5 Q-Learning and SARSA Q-learning: ( R max ( ) t + γ q t 1 a) qst, qs (, a) qs (, a) + α s +, ( a ) SARSA: new estimate of return G t t t t t a learning rate ( R+ γ qs (, a ) ) qs (, a) qs (, a) + α + + qs (, a) t t t t t t 1 t 1 t t difference of «large» numbers! These interacting, interdependent, interative jobs must be done: 1. learn q for actions performed in state visited 2. approximate a generalized q-function on state and action space (SxA) (typically with gradient descent) 3. improve control performance by e.g. (ε-)greedy policy potentially unstable
6 Improvement of Stability Ad 1: More efficient learning of q through n-step SARSA n 1 k n γ k 0 t+ k+ γ = t+ n t+ n Gtn, = R qs (, a ) truncated sum of n rewards instead of Gt,1 = Rt + γ qs ( t+ 1, at+ 1). Average fraction return: n 1 k = 0 k = 0 k γ R k γ R n 1 γ 1 γ = = 1 γ 1 1 γ n Ad 2: Least-Squares fit to {s t,a t,g t,n } with polynomials and trigonometric functions to find q(s,a) on SxA instead of iterative gradient descent methods.
7 State, Action, Reward State variables for RLC (continous and discrete) 6 temperatures, R 6 (T amb, T air, T floor, T storage1, T storage2, T forecast ) time, real interval [0,24[ room occupancy, boolean Action variables (discrete, 12 combinations) heat pump off/loading storage 1 or 2, {0,1,2} PID floor heating on/off, boolean PID convection heater on/off, boolean Reward ( 0): energy costs (negative, night and day rate) temperature deviation from setpoint, (negative, proportional to T, only if house is occupied)
8 Approximation of State-Action Value Function q(s,a) Partitioning of state-action space in continous (c) and discrete (d) subspaces: S x A = (S c x S d ) x (A c x A d ) = S c x A c x S d x A d continous discrete For each set of discrete variables in S d x A d (24 configurations) q(s,a) is approximated in the continous subspace S c x A c by a linear combination of polynomials (temperatures) and trigonometric functions (time): 6 nki (,, j) k kjl i l jl, i= 1 q ( s, a) = c T trig ( t) k = 1,...,24 rewritten as flattened vector product q( sa, ) = c p( T,..., T, t) = c p k= 1,...,24 k kj j 1 6 k j typically: j = 252 k j = coefficients c kj
9 Analytical Solution c older experience is discounted by γ Q = arg min R + q s, a, k = 1,...,24 t n 1 t i j n k γq γ sik (, ) + j γ ( sik (, ) + n sik (, ) + n) ckp sik (, ) i= 1 j= 0 2 s(i,k) is the index when (s d,a d ) i =(s d,a d ) k the i-th time rearranging yields: { (, ), (, ), } ( i) ( i 1) k = γ Q k + sik r sik l Q Q p p n 1 ( i) ( i 1) j n k = γq k 2 sik (, ) γ Rsik (, ) + j+ γ q ssik (, ) n, a + sik (, ) + n j= 0 b b p ( ε ) 1 c = 0.5 Q + I b k k k k rl for nummerical reasons ( )
10 Decision Making, Reward Normalization probability of choosing a i : π ( ai s) = n e j= 1 (, ) qsa e i (, j ) qsa τ τ ( ai s) ( aj s) ( qsai s) τ : π = π τ 0 : π arg max (, ) = 1 qsa (, ) 0! i normalization of reward per year (plots only!) by difference of average outside temperature and room set point temperature R R with T T T T T year year, norm = = 2 sp amb
11 Hardware & Software 2 Servers with 2 CPUs Intel Xeon Platinum 8164 each Each CPU with 26 cores 768 GB RAM Code written in Mathematica Computation time for 1 year simulation: 1min
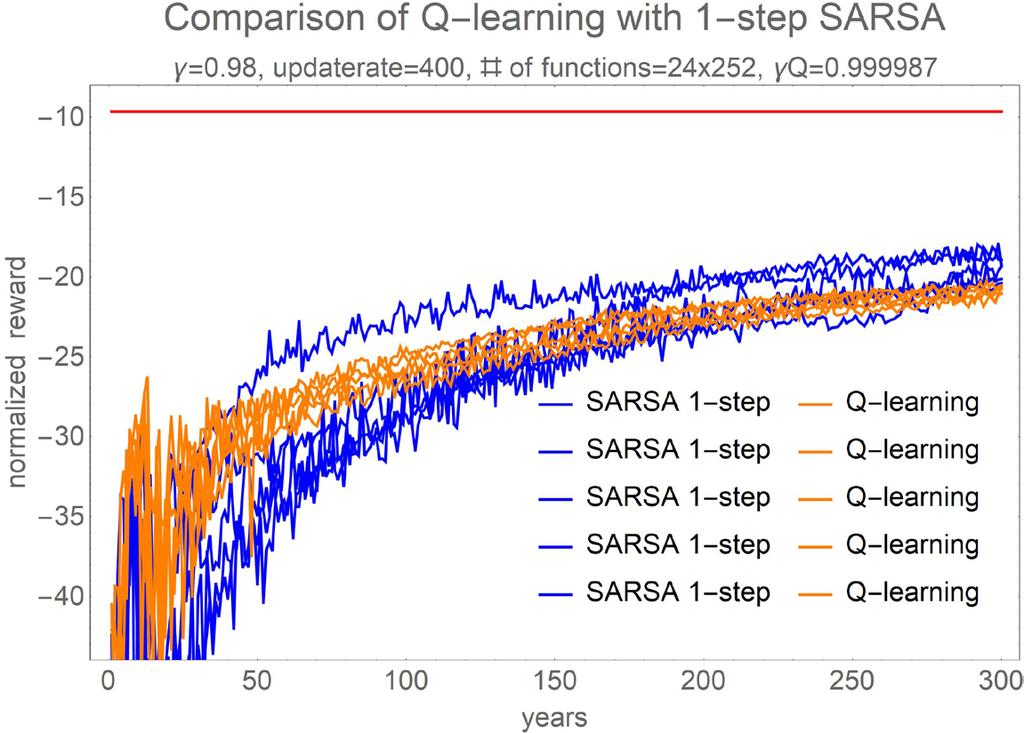
12 SARSA vs Q-Learning
13 Effect of n in n-step SARSA
14 Effect of n in n-step SARSA n=1 out of plot range

15 Influence of Discount Factor γ Actual time 5:00. One more heating hour before 20:00 is needed. What hour seems to be the best choice? (If γ>0.952: heating at 5:00, otherwise heating at 19:00) especially too low γ s lead to suboptimal decisions and unrealistic q-values
16 n-step SARSA without Discount The discount of future rewards disturbs the optimal scheduling of actions with fixed and known costs. Alternative approach: n-step SARSA without discount n 1 k n γ k 0 t+ k+ γ = t+ n t+ n Gtn, = R qs (, a ) The time horizon is defined by n instead of γ!

17 n-step SARSA without Discount
18 Performance of n-step SARSA without Discount optimal range

19 Parallel «Supporting» Agents, Motivation Could larger scatter be exploited by helping worse agents become better and then by chance even be better than best agent?
20 Parallel «Supporting» Agents, Structure occupation & weather data R Agent 1 (p hyper,1, ε supp,1 ) Agent 2 (p hyper,2, ε supp,2 ) Agent 3 (p hyper,3 ε supp,3 ) Agent n (p hyper,n ε supp,n ), q best _ agent coeff, best _ agent R1, qcoeff,1 R R 2, qcoeff,2 3, qcoeff,3 control & performance parameter ε R ( ) ( # / min 1 ) i year τ supp c e,1 if # year even R R 0 if # year odd supp supp, i = i best _ agent ε > ε ε < ε supp supp : decision based on own parameters : decision based on best agents parameters needed to evalute performance
21 Parallel «Supporting» Agents, Results all agents show better performance than best agent without support
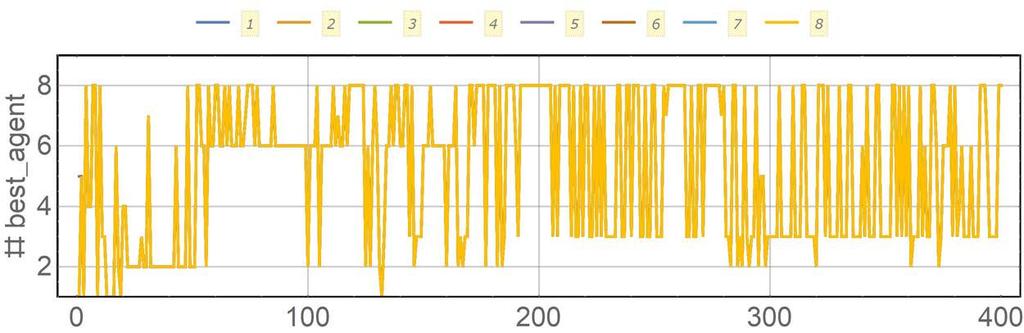
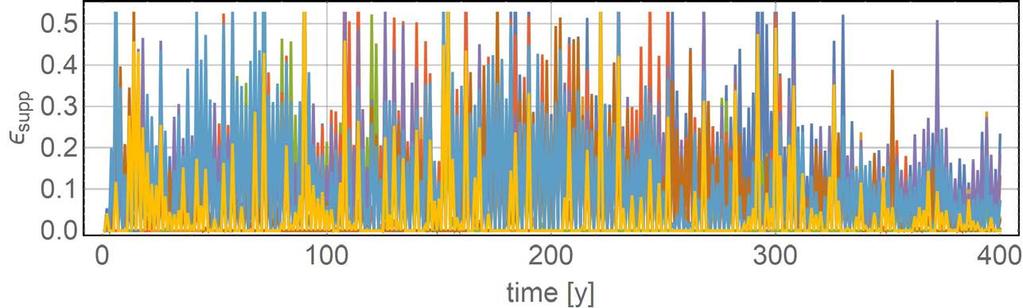
22 Parallel «Supporting» Agents, Results

23 RL Control Example (1)

")
24 RL Control Example (2)
 agent heats at cheaper")
25 RL Control Example (3) -0.1 *(energy rate) agent heats at cheaper night rate only
26 Simulated Reinforcement Learning Schematic: Peter Bolt, ACSS IMAP ZHAW
27 RBC with Parameters Optimized by RL Some simple fixed rules Setpoints for water storage heating 1 & 2 are parametrized, k 1 and k 2 learned Tamb + Tforecast Tsp, heating st1 = Tsp, room + Tsp, room k1 2 T + T T T T k 2 amb forecast sp, heating st 2 = sp, room + sp, room 2 Reward (energy consumption & set point violation) is normalized and thus almost independent of outside temperature: R = R with T = T T T T norm 2 sp amb
28 RL with Parametrized RBC acceptable performance in less than 1 year!
29 Summary RLC for a heating system converges to nearly optimal trajectories needs order of 100 simulated years for convergence ( simulated RL) Improvements to RL least-squares fit to get q(s,a) in one step n-step SARSA truncated reward sum without discount parallel, mutually supporting agents Alternative approach with parametrized RBC much shorter learning time due to less coefficients good performance
Reinforcement Learning. Machine Learning, Fall 2010
 Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
Q-Learning in Continuous State Action Spaces
 Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
Christopher Watkins and Peter Dayan. Noga Zaslavsky. The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015
 November 1, 2015") Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
Reinforcement Learning. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
Machine Learning I Reinforcement Learning
 Machine Learning I Reinforcement Learning Thomas Rückstieß Technische Universität München December 17/18, 2009 Literature Book: Reinforcement Learning: An Introduction Sutton & Barto (free online version:
Machine Learning I Reinforcement Learning Thomas Rückstieß Technische Universität München December 17/18, 2009 Literature Book: Reinforcement Learning: An Introduction Sutton & Barto (free online version:
Reinforcement Learning. George Konidaris
 Reinforcement Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom
Reinforcement Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom
Q-learning. Tambet Matiisen
 Q-learning Tambet Matiisen (based on chapter 11.3 of online book Artificial Intelligence, foundations of computational agents by David Poole and Alan Mackworth) Stochastic gradient descent Experience
Q-learning Tambet Matiisen (based on chapter 11.3 of online book Artificial Intelligence, foundations of computational agents by David Poole and Alan Mackworth) Stochastic gradient descent Experience
Review: TD-Learning. TD (SARSA) Learning for Q-values. Bellman Equations for Q-values. P (s, a, s )[R(s, a, s )+ Q (s, (s ))]
![Review: TD-Learning. TD (SARSA) Learning for Q-values. Bellman Equations for Q-values. P (s, a, s )[R(s, a, s )+ Q (s, (s ))]](/thumbs/94/119187228.jpg "Review: TD-Learning. TD (SARSA) Learning for Q-values. Bellman Equations for Q-values. P (s, a, s )[R(s, a, s )+ Q (s, (s ))]") Review: TD-Learning function TD-Learning(mdp) returns a policy Class #: Reinforcement Learning, II 8s S, U(s) =0 set start-state s s 0 choose action a, using -greedy policy based on U(s) U(s) U(s)+ [r
Review: TD-Learning function TD-Learning(mdp) returns a policy Class #: Reinforcement Learning, II 8s S, U(s) =0 set start-state s s 0 choose action a, using -greedy policy based on U(s) U(s) U(s)+ [r
Temporal Difference. Learning KENNETH TRAN. Principal Research Engineer, MSR AI
 Temporal Difference Learning KENNETH TRAN Principal Research Engineer, MSR AI Temporal Difference Learning Policy Evaluation Intro to model-free learning Monte Carlo Learning Temporal Difference Learning
Temporal Difference Learning KENNETH TRAN Principal Research Engineer, MSR AI Temporal Difference Learning Policy Evaluation Intro to model-free learning Monte Carlo Learning Temporal Difference Learning
Reinforcement Learning Part 2
 Reinforcement Learning Part 2 Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ From previous tutorial Reinforcement Learning Exploration No supervision Agent-Reward-Environment
Reinforcement Learning Part 2 Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ From previous tutorial Reinforcement Learning Exploration No supervision Agent-Reward-Environment
Machine Learning. Reinforcement learning. Hamid Beigy. Sharif University of Technology. Fall 1396
 Machine Learning Reinforcement learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1396 1 / 32 Table of contents 1 Introduction
Machine Learning Reinforcement learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1396 1 / 32 Table of contents 1 Introduction
MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti
 AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti") 1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
Prof. Dr. Ann Nowé. Artificial Intelligence Lab ai.vub.ac.be
 REINFORCEMENT LEARNING AN INTRODUCTION Prof. Dr. Ann Nowé Artificial Intelligence Lab ai.vub.ac.be REINFORCEMENT LEARNING WHAT IS IT? What is it? Learning from interaction Learning about, from, and while
REINFORCEMENT LEARNING AN INTRODUCTION Prof. Dr. Ann Nowé Artificial Intelligence Lab ai.vub.ac.be REINFORCEMENT LEARNING WHAT IS IT? What is it? Learning from interaction Learning about, from, and while
Reinforcement Learning
 Reinforcement Learning Ron Parr CompSci 7 Department of Computer Science Duke University With thanks to Kris Hauser for some content RL Highlights Everybody likes to learn from experience Use ML techniques
Reinforcement Learning Ron Parr CompSci 7 Department of Computer Science Duke University With thanks to Kris Hauser for some content RL Highlights Everybody likes to learn from experience Use ML techniques
Reinforcement Learning. Yishay Mansour Tel-Aviv University
 Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Reinforcement Learning, Neural Networks and PI Control Applied to a Heating Coil
 Reinforcement Learning, Neural Networks and PI Control Applied to a Heating Coil Charles W. Anderson 1, Douglas C. Hittle 2, Alon D. Katz 2, and R. Matt Kretchmar 1 1 Department of Computer Science Colorado
Reinforcement Learning, Neural Networks and PI Control Applied to a Heating Coil Charles W. Anderson 1, Douglas C. Hittle 2, Alon D. Katz 2, and R. Matt Kretchmar 1 1 Department of Computer Science Colorado
Off-Policy Actor-Critic
 Off-Policy Actor-Critic Ludovic Trottier Laval University July 25 2012 Ludovic Trottier (DAMAS Laboratory) Off-Policy Actor-Critic July 25 2012 1 / 34 Table of Contents 1 Reinforcement Learning Theory
Off-Policy Actor-Critic Ludovic Trottier Laval University July 25 2012 Ludovic Trottier (DAMAS Laboratory) Off-Policy Actor-Critic July 25 2012 1 / 34 Table of Contents 1 Reinforcement Learning Theory
Reinforcement Learning. Summer 2017 Defining MDPs, Planning
 Reinforcement Learning Summer 2017 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
Reinforcement Learning Summer 2017 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
Reinforcement Learning with Function Approximation. Joseph Christian G. Noel
 Reinforcement Learning with Function Approximation Joseph Christian G. Noel November 2011 Abstract Reinforcement learning (RL) is a key problem in the field of Artificial Intelligence. The main goal is
Reinforcement Learning with Function Approximation Joseph Christian G. Noel November 2011 Abstract Reinforcement learning (RL) is a key problem in the field of Artificial Intelligence. The main goal is
Reinforcement Learning. Spring 2018 Defining MDPs, Planning
 Reinforcement Learning Spring 2018 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
Reinforcement Learning Spring 2018 Defining MDPs, Planning understandability 0 Slide 10 time You are here Markov Process Where you will go depends only on where you are Markov Process: Information state
Reinforcement learning an introduction
 Reinforcement learning an introduction Prof. Dr. Ann Nowé Computational Modeling Group AIlab ai.vub.ac.be November 2013 Reinforcement Learning What is it? Learning from interaction Learning about, from,
Reinforcement learning an introduction Prof. Dr. Ann Nowé Computational Modeling Group AIlab ai.vub.ac.be November 2013 Reinforcement Learning What is it? Learning from interaction Learning about, from,
Temporal difference learning
 Temporal difference learning AI & Agents for IET Lecturer: S Luz http://www.scss.tcd.ie/~luzs/t/cs7032/ February 4, 2014 Recall background & assumptions Environment is a finite MDP (i.e. A and S are finite).
Temporal difference learning AI & Agents for IET Lecturer: S Luz http://www.scss.tcd.ie/~luzs/t/cs7032/ February 4, 2014 Recall background & assumptions Environment is a finite MDP (i.e. A and S are finite).
Basics of reinforcement learning
 Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
Basics of reinforcement learning Lucian Buşoniu TMLSS, 20 July 2018 Main idea of reinforcement learning (RL) Learn a sequential decision policy to optimize the cumulative performance of an unknown system
Reinforcement Learning II. George Konidaris
 Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2017 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2017 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Reinforcement Learning
 Reinforcement Learning Temporal Difference Learning Temporal difference learning, TD prediction, Q-learning, elibigility traces. (many slides from Marc Toussaint) Vien Ngo MLR, University of Stuttgart
Reinforcement Learning Temporal Difference Learning Temporal difference learning, TD prediction, Q-learning, elibigility traces. (many slides from Marc Toussaint) Vien Ngo MLR, University of Stuttgart
CS230: Lecture 9 Deep Reinforcement Learning
 CS230: Lecture 9 Deep Reinforcement Learning Kian Katanforoosh Menti code: 21 90 15 Today s outline I. Motivation II. Recycling is good: an introduction to RL III. Deep Q-Learning IV. Application of Deep
CS230: Lecture 9 Deep Reinforcement Learning Kian Katanforoosh Menti code: 21 90 15 Today s outline I. Motivation II. Recycling is good: an introduction to RL III. Deep Q-Learning IV. Application of Deep
Reinforcement Learning II. George Konidaris
 Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2018 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2018 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
MDP Preliminaries. Nan Jiang. February 10, 2019
 MDP Preliminaries Nan Jiang February 10, 2019 1 Markov Decision Processes In reinforcement learning, the interactions between the agent and the environment are often described by a Markov Decision Process
MDP Preliminaries Nan Jiang February 10, 2019 1 Markov Decision Processes In reinforcement learning, the interactions between the agent and the environment are often described by a Markov Decision Process
Reinforcement Learning
 Reinforcement Learning Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ Task Grasp the green cup. Output: Sequence of controller actions Setup from Lenz et. al.
Reinforcement Learning Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ Task Grasp the green cup. Output: Sequence of controller actions Setup from Lenz et. al.
Lecture 3: The Reinforcement Learning Problem
 Lecture 3: The Reinforcement Learning Problem Objectives of this lecture: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Lecture 3: The Reinforcement Learning Problem Objectives of this lecture: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm
 Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Balancing and Control of a Freely-Swinging Pendulum Using a Model-Free Reinforcement Learning Algorithm Michail G. Lagoudakis Department of Computer Science Duke University Durham, NC 2778 mgl@cs.duke.edu
Reinforcement Learning Active Learning
 Reinforcement Learning Active Learning Alan Fern * Based in part on slides by Daniel Weld 1 Active Reinforcement Learning So far, we ve assumed agent has a policy We just learned how good it is Now, suppose
Reinforcement Learning Active Learning Alan Fern * Based in part on slides by Daniel Weld 1 Active Reinforcement Learning So far, we ve assumed agent has a policy We just learned how good it is Now, suppose
Chapter 7: Eligibility Traces. R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1
 Chapter 7: Eligibility Traces R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1 Midterm Mean = 77.33 Median = 82 R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction
Chapter 7: Eligibility Traces R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1 Midterm Mean = 77.33 Median = 82 R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction
6 Reinforcement Learning
 6 Reinforcement Learning As discussed above, a basic form of supervised learning is function approximation, relating input vectors to output vectors, or, more generally, finding density functions p(y,
6 Reinforcement Learning As discussed above, a basic form of supervised learning is function approximation, relating input vectors to output vectors, or, more generally, finding density functions p(y,
REINFORCEMENT LEARNING
 REINFORCEMENT LEARNING Larry Page: Where s Google going next? DeepMind's DQN playing Breakout Contents Introduction to Reinforcement Learning Deep Q-Learning INTRODUCTION TO REINFORCEMENT LEARNING Contents
REINFORCEMENT LEARNING Larry Page: Where s Google going next? DeepMind's DQN playing Breakout Contents Introduction to Reinforcement Learning Deep Q-Learning INTRODUCTION TO REINFORCEMENT LEARNING Contents
Reinforcement learning
 Reinforcement learning Based on [Kaelbling et al., 1996, Bertsekas, 2000] Bert Kappen Reinforcement learning Reinforcement learning is the problem faced by an agent that must learn behavior through trial-and-error
Reinforcement learning Based on [Kaelbling et al., 1996, Bertsekas, 2000] Bert Kappen Reinforcement learning Reinforcement learning is the problem faced by an agent that must learn behavior through trial-and-error
Notes on Reinforcement Learning
 1 Introduction Notes on Reinforcement Learning Paulo Eduardo Rauber 2014 Reinforcement learning is the study of agents that act in an environment with the goal of maximizing cumulative reward signals.
1 Introduction Notes on Reinforcement Learning Paulo Eduardo Rauber 2014 Reinforcement learning is the study of agents that act in an environment with the goal of maximizing cumulative reward signals.
Introduction to Reinforcement Learning. CMPT 882 Mar. 18
 Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Chapter 3: The Reinforcement Learning Problem
 Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Hidden Markov Models (HMM) and Support Vector Machine (SVM)
 and Support Vector Machine (SVM)") Hidden Markov Models (HMM) and Support Vector Machine (SVM) Professor Joongheon Kim School of Computer Science and Engineering, Chung-Ang University, Seoul, Republic of Korea 1 Hidden Markov Models (HMM)
Hidden Markov Models (HMM) and Support Vector Machine (SVM) Professor Joongheon Kim School of Computer Science and Engineering, Chung-Ang University, Seoul, Republic of Korea 1 Hidden Markov Models (HMM)
CS599 Lecture 1 Introduction To RL
 CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming
CS599 Lecture 1 Introduction To RL Reinforcement Learning Introduction Learning from rewards Policies Value Functions Rewards Models of the Environment Exploitation vs. Exploration Dynamic Programming
Decision Theory: Q-Learning
 Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
Exponential Moving Average Based Multiagent Reinforcement Learning Algorithms
 Artificial Intelligence Review manuscript No. (will be inserted by the editor) Exponential Moving Average Based Multiagent Reinforcement Learning Algorithms Mostafa D. Awheda Howard M. Schwartz Received:
Artificial Intelligence Review manuscript No. (will be inserted by the editor) Exponential Moving Average Based Multiagent Reinforcement Learning Algorithms Mostafa D. Awheda Howard M. Schwartz Received:
I D I A P. Online Policy Adaptation for Ensemble Classifiers R E S E A R C H R E P O R T. Samy Bengio b. Christos Dimitrakakis a IDIAP RR 03-69
 R E S E A R C H R E P O R T Online Policy Adaptation for Ensemble Classifiers Christos Dimitrakakis a IDIAP RR 03-69 Samy Bengio b I D I A P December 2003 D a l l e M o l l e I n s t i t u t e for Perceptual
R E S E A R C H R E P O R T Online Policy Adaptation for Ensemble Classifiers Christos Dimitrakakis a IDIAP RR 03-69 Samy Bengio b I D I A P December 2003 D a l l e M o l l e I n s t i t u t e for Perceptual
Reinforcement Learning II
 Reinforcement Learning II Andrea Bonarini Artificial Intelligence and Robotics Lab Department of Electronics and Information Politecnico di Milano E-mail: bonarini@elet.polimi.it URL:http://www.dei.polimi.it/people/bonarini
Reinforcement Learning II Andrea Bonarini Artificial Intelligence and Robotics Lab Department of Electronics and Information Politecnico di Milano E-mail: bonarini@elet.polimi.it URL:http://www.dei.polimi.it/people/bonarini
CS599 Lecture 2 Function Approximation in RL
 CS599 Lecture 2 Function Approximation in RL Look at how experience with a limited part of the state set be used to produce good behavior over a much larger part. Overview of function approximation (FA)
CS599 Lecture 2 Function Approximation in RL Look at how experience with a limited part of the state set be used to produce good behavior over a much larger part. Overview of function approximation (FA)
(Deep) Reinforcement Learning
 Reinforcement Learning") Martin Matyášek Artificial Intelligence Center Czech Technical University in Prague October 27, 2016 Martin Matyášek VPD, 2016 1 / 17 Reinforcement Learning in a picture R. S. Sutton and A. G. Barto 2015
Martin Matyášek Artificial Intelligence Center Czech Technical University in Prague October 27, 2016 Martin Matyášek VPD, 2016 1 / 17 Reinforcement Learning in a picture R. S. Sutton and A. G. Barto 2015
Reinforcement Learning
 Reinforcement Learning March May, 2013 Schedule Update Introduction 03/13/2015 (10:15-12:15) Sala conferenze MDPs 03/18/2015 (10:15-12:15) Sala conferenze Solving MDPs 03/20/2015 (10:15-12:15) Aula Alpha
Reinforcement Learning March May, 2013 Schedule Update Introduction 03/13/2015 (10:15-12:15) Sala conferenze MDPs 03/18/2015 (10:15-12:15) Sala conferenze Solving MDPs 03/20/2015 (10:15-12:15) Aula Alpha
An Adaptive Clustering Method for Model-free Reinforcement Learning
 An Adaptive Clustering Method for Model-free Reinforcement Learning Andreas Matt and Georg Regensburger Institute of Mathematics University of Innsbruck, Austria {andreas.matt, georg.regensburger}@uibk.ac.at
An Adaptive Clustering Method for Model-free Reinforcement Learning Andreas Matt and Georg Regensburger Institute of Mathematics University of Innsbruck, Austria {andreas.matt, georg.regensburger}@uibk.ac.at
Internet Monetization
 Internet Monetization March May, 2013 Discrete time Finite A decision process (MDP) is reward process with decisions. It models an environment in which all states are and time is divided into stages. Definition
Internet Monetization March May, 2013 Discrete time Finite A decision process (MDP) is reward process with decisions. It models an environment in which all states are and time is divided into stages. Definition
Markov decision processes
 CS 2740 Knowledge representation Lecture 24 Markov decision processes Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Administrative announcements Final exam: Monday, December 8, 2008 In-class Only
CS 2740 Knowledge representation Lecture 24 Markov decision processes Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Administrative announcements Final exam: Monday, December 8, 2008 In-class Only
Approximation Methods in Reinforcement Learning
 2018 CS420, Machine Learning, Lecture 12 Approximation Methods in Reinforcement Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/cs420/index.html Reinforcement
2018 CS420, Machine Learning, Lecture 12 Approximation Methods in Reinforcement Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/cs420/index.html Reinforcement
ARTIFICIAL INTELLIGENCE. Reinforcement learning
 INFOB2KI 2018-2019 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Reinforcement learning Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2018-2019 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Reinforcement learning Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
Today s s Lecture. Applicability of Neural Networks. Back-propagation. Review of Neural Networks. Lecture 20: Learning -4. Markov-Decision Processes
 Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
Learning Control for Air Hockey Striking using Deep Reinforcement Learning
 Learning Control for Air Hockey Striking using Deep Reinforcement Learning Ayal Taitler, Nahum Shimkin Faculty of Electrical Engineering Technion - Israel Institute of Technology May 8, 2017 A. Taitler,
Learning Control for Air Hockey Striking using Deep Reinforcement Learning Ayal Taitler, Nahum Shimkin Faculty of Electrical Engineering Technion - Israel Institute of Technology May 8, 2017 A. Taitler,
Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan
 COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan Some slides borrowed from Peter Bodik and David Silver Course progress Learning
COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan Some slides borrowed from Peter Bodik and David Silver Course progress Learning
Reinforcement Learning
 Reinforcement Learning 1 Reinforcement Learning Mainly based on Reinforcement Learning An Introduction by Richard Sutton and Andrew Barto Slides are mainly based on the course material provided by the
Reinforcement Learning 1 Reinforcement Learning Mainly based on Reinforcement Learning An Introduction by Richard Sutton and Andrew Barto Slides are mainly based on the course material provided by the
Lecture 3: Markov Decision Processes
 Lecture 3: Markov Decision Processes Joseph Modayil 1 Markov Processes 2 Markov Reward Processes 3 Markov Decision Processes 4 Extensions to MDPs Markov Processes Introduction Introduction to MDPs Markov
Lecture 3: Markov Decision Processes Joseph Modayil 1 Markov Processes 2 Markov Reward Processes 3 Markov Decision Processes 4 Extensions to MDPs Markov Processes Introduction Introduction to MDPs Markov
Human-level control through deep reinforcement. Liia Butler
 Humanlevel control through deep reinforcement Liia Butler But first... A quote "The question of whether machines can think... is about as relevant as the question of whether submarines can swim" Edsger
Humanlevel control through deep reinforcement Liia Butler But first... A quote "The question of whether machines can think... is about as relevant as the question of whether submarines can swim" Edsger
Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation
 Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation CS234: RL Emma Brunskill Winter 2018 Material builds on structure from David SIlver s Lecture 4: Model-Free
Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation CS234: RL Emma Brunskill Winter 2018 Material builds on structure from David SIlver s Lecture 4: Model-Free
Course 16:198:520: Introduction To Artificial Intelligence Lecture 13. Decision Making. Abdeslam Boularias. Wednesday, December 7, 2016
 Course 16:198:520: Introduction To Artificial Intelligence Lecture 13 Decision Making Abdeslam Boularias Wednesday, December 7, 2016 1 / 45 Overview We consider probabilistic temporal models where the
Course 16:198:520: Introduction To Artificial Intelligence Lecture 13 Decision Making Abdeslam Boularias Wednesday, December 7, 2016 1 / 45 Overview We consider probabilistic temporal models where the
CMU Lecture 11: Markov Decision Processes II. Teacher: Gianni A. Di Caro
 CMU 15-781 Lecture 11: Markov Decision Processes II Teacher: Gianni A. Di Caro RECAP: DEFINING MDPS Markov decision processes: o Set of states S o Start state s 0 o Set of actions A o Transitions P(s s,a)
CMU 15-781 Lecture 11: Markov Decision Processes II Teacher: Gianni A. Di Caro RECAP: DEFINING MDPS Markov decision processes: o Set of states S o Start state s 0 o Set of actions A o Transitions P(s s,a)
CS788 Dialogue Management Systems Lecture #2: Markov Decision Processes
 CS788 Dialogue Management Systems Lecture #2: Markov Decision Processes Kee-Eung Kim KAIST EECS Department Computer Science Division Markov Decision Processes (MDPs) A popular model for sequential decision
CS788 Dialogue Management Systems Lecture #2: Markov Decision Processes Kee-Eung Kim KAIST EECS Department Computer Science Division Markov Decision Processes (MDPs) A popular model for sequential decision
Markov Decision Processes and Solving Finite Problems. February 8, 2017
 Markov Decision Processes and Solving Finite Problems February 8, 2017 Overview of Upcoming Lectures Feb 8: Markov decision processes, value iteration, policy iteration Feb 13: Policy gradients Feb 15:
Markov Decision Processes and Solving Finite Problems February 8, 2017 Overview of Upcoming Lectures Feb 8: Markov decision processes, value iteration, policy iteration Feb 13: Policy gradients Feb 15:
Reinforcement Learning: the basics
 Reinforcement Learning: the basics Olivier Sigaud Université Pierre et Marie Curie, PARIS 6 http://people.isir.upmc.fr/sigaud August 6, 2012 1 / 46 Introduction Action selection/planning Learning by trial-and-error
Reinforcement Learning: the basics Olivier Sigaud Université Pierre et Marie Curie, PARIS 6 http://people.isir.upmc.fr/sigaud August 6, 2012 1 / 46 Introduction Action selection/planning Learning by trial-and-error
Dual Temporal Difference Learning
 Dual Temporal Difference Learning Min Yang Dept. of Computing Science University of Alberta Edmonton, Alberta Canada T6G 2E8 Yuxi Li Dept. of Computing Science University of Alberta Edmonton, Alberta Canada
Dual Temporal Difference Learning Min Yang Dept. of Computing Science University of Alberta Edmonton, Alberta Canada T6G 2E8 Yuxi Li Dept. of Computing Science University of Alberta Edmonton, Alberta Canada
Temporal Difference Learning & Policy Iteration
 Temporal Difference Learning & Policy Iteration Advanced Topics in Reinforcement Learning Seminar WS 15/16 ±0 ±0 +1 by Tobias Joppen 03.11.2015 Fachbereich Informatik Knowledge Engineering Group Prof.
Temporal Difference Learning & Policy Iteration Advanced Topics in Reinforcement Learning Seminar WS 15/16 ±0 ±0 +1 by Tobias Joppen 03.11.2015 Fachbereich Informatik Knowledge Engineering Group Prof.
Chapter 6: Temporal Difference Learning
 Chapter 6: emporal Difference Learning Objectives of this chapter: Introduce emporal Difference (D) learning Focus first on policy evaluation, or prediction, methods Compare efficiency of D learning with
Chapter 6: emporal Difference Learning Objectives of this chapter: Introduce emporal Difference (D) learning Focus first on policy evaluation, or prediction, methods Compare efficiency of D learning with
An Introduction to Reinforcement Learning
 An Introduction to Reinforcement Learning Shivaram Kalyanakrishnan shivaram@csa.iisc.ernet.in Department of Computer Science and Automation Indian Institute of Science August 2014 What is Reinforcement
An Introduction to Reinforcement Learning Shivaram Kalyanakrishnan shivaram@csa.iisc.ernet.in Department of Computer Science and Automation Indian Institute of Science August 2014 What is Reinforcement
On and Off-Policy Relational Reinforcement Learning
 On and Off-Policy Relational Reinforcement Learning Christophe Rodrigues, Pierre Gérard, and Céline Rouveirol LIPN, UMR CNRS 73, Institut Galilée - Université Paris-Nord first.last@lipn.univ-paris13.fr
On and Off-Policy Relational Reinforcement Learning Christophe Rodrigues, Pierre Gérard, and Céline Rouveirol LIPN, UMR CNRS 73, Institut Galilée - Université Paris-Nord first.last@lipn.univ-paris13.fr
CMU Lecture 12: Reinforcement Learning. Teacher: Gianni A. Di Caro
 CMU 15-781 Lecture 12: Reinforcement Learning Teacher: Gianni A. Di Caro REINFORCEMENT LEARNING Transition Model? State Action Reward model? Agent Goal: Maximize expected sum of future rewards 2 MDP PLANNING
CMU 15-781 Lecture 12: Reinforcement Learning Teacher: Gianni A. Di Caro REINFORCEMENT LEARNING Transition Model? State Action Reward model? Agent Goal: Maximize expected sum of future rewards 2 MDP PLANNING
Animal learning theory
 Animal learning theory Based on [Sutton and Barto, 1990, Dayan and Abbott, 2001] Bert Kappen [Sutton and Barto, 1990] Classical conditioning: - A conditioned stimulus (CS) and unconditioned stimulus (US)
Animal learning theory Based on [Sutton and Barto, 1990, Dayan and Abbott, 2001] Bert Kappen [Sutton and Barto, 1990] Classical conditioning: - A conditioned stimulus (CS) and unconditioned stimulus (US)
Reinforcement Learning. Introduction
 Reinforcement Learning Introduction Reinforcement Learning Agent interacts and learns from a stochastic environment Science of sequential decision making Many faces of reinforcement learning Optimal control
Reinforcement Learning Introduction Reinforcement Learning Agent interacts and learns from a stochastic environment Science of sequential decision making Many faces of reinforcement learning Optimal control
This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer.
 This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer. 1. Suppose you have a policy and its action-value function, q, then you
This question has three parts, each of which can be answered concisely, but be prepared to explain and justify your concise answer. 1. Suppose you have a policy and its action-value function, q, then you
Reinforcement Learning
 Reinforcement Learning Temporal Difference Learning Temporal difference learning, TD prediction, Q-learning, elibigility traces. (many slides from Marc Toussaint) Vien Ngo Marc Toussaint University of
Reinforcement Learning Temporal Difference Learning Temporal difference learning, TD prediction, Q-learning, elibigility traces. (many slides from Marc Toussaint) Vien Ngo Marc Toussaint University of
Short Course: Multiagent Systems. Multiagent Systems. Lecture 1: Basics Agents Environments. Reinforcement Learning. This course is about:
 Short Course: Multiagent Systems Lecture 1: Basics Agents Environments Reinforcement Learning Multiagent Systems This course is about: Agents: Sensing, reasoning, acting Multiagent Systems: Distributed
Short Course: Multiagent Systems Lecture 1: Basics Agents Environments Reinforcement Learning Multiagent Systems This course is about: Agents: Sensing, reasoning, acting Multiagent Systems: Distributed
Reinforcement Learning
 Reinforcement Learning Markov decision process & Dynamic programming Evaluative feedback, value function, Bellman equation, optimality, Markov property, Markov decision process, dynamic programming, value
Reinforcement Learning Markov decision process & Dynamic programming Evaluative feedback, value function, Bellman equation, optimality, Markov property, Markov decision process, dynamic programming, value
Linear Least-squares Dyna-style Planning
 Linear Least-squares Dyna-style Planning Hengshuai Yao Department of Computing Science University of Alberta Edmonton, AB, Canada T6G2E8 hengshua@cs.ualberta.ca Abstract World model is very important for
Linear Least-squares Dyna-style Planning Hengshuai Yao Department of Computing Science University of Alberta Edmonton, AB, Canada T6G2E8 hengshua@cs.ualberta.ca Abstract World model is very important for
Marks. bonus points. } Assignment 1: Should be out this weekend. } Mid-term: Before the last lecture. } Mid-term deferred exam:
 Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
Marks } Assignment 1: Should be out this weekend } All are marked, I m trying to tally them and perhaps add bonus points } Mid-term: Before the last lecture } Mid-term deferred exam: } This Saturday, 9am-10.30am,
1 Introduction 2. 4 Q-Learning The Q-value The Temporal Difference The whole Q-Learning process... 5
 Table of contents 1 Introduction 2 2 Markov Decision Processes 2 3 Future Cumulative Reward 3 4 Q-Learning 4 4.1 The Q-value.............................................. 4 4.2 The Temporal Difference.......................................
Table of contents 1 Introduction 2 2 Markov Decision Processes 2 3 Future Cumulative Reward 3 4 Q-Learning 4 4.1 The Q-value.............................................. 4 4.2 The Temporal Difference.......................................
Seminar in Artificial Intelligence Near-Bayesian Exploration in Polynomial Time
 Seminar in Artificial Intelligence Near-Bayesian Exploration in Polynomial Time 26.11.2015 Fachbereich Informatik Knowledge Engineering Group David Fischer 1 Table of Contents Problem and Motivation Algorithm
Seminar in Artificial Intelligence Near-Bayesian Exploration in Polynomial Time 26.11.2015 Fachbereich Informatik Knowledge Engineering Group David Fischer 1 Table of Contents Problem and Motivation Algorithm
CS 7180: Behavioral Modeling and Decisionmaking
 CS 7180: Behavioral Modeling and Decisionmaking in AI Markov Decision Processes for Complex Decisionmaking Prof. Amy Sliva October 17, 2012 Decisions are nondeterministic In many situations, behavior and
CS 7180: Behavioral Modeling and Decisionmaking in AI Markov Decision Processes for Complex Decisionmaking Prof. Amy Sliva October 17, 2012 Decisions are nondeterministic In many situations, behavior and
CSC321 Lecture 22: Q-Learning
 CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
Chapter 3: The Reinforcement Learning Problem
 Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
Chapter 3: The Reinforcement Learning Problem Objectives of this chapter: describe the RL problem we will be studying for the remainder of the course present idealized form of the RL problem for which
An Introduction to Reinforcement Learning
 An Introduction to Reinforcement Learning Shivaram Kalyanakrishnan shivaram@cse.iitb.ac.in Department of Computer Science and Engineering Indian Institute of Technology Bombay April 2018 What is Reinforcement
An Introduction to Reinforcement Learning Shivaram Kalyanakrishnan shivaram@cse.iitb.ac.in Department of Computer Science and Engineering Indian Institute of Technology Bombay April 2018 What is Reinforcement
ROB 537: Learning-Based Control. Announcements: Project background due Today. HW 3 Due on 10/30 Midterm Exam on 11/6.
 ROB 537: Learning-Based Control Week 5, Lecture 1 Policy Gradient, Eligibility Traces, Transfer Learning (MaC Taylor Announcements: Project background due Today HW 3 Due on 10/30 Midterm Exam on 11/6 Reading:
ROB 537: Learning-Based Control Week 5, Lecture 1 Policy Gradient, Eligibility Traces, Transfer Learning (MaC Taylor Announcements: Project background due Today HW 3 Due on 10/30 Midterm Exam on 11/6 Reading:
Active Policy Iteration: Efficient Exploration through Active Learning for Value Function Approximation in Reinforcement Learning
 Active Policy Iteration: fficient xploration through Active Learning for Value Function Approximation in Reinforcement Learning Takayuki Akiyama, Hirotaka Hachiya, and Masashi Sugiyama Department of Computer
Active Policy Iteration: fficient xploration through Active Learning for Value Function Approximation in Reinforcement Learning Takayuki Akiyama, Hirotaka Hachiya, and Masashi Sugiyama Department of Computer
Lecture 7: Value Function Approximation
 Lecture 7: Value Function Approximation Joseph Modayil Outline 1 Introduction 2 3 Batch Methods Introduction Large-Scale Reinforcement Learning Reinforcement learning can be used to solve large problems,
Lecture 7: Value Function Approximation Joseph Modayil Outline 1 Introduction 2 3 Batch Methods Introduction Large-Scale Reinforcement Learning Reinforcement learning can be used to solve large problems,
A Method for Computing Optimal Set-Point Schedule for HVAC Systems
 MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com A Method for Computing Optimal Set-Point Schedule for HVAC Systems Nikovski, D.; Xu, J.; Nonaka, M. TR2013-050 June 2013 Abstract We propose
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com A Method for Computing Optimal Set-Point Schedule for HVAC Systems Nikovski, D.; Xu, J.; Nonaka, M. TR2013-050 June 2013 Abstract We propose
TAKING INTO ACCOUNT PARAMETRIC UNCERTAINTIES IN ANTICIPATIVE ENERGY MANAGEMENT FOR DWELLINGS
 TAKING INTO ACCOUNT PARAMETRIC UNCERTAINTIES IN ANTICIPATIVE ENERGY MANAGEMENT FOR DWELLINGS Minh Hoang Le, Stephane Ploix and Mireille Jacomino G-SCOP laboratory, Grenoble Institute of Technology 46,
TAKING INTO ACCOUNT PARAMETRIC UNCERTAINTIES IN ANTICIPATIVE ENERGY MANAGEMENT FOR DWELLINGS Minh Hoang Le, Stephane Ploix and Mireille Jacomino G-SCOP laboratory, Grenoble Institute of Technology 46,
Exponential Moving Average Based Multiagent Reinforcement Learning Algorithms
 Exponential Moving Average Based Multiagent Reinforcement Learning Algorithms Mostafa D. Awheda Department of Systems and Computer Engineering Carleton University Ottawa, Canada KS 5B6 Email: mawheda@sce.carleton.ca
Exponential Moving Average Based Multiagent Reinforcement Learning Algorithms Mostafa D. Awheda Department of Systems and Computer Engineering Carleton University Ottawa, Canada KS 5B6 Email: mawheda@sce.carleton.ca
David Silver, Google DeepMind
 Tutorial: Deep Reinforcement Learning David Silver, Google DeepMind Outline Introduction to Deep Learning Introduction to Reinforcement Learning Value-Based Deep RL Policy-Based Deep RL Model-Based Deep
Tutorial: Deep Reinforcement Learning David Silver, Google DeepMind Outline Introduction to Deep Learning Introduction to Reinforcement Learning Value-Based Deep RL Policy-Based Deep RL Model-Based Deep
Reinforcement Learning and NLP
 1 Reinforcement Learning and NLP Kapil Thadani kapil@cs.columbia.edu RESEARCH Outline 2 Model-free RL Markov decision processes (MDPs) Derivative-free optimization Policy gradients Variance reduction Value
1 Reinforcement Learning and NLP Kapil Thadani kapil@cs.columbia.edu RESEARCH Outline 2 Model-free RL Markov decision processes (MDPs) Derivative-free optimization Policy gradients Variance reduction Value
Decision Theory: Markov Decision Processes
 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33 March 31, 2006 Textbook 12.5 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33, Slide 1 Lecture Overview Recap Rewards and Policies
Decision Theory: Markov Decision Processes CPSC 322 Lecture 33 March 31, 2006 Textbook 12.5 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33, Slide 1 Lecture Overview Recap Rewards and Policies
Actor-critic methods. Dialogue Systems Group, Cambridge University Engineering Department. February 21, 2017
 Actor-critic methods Milica Gašić Dialogue Systems Group, Cambridge University Engineering Department February 21, 2017 1 / 21 In this lecture... The actor-critic architecture Least-Squares Policy Iteration
Actor-critic methods Milica Gašić Dialogue Systems Group, Cambridge University Engineering Department February 21, 2017 1 / 21 In this lecture... The actor-critic architecture Least-Squares Policy Iteration
Reinforcement learning
 Reinforcement learning Stuart Russell, UC Berkeley Stuart Russell, UC Berkeley 1 Outline Sequential decision making Dynamic programming algorithms Reinforcement learning algorithms temporal difference
Reinforcement learning Stuart Russell, UC Berkeley Stuart Russell, UC Berkeley 1 Outline Sequential decision making Dynamic programming algorithms Reinforcement learning algorithms temporal difference
Autonomous Helicopter Flight via Reinforcement Learning
 Autonomous Helicopter Flight via Reinforcement Learning Authors: Andrew Y. Ng, H. Jin Kim, Michael I. Jordan, Shankar Sastry Presenters: Shiv Ballianda, Jerrolyn Hebert, Shuiwang Ji, Kenley Malveaux, Huy
Autonomous Helicopter Flight via Reinforcement Learning Authors: Andrew Y. Ng, H. Jin Kim, Michael I. Jordan, Shankar Sastry Presenters: Shiv Ballianda, Jerrolyn Hebert, Shuiwang Ji, Kenley Malveaux, Huy
Trust Region Policy Optimization
 Trust Region Policy Optimization Yixin Lin Duke University yixin.lin@duke.edu March 28, 2017 Yixin Lin (Duke) TRPO March 28, 2017 1 / 21 Overview 1 Preliminaries Markov Decision Processes Policy iteration
Trust Region Policy Optimization Yixin Lin Duke University yixin.lin@duke.edu March 28, 2017 Yixin Lin (Duke) TRPO March 28, 2017 1 / 21 Overview 1 Preliminaries Markov Decision Processes Policy iteration
Reinforcement Learning: An Introduction
 Introduction Betreuer: Freek Stulp Hauptseminar Intelligente Autonome Systeme (WiSe 04/05) Forschungs- und Lehreinheit Informatik IX Technische Universität München November 24, 2004 Introduction What is
Introduction Betreuer: Freek Stulp Hauptseminar Intelligente Autonome Systeme (WiSe 04/05) Forschungs- und Lehreinheit Informatik IX Technische Universität München November 24, 2004 Introduction What is