CS 6140: Machine Learning Spring 2017
|
|
|
- Lorraine Perry
- 5 years ago
- Views:
Transcription
1 CS 6140: Machine Learning Spring 2017 Instructor: Lu Wang College of Computer and Science Northeastern University Webpage:
2 Assignment 3 is due on 3/30. 4/13: course project presenta@on. 4/20: final exam.
3 What we learned labeling models Hidden Markov Models Maximum-entropy Markov model Random Fields
4 Sample Markov Model for POS 0.1 Det 0.95 Noun start PropNoun Verb stop
5 The Markov
6 Hidden Markov Models (HMMs) Words Part-of-Speech tags
7 Formally
8 Viterbi Backtrace s 1 s 0 s 2 s N s F t 1 t 2 t 3 t T-1 t T Most likely Sequence: s 0 s N s 1 s 2 s 2 s F
9 Log-Linear Models
10
11 Using Log-Linear Models
12 Random Fields (CRFs)
13 Today s Outline Bayesian Networks Mixture Models Expecta@on Maximiza@on Latent Dirichlet Alloca@on [Some slides are borrowed from Christopher Bishop and David Sontag]
14
15
16
17
18
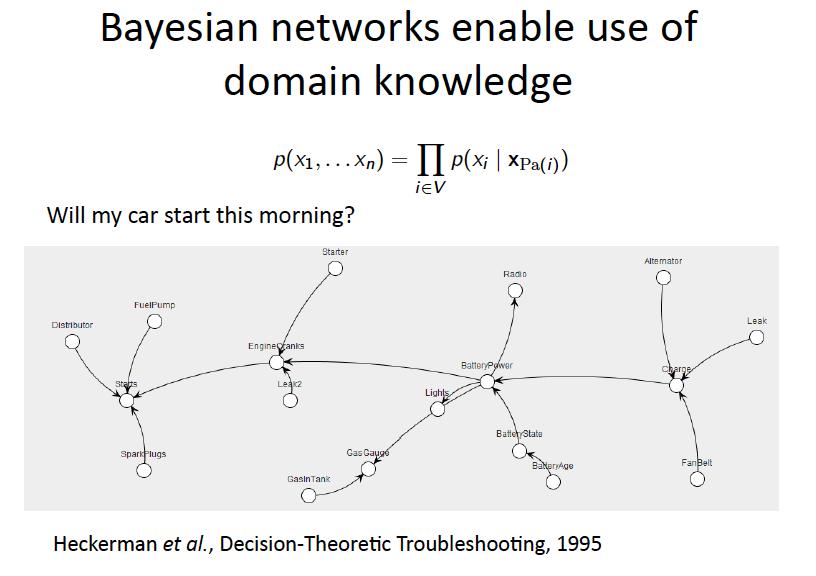
19
20
21
22 Today s Outline Bayesian Networks Mixture Models Expecta@on Maximiza@on Latent Dirichlet Alloca@on

23 K-means Algorithm Goal: represent a data set in terms of K clusters each of which is summarized by a prototype (mean) Ini@alize prototypes, then iterate between two phases: Step 1: assign each data point to nearest prototype Step 2: update prototypes to be the cluster means Simplest version is based on Euclidean distance
24 BCS Summer School, Exeter, 2003 Christopher M. Bishop
25 BCS Summer School, Exeter, 2003 Christopher M. Bishop
26 BCS Summer School, Exeter, 2003 Christopher M. Bishop
27 BCS Summer School, Exeter, 2003 Christopher M. Bishop
28 BCS Summer School, Exeter, 2003 Christopher M. Bishop
29 BCS Summer School, Exeter, 2003 Christopher M. Bishop
30 BCS Summer School, Exeter, 2003 Christopher M. Bishop
31 BCS Summer School, Exeter, 2003 Christopher M. Bishop
32 BCS Summer School, Exeter, 2003 Christopher M. Bishop
33

34
35
36
37
38
39
40 The Gaussian Gaussian mean covariance
41 Gaussian Mixtures Linear of Gaussians and require Can interpret the mixing coefficients as prior
42 Example: Mixture of 3 Gaussians
43 Contours of Probability
44 Sampling from the Gaussian To generate a data point: first pick one of the components with probability then draw a sample from that component Repeat these two steps for each new data point
45 Data Set
46 Data Set Without Labels
47 Fieng the Gaussian Mixture We wish to invert this process given the data set, find the corresponding parameters: mixing coefficients means Covariances
48 Fieng the Gaussian Mixture We wish to invert this process given the data set, find the corresponding parameters: mixing coefficients means covariances If we knew which component generated each data point, the maximum likelihood would involve fieng each component to the corresponding cluster Problem: the data set is unlabelled We shall refer to the labels as latent (= hidden) variables
49 Data Set Without Labels

50 Posterior We can think of the mixing coefficients as prior for the components For a given value of we can evaluate the corresponding posterior probabili@es, called responsibili,es These are given from Bayes theorem by
51 Posterior (colour coded)
52
53
54
55 Today s Outline Bayesian Networks Mixture Models Expecta@on Maximiza@on Latent Dirichlet Alloca@on

56
57
58
59
60
61
62
63
64
65
66
67

68
69
70
71
72 BCS Summer School, Exeter, 2003 Christopher M. Bishop
73 BCS Summer School, Exeter, 2003 Christopher M. Bishop
74 BCS Summer School, Exeter, 2003 Christopher M. Bishop
75 BCS Summer School, Exeter, 2003 Christopher M. Bishop
76 BCS Summer School, Exeter, 2003 Christopher M. Bishop
77 BCS Summer School, Exeter, 2003 Christopher M. Bishop
 The following decomposi@on always holds")
78 EM in General Consider arbitrary over the latent variables (p is the true The following always holds where
79

")
80 the Bound E-step: maximize with respect to equivalent to minimizing KL divergence sets equal to the posterior M-step: maximize bound with respect to equivalent to maximizing expected complete-data log likelihood Each EM cycle must increase incomplete-data likelihood unless already at a (local) maximum
81 E-step
82 M-step
83 Today s Outline Bayesian Networks Mixture Models Expecta@on Maximiza@on Latent Dirichlet Alloca@on [Slides are based on David Blei s ICML 2012 tutorial]

84
85
86
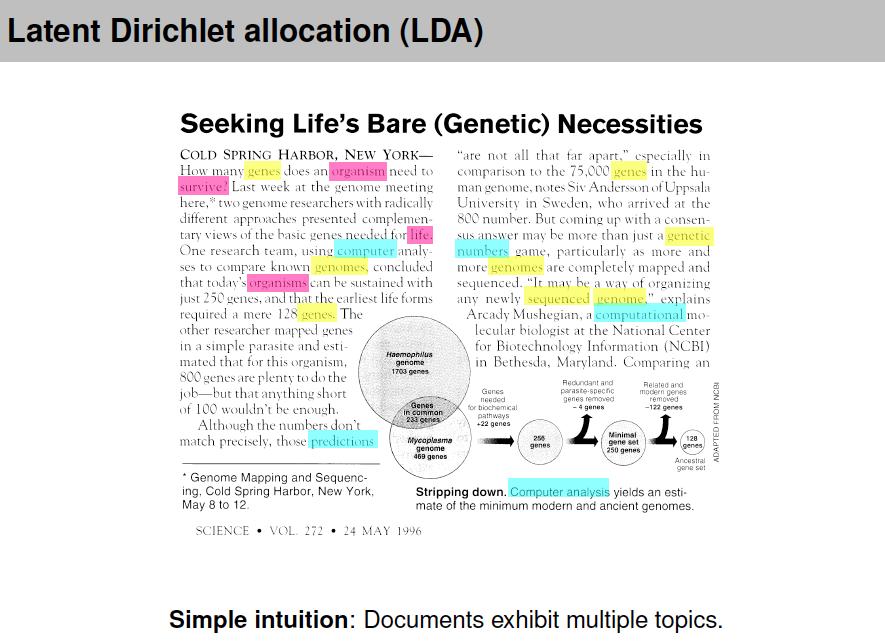
87
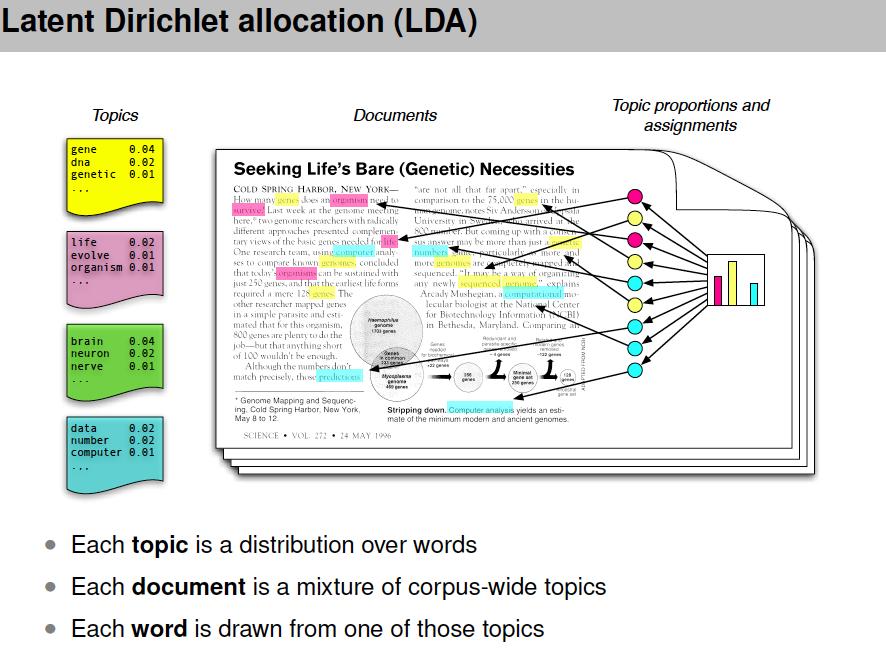
88
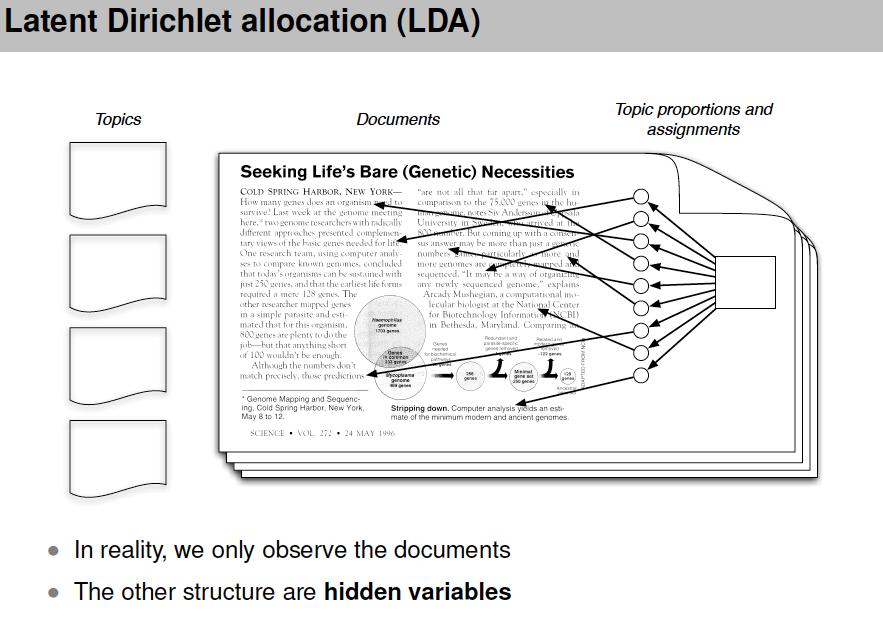
89
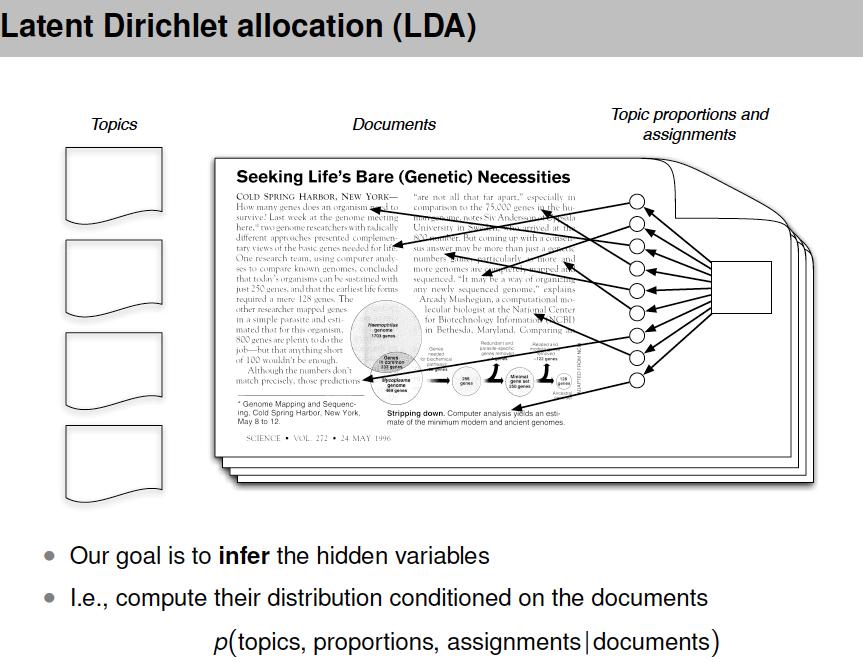
90
91
92
93 model for a document in LDA
94
95
96

97
98

99

100
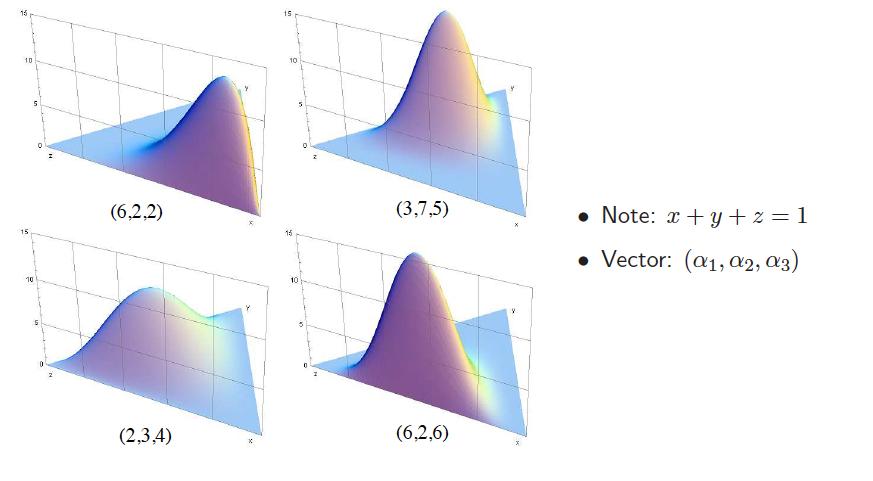
101
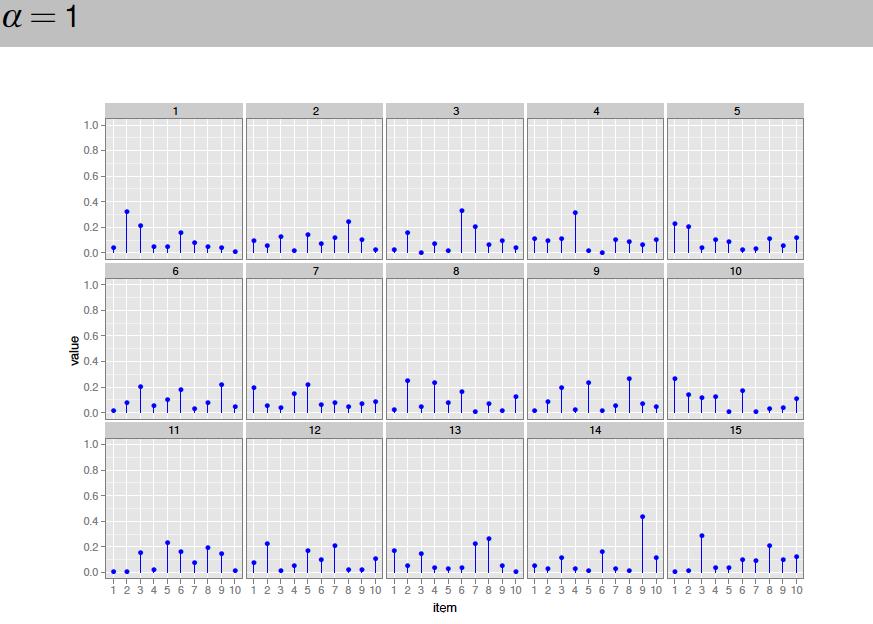
102
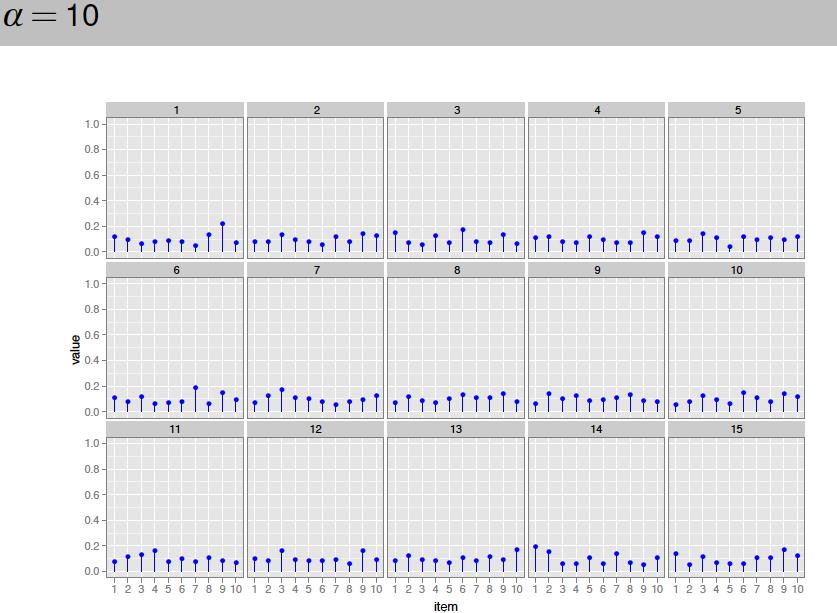
103
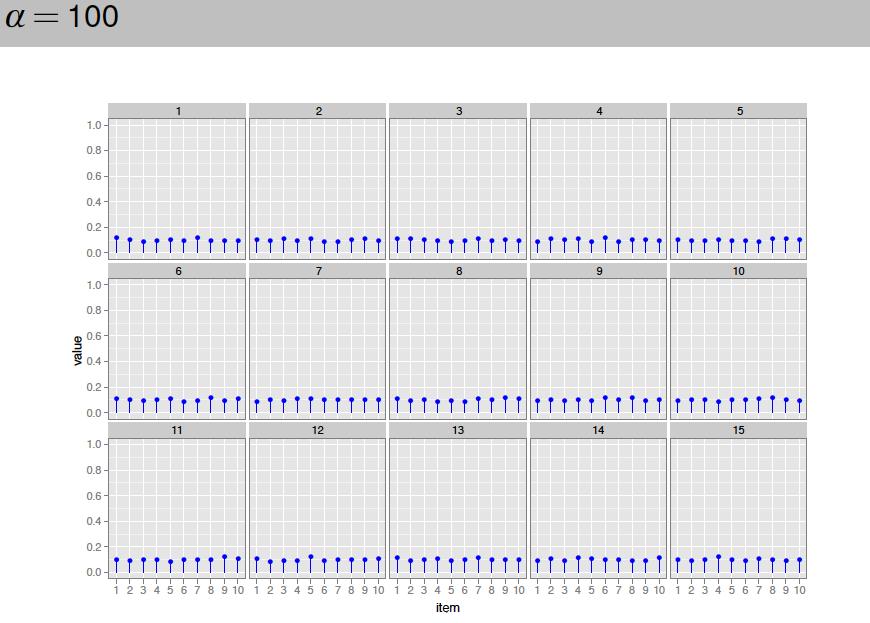
104
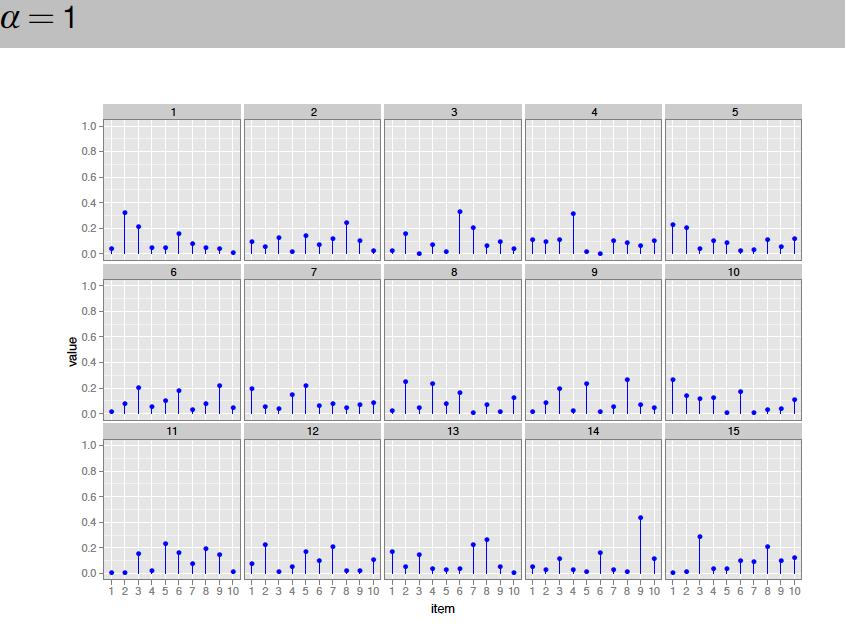
105
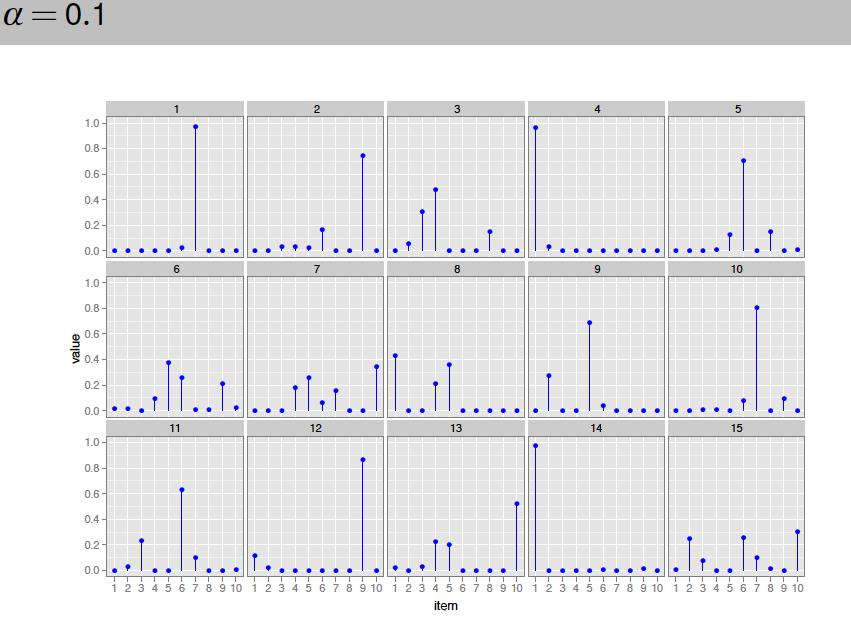
106
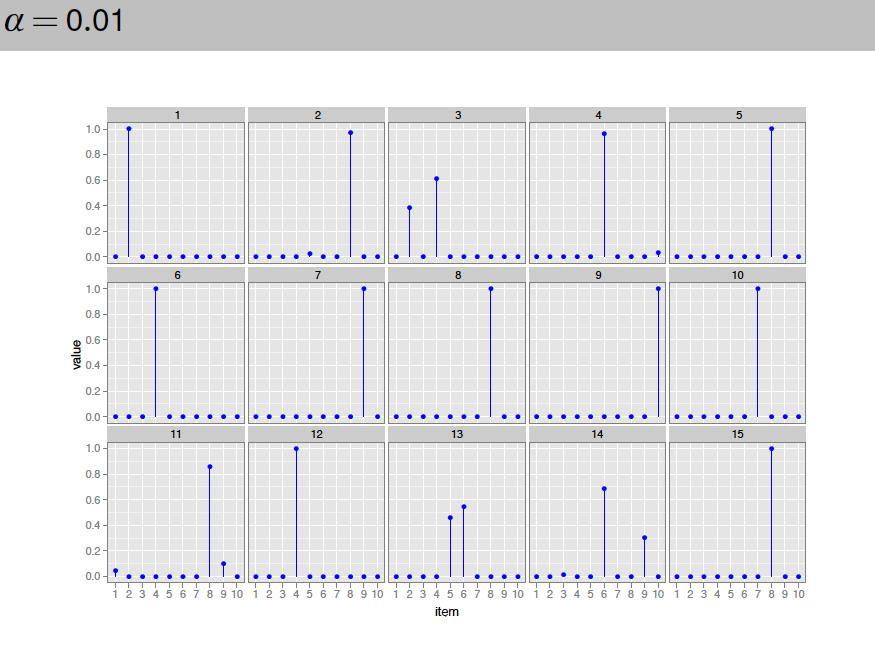
107
108
109 model for a document in LDA
110

111
112 Comparison of mixture and admixture models
113 Usage of LDA
114 EM for mixture models
115 EM for mixture models
116
117

118
119 What We Learned Today Bayesian Networks Mixture Models Latent Dirichlet
120 Homework Reading Murphy , , More about EM hhp://cs229.stanford.edu/notes/cs229-notes7b.pdf hhp://cs229.stanford.edu/notes/cs229-notes8.pdf More about LDA hhp://menome.com/wp/wp-content/uploads/ 2014/12/Blei2011.pdf hhp://obphio.us/pdfs/lda_tutorial.pdf
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a
 Lecture 20.a") Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
CS 6140: Machine Learning Spring What We Learned Last Week. Survey 2/26/16. VS. Model
 Logis@cs CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa@on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Assignment
Logis@cs CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa@on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Assignment
CS 6140: Machine Learning Spring 2016
 CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa?on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Logis?cs Assignment
CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa?on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Logis?cs Assignment
CS 6140: Machine Learning Spring What We Learned Last Week 2/26/16
 Logis@cs CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa@on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Sign
Logis@cs CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa@on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Sign
Latent Dirichlet Alloca/on
 Latent Dirichlet Alloca/on Blei, Ng and Jordan ( 2002 ) Presented by Deepak Santhanam What is Latent Dirichlet Alloca/on? Genera/ve Model for collec/ons of discrete data Data generated by parameters which
Latent Dirichlet Alloca/on Blei, Ng and Jordan ( 2002 ) Presented by Deepak Santhanam What is Latent Dirichlet Alloca/on? Genera/ve Model for collec/ons of discrete data Data generated by parameters which
Statistical Pattern Recognition
 Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2 Agenda Expectation-maximization
Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2 Agenda Expectation-maximization
Statistical Pattern Recognition
 Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 203 http://ce.sharif.edu/courses/9-92/2/ce725-/ Agenda Expectation-maximization
Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 203 http://ce.sharif.edu/courses/9-92/2/ce725-/ Agenda Expectation-maximization
Bayesian networks Lecture 18. David Sontag New York University
 Bayesian networks Lecture 18 David Sontag New York University Outline for today Modeling sequen&al data (e.g., =me series, speech processing) using hidden Markov models (HMMs) Bayesian networks Independence
Bayesian networks Lecture 18 David Sontag New York University Outline for today Modeling sequen&al data (e.g., =me series, speech processing) using hidden Markov models (HMMs) Bayesian networks Independence
Machine Learning & Data Mining CS/CNS/EE 155. Lecture 8: Hidden Markov Models
 Machine Learning & Data Mining CS/CNS/EE 155 Lecture 8: Hidden Markov Models 1 x = Fish Sleep y = (N, V) Sequence Predic=on (POS Tagging) x = The Dog Ate My Homework y = (D, N, V, D, N) x = The Fox Jumped
Machine Learning & Data Mining CS/CNS/EE 155 Lecture 8: Hidden Markov Models 1 x = Fish Sleep y = (N, V) Sequence Predic=on (POS Tagging) x = The Dog Ate My Homework y = (D, N, V, D, N) x = The Fox Jumped
Machine Learning for Data Science (CS4786) Lecture 12
 Lecture 12") Machine Learning for Data Science (CS4786) Lecture 12 Gaussian Mixture Models Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2016fa/ Back to K-means Single link is sensitive to outliners We
Machine Learning for Data Science (CS4786) Lecture 12 Gaussian Mixture Models Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2016fa/ Back to K-means Single link is sensitive to outliners We
Machine Learning Techniques for Computer Vision
 Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
Machine Learning & Data Mining CS/CNS/EE 155. Lecture 11: Hidden Markov Models
 Machine Learning & Data Mining CS/CNS/EE 155 Lecture 11: Hidden Markov Models 1 Kaggle Compe==on Part 1 2 Kaggle Compe==on Part 2 3 Announcements Updated Kaggle Report Due Date: 9pm on Monday Feb 13 th
Machine Learning & Data Mining CS/CNS/EE 155 Lecture 11: Hidden Markov Models 1 Kaggle Compe==on Part 1 2 Kaggle Compe==on Part 2 3 Announcements Updated Kaggle Report Due Date: 9pm on Monday Feb 13 th
Gaussian Mixture Models, Expectation Maximization
 Gaussian Mixture Models, Expectation Maximization Instructor: Jessica Wu Harvey Mudd College The instructor gratefully acknowledges Andrew Ng (Stanford), Andrew Moore (CMU), Eric Eaton (UPenn), David Kauchak
Gaussian Mixture Models, Expectation Maximization Instructor: Jessica Wu Harvey Mudd College The instructor gratefully acknowledges Andrew Ng (Stanford), Andrew Moore (CMU), Eric Eaton (UPenn), David Kauchak
A brief introduction to Conditional Random Fields
 A brief introduction to Conditional Random Fields Mark Johnson Macquarie University April, 2005, updated October 2010 1 Talk outline Graphical models Maximum likelihood and maximum conditional likelihood
A brief introduction to Conditional Random Fields Mark Johnson Macquarie University April, 2005, updated October 2010 1 Talk outline Graphical models Maximum likelihood and maximum conditional likelihood
Latent Dirichlet Allocation (LDA)
") Latent Dirichlet Allocation (LDA) D. Blei, A. Ng, and M. Jordan. Journal of Machine Learning Research, 3:993-1022, January 2003. Following slides borrowed ant then heavily modified from: Jonathan Huang
Latent Dirichlet Allocation (LDA) D. Blei, A. Ng, and M. Jordan. Journal of Machine Learning Research, 3:993-1022, January 2003. Following slides borrowed ant then heavily modified from: Jonathan Huang
Collapsed Variational Bayesian Inference for Hidden Markov Models
 Collapsed Variational Bayesian Inference for Hidden Markov Models Pengyu Wang, Phil Blunsom Department of Computer Science, University of Oxford International Conference on Artificial Intelligence and
Collapsed Variational Bayesian Inference for Hidden Markov Models Pengyu Wang, Phil Blunsom Department of Computer Science, University of Oxford International Conference on Artificial Intelligence and
Latent Variable Models and Expectation Maximization
 Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
Brief Introduction of Machine Learning Techniques for Content Analysis
 1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
13: Variational inference II
 10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
Predicting Sequences: Structured Perceptron. CS 6355: Structured Prediction
 Predicting Sequences: Structured Perceptron CS 6355: Structured Prediction 1 Conditional Random Fields summary An undirected graphical model Decompose the score over the structure into a collection of
Predicting Sequences: Structured Perceptron CS 6355: Structured Prediction 1 Conditional Random Fields summary An undirected graphical model Decompose the score over the structure into a collection of
p L yi z n m x N n xi
 y i z n x n N x i Overview Directed and undirected graphs Conditional independence Exact inference Latent variables and EM Variational inference Books statistical perspective Graphical Models, S. Lauritzen
y i z n x n N x i Overview Directed and undirected graphs Conditional independence Exact inference Latent variables and EM Variational inference Books statistical perspective Graphical Models, S. Lauritzen
Unsupervised learning (part 1) Lecture 19
 Lecture 19") Unsupervised learning (part 1) Lecture 19 David Sontag New York University Slides adapted from Carlos Guestrin, Dan Klein, Luke Ze@lemoyer, Dan Weld, Vibhav Gogate, and Andrew Moore Bayesian networks enable
Unsupervised learning (part 1) Lecture 19 David Sontag New York University Slides adapted from Carlos Guestrin, Dan Klein, Luke Ze@lemoyer, Dan Weld, Vibhav Gogate, and Andrew Moore Bayesian networks enable
Expectation Maximization
 Expectation Maximization Bishop PRML Ch. 9 Alireza Ghane c Ghane/Mori 4 6 8 4 6 8 4 6 8 4 6 8 5 5 5 5 5 5 4 6 8 4 4 6 8 4 5 5 5 5 5 5 µ, Σ) α f Learningscale is slightly Parameters is slightly larger larger
Expectation Maximization Bishop PRML Ch. 9 Alireza Ghane c Ghane/Mori 4 6 8 4 6 8 4 6 8 4 6 8 5 5 5 5 5 5 4 6 8 4 4 6 8 4 5 5 5 5 5 5 µ, Σ) α f Learningscale is slightly Parameters is slightly larger larger
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
Expectation Maximization (EM)
") Expectation Maximization (EM) The Expectation Maximization (EM) algorithm is one approach to unsupervised, semi-supervised, or lightly supervised learning. In this kind of learning either no labels are
Expectation Maximization (EM) The Expectation Maximization (EM) algorithm is one approach to unsupervised, semi-supervised, or lightly supervised learning. In this kind of learning either no labels are
Hidden Markov Models. Aarti Singh Slides courtesy: Eric Xing. Machine Learning / Nov 8, 2010
 Hidden Markov Models Aarti Singh Slides courtesy: Eric Xing Machine Learning 10-701/15-781 Nov 8, 2010 i.i.d to sequential data So far we assumed independent, identically distributed data Sequential data
Hidden Markov Models Aarti Singh Slides courtesy: Eric Xing Machine Learning 10-701/15-781 Nov 8, 2010 i.i.d to sequential data So far we assumed independent, identically distributed data Sequential data
Latent Variable Models and Expectation Maximization
 Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
Expectation Maximization (EM)
") Expectation Maximization (EM) The EM algorithm is used to train models involving latent variables using training data in which the latent variables are not observed (unlabeled data). This is to be contrasted
Expectation Maximization (EM) The EM algorithm is used to train models involving latent variables using training data in which the latent variables are not observed (unlabeled data). This is to be contrasted
A.I. in health informatics lecture 8 structured learning. kevin small & byron wallace
 A.I. in health informatics lecture 8 structured learning kevin small & byron wallace today models for structured learning: HMMs and CRFs structured learning is particularly useful in biomedical applications:
A.I. in health informatics lecture 8 structured learning kevin small & byron wallace today models for structured learning: HMMs and CRFs structured learning is particularly useful in biomedical applications:
Lecture 7: Con3nuous Latent Variable Models
 CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 7: Con3nuous Latent Variable Models All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/
CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 7: Con3nuous Latent Variable Models All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/
L11: Pattern recognition principles
 L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
Expectation Maximization
 Expectation Maximization Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Christopher M. Bishop Learning in DAGs Two things could
Expectation Maximization Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Christopher M. Bishop Learning in DAGs Two things could
Generative Clustering, Topic Modeling, & Bayesian Inference
 Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 Hidden Markov Models Barnabás Póczos & Aarti Singh Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed
Introduction to Machine Learning CMU-10701 Hidden Markov Models Barnabás Póczos & Aarti Singh Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed
CS Lecture 18. Topic Models and LDA
 CS 6347 Lecture 18 Topic Models and LDA (some slides by David Blei) Generative vs. Discriminative Models Recall that, in Bayesian networks, there could be many different, but equivalent models of the same
CS 6347 Lecture 18 Topic Models and LDA (some slides by David Blei) Generative vs. Discriminative Models Recall that, in Bayesian networks, there could be many different, but equivalent models of the same
IEOR E4570: Machine Learning for OR&FE Spring 2015 c 2015 by Martin Haugh. The EM Algorithm
 IEOR E4570: Machine Learning for OR&FE Spring 205 c 205 by Martin Haugh The EM Algorithm The EM algorithm is used for obtaining maximum likelihood estimates of parameters when some of the data is missing.
IEOR E4570: Machine Learning for OR&FE Spring 205 c 205 by Martin Haugh The EM Algorithm The EM algorithm is used for obtaining maximum likelihood estimates of parameters when some of the data is missing.
Log-Linear Models, MEMMs, and CRFs
 Log-Linear Models, MEMMs, and CRFs Michael Collins 1 Notation Throughout this note I ll use underline to denote vectors. For example, w R d will be a vector with components w 1, w 2,... w d. We use expx
Log-Linear Models, MEMMs, and CRFs Michael Collins 1 Notation Throughout this note I ll use underline to denote vectors. For example, w R d will be a vector with components w 1, w 2,... w d. We use expx
Another Walkthrough of Variational Bayes. Bevan Jones Machine Learning Reading Group Macquarie University
 Another Walkthrough of Variational Bayes Bevan Jones Machine Learning Reading Group Macquarie University 2 Variational Bayes? Bayes Bayes Theorem But the integral is intractable! Sampling Gibbs, Metropolis
Another Walkthrough of Variational Bayes Bevan Jones Machine Learning Reading Group Macquarie University 2 Variational Bayes? Bayes Bayes Theorem But the integral is intractable! Sampling Gibbs, Metropolis
Hidden Markov Models
 Hidden Markov Models Slides mostly from Mitch Marcus and Eric Fosler (with lots of modifications). Have you seen HMMs? Have you seen Kalman filters? Have you seen dynamic programming? HMMs are dynamic
Hidden Markov Models Slides mostly from Mitch Marcus and Eric Fosler (with lots of modifications). Have you seen HMMs? Have you seen Kalman filters? Have you seen dynamic programming? HMMs are dynamic
Hidden Markov Models. By Parisa Abedi. Slides courtesy: Eric Xing
 Hidden Markov Models By Parisa Abedi Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed data Sequential (non i.i.d.) data Time-series data E.g. Speech
Hidden Markov Models By Parisa Abedi Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed data Sequential (non i.i.d.) data Time-series data E.g. Speech
Clustering, K-Means, EM Tutorial
 Clustering, K-Means, EM Tutorial Kamyar Ghasemipour Parts taken from Shikhar Sharma, Wenjie Luo, and Boris Ivanovic s tutorial slides, as well as lecture notes Organization: Clustering Motivation K-Means
Clustering, K-Means, EM Tutorial Kamyar Ghasemipour Parts taken from Shikhar Sharma, Wenjie Luo, and Boris Ivanovic s tutorial slides, as well as lecture notes Organization: Clustering Motivation K-Means
Gaussian Mixture Models
 Gaussian Mixture Models Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 Some slides courtesy of Eric Xing, Carlos Guestrin (One) bad case for K- means Clusters may overlap Some
Gaussian Mixture Models Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 Some slides courtesy of Eric Xing, Carlos Guestrin (One) bad case for K- means Clusters may overlap Some
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
CSCI-567: Machine Learning (Spring 2019)
") CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
MIXTURE MODELS AND EM
 Last updated: November 6, 212 MIXTURE MODELS AND EM Credits 2 Some of these slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Simon Prince, University College London Sergios Theodoridis,
Last updated: November 6, 212 MIXTURE MODELS AND EM Credits 2 Some of these slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Simon Prince, University College London Sergios Theodoridis,
Clustering. Professor Ameet Talwalkar. Professor Ameet Talwalkar CS260 Machine Learning Algorithms March 8, / 26
 Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Latent Variable Models
 Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 5 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 5 1 / 31 Recap of last lecture 1 Autoregressive models:
Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 5 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 5 1 / 31 Recap of last lecture 1 Autoregressive models:
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Machine Learning. Gaussian Mixture Models. Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall
 Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Clustering K-means. Clustering images. Machine Learning CSE546 Carlos Guestrin University of Washington. November 4, 2014.
 Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
CSCI 360 Introduc/on to Ar/ficial Intelligence Week 2: Problem Solving and Op/miza/on
 CSCI 360 Introduc/on to Ar/ficial Intelligence Week 2: Problem Solving and Op/miza/on Professor Wei-Min Shen Week 13.1 and 13.2 1 Status Check Extra credits? Announcement Evalua/on process will start soon
CSCI 360 Introduc/on to Ar/ficial Intelligence Week 2: Problem Solving and Op/miza/on Professor Wei-Min Shen Week 13.1 and 13.2 1 Status Check Extra credits? Announcement Evalua/on process will start soon
Clustering VS Classification
 MCQ Clustering VS Classification 1. What is the relation between the distance between clusters and the corresponding class discriminability? a. proportional b. inversely-proportional c. no-relation Ans:
MCQ Clustering VS Classification 1. What is the relation between the distance between clusters and the corresponding class discriminability? a. proportional b. inversely-proportional c. no-relation Ans:
Non-Parametric Bayes
 Non-Parametric Bayes Mark Schmidt UBC Machine Learning Reading Group January 2016 Current Hot Topics in Machine Learning Bayesian learning includes: Gaussian processes. Approximate inference. Bayesian
Non-Parametric Bayes Mark Schmidt UBC Machine Learning Reading Group January 2016 Current Hot Topics in Machine Learning Bayesian learning includes: Gaussian processes. Approximate inference. Bayesian
 Mixture Models Michael Kuhn 2017-8-26 Objec
Mixture Models Michael Kuhn 2017-8-26 Objec The Expectation-Maximization Algorithm
 1/29 EM & Latent Variable Models Gaussian Mixture Models EM Theory The Expectation-Maximization Algorithm Mihaela van der Schaar Department of Engineering Science University of Oxford MLE for Latent Variable
1/29 EM & Latent Variable Models Gaussian Mixture Models EM Theory The Expectation-Maximization Algorithm Mihaela van der Schaar Department of Engineering Science University of Oxford MLE for Latent Variable
Lecture 3: ASR: HMMs, Forward, Viterbi
 Original slides by Dan Jurafsky CS 224S / LINGUIST 285 Spoken Language Processing Andrew Maas Stanford University Spring 2017 Lecture 3: ASR: HMMs, Forward, Viterbi Fun informative read on phonetics The
Original slides by Dan Jurafsky CS 224S / LINGUIST 285 Spoken Language Processing Andrew Maas Stanford University Spring 2017 Lecture 3: ASR: HMMs, Forward, Viterbi Fun informative read on phonetics The
Recent Advances in Bayesian Inference Techniques
 Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
More on HMMs and other sequence models. Intro to NLP - ETHZ - 18/03/2013
 More on HMMs and other sequence models Intro to NLP - ETHZ - 18/03/2013 Summary Parts of speech tagging HMMs: Unsupervised parameter estimation Forward Backward algorithm Bayesian variants Discriminative
More on HMMs and other sequence models Intro to NLP - ETHZ - 18/03/2013 Summary Parts of speech tagging HMMs: Unsupervised parameter estimation Forward Backward algorithm Bayesian variants Discriminative
Conditional Random Fields and beyond DANIEL KHASHABI CS 546 UIUC, 2013
 Conditional Random Fields and beyond DANIEL KHASHABI CS 546 UIUC, 2013 Outline Modeling Inference Training Applications Outline Modeling Problem definition Discriminative vs. Generative Chain CRF General
Conditional Random Fields and beyond DANIEL KHASHABI CS 546 UIUC, 2013 Outline Modeling Inference Training Applications Outline Modeling Problem definition Discriminative vs. Generative Chain CRF General
Lecture 1a: Basic Concepts and Recaps
 Lecture 1a: Basic Concepts and Recaps Cédric Archambeau Centre for Computational Statistics and Machine Learning Department of Computer Science University College London c.archambeau@cs.ucl.ac.uk Advanced
Lecture 1a: Basic Concepts and Recaps Cédric Archambeau Centre for Computational Statistics and Machine Learning Department of Computer Science University College London c.archambeau@cs.ucl.ac.uk Advanced
STA414/2104. Lecture 11: Gaussian Processes. Department of Statistics
 STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
Dimension Reduction (PCA, ICA, CCA, FLD,
 Dimension Reduction (PCA, ICA, CCA, FLD, Topic Models) Yi Zhang 10-701, Machine Learning, Spring 2011 April 6 th, 2011 Parts of the PCA slides are from previous 10-701 lectures 1 Outline Dimension reduction
Dimension Reduction (PCA, ICA, CCA, FLD, Topic Models) Yi Zhang 10-701, Machine Learning, Spring 2011 April 6 th, 2011 Parts of the PCA slides are from previous 10-701 lectures 1 Outline Dimension reduction
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
Mixtures of Gaussians. Sargur Srihari
 Mixtures of Gaussians Sargur srihari@cedar.buffalo.edu 1 9. Mixture Models and EM 0. Mixture Models Overview 1. K-Means Clustering 2. Mixtures of Gaussians 3. An Alternative View of EM 4. The EM Algorithm
Mixtures of Gaussians Sargur srihari@cedar.buffalo.edu 1 9. Mixture Models and EM 0. Mixture Models Overview 1. K-Means Clustering 2. Mixtures of Gaussians 3. An Alternative View of EM 4. The EM Algorithm
Outline of Today s Lecture
 University of Washington Department of Electrical Engineering Computer Speech Processing EE516 Winter 2005 Jeff A. Bilmes Lecture 12 Slides Feb 23 rd, 2005 Outline of Today s
University of Washington Department of Electrical Engineering Computer Speech Processing EE516 Winter 2005 Jeff A. Bilmes Lecture 12 Slides Feb 23 rd, 2005 Outline of Today s
Clustering and Gaussian Mixtures
 Clustering and Gaussian Mixtures Oliver Schulte - CMPT 883 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15 2 25 5 1 15 2 25 detected tures detected
Clustering and Gaussian Mixtures Oliver Schulte - CMPT 883 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15 2 25 5 1 15 2 25 detected tures detected
Mixture of Gaussians Models
 Mixture of Gaussians Models Outline Inference, Learning, and Maximum Likelihood Why Mixtures? Why Gaussians? Building up to the Mixture of Gaussians Single Gaussians Fully-Observed Mixtures Hidden Mixtures
Mixture of Gaussians Models Outline Inference, Learning, and Maximum Likelihood Why Mixtures? Why Gaussians? Building up to the Mixture of Gaussians Single Gaussians Fully-Observed Mixtures Hidden Mixtures
Graphical Models. Lecture 1: Mo4va4on and Founda4ons. Andrew McCallum
 Graphical Models Lecture 1: Mo4va4on and Founda4ons Andrew McCallum mccallum@cs.umass.edu Thanks to Noah Smith and Carlos Guestrin for some slide materials. Board work Expert systems the desire for probability
Graphical Models Lecture 1: Mo4va4on and Founda4ons Andrew McCallum mccallum@cs.umass.edu Thanks to Noah Smith and Carlos Guestrin for some slide materials. Board work Expert systems the desire for probability
Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch. COMP-599 Oct 1, 2015
 Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch COMP-599 Oct 1, 2015 Announcements Research skills workshop today 3pm-4:30pm Schulich Library room 313 Start thinking about
Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch COMP-599 Oct 1, 2015 Announcements Research skills workshop today 3pm-4:30pm Schulich Library room 313 Start thinking about
Probability and Structure in Natural Language Processing
 Probability and Structure in Natural Language Processing Noah Smith, Carnegie Mellon University 2012 Interna@onal Summer School in Language and Speech Technologies Quick Recap Yesterday: Bayesian networks
Probability and Structure in Natural Language Processing Noah Smith, Carnegie Mellon University 2012 Interna@onal Summer School in Language and Speech Technologies Quick Recap Yesterday: Bayesian networks
A minimalist s exposition of EM
 A minimalist s exposition of EM Karl Stratos 1 What EM optimizes Let O, H be a random variables representing the space of samples. Let be the parameter of a generative model with an associated probability
A minimalist s exposition of EM Karl Stratos 1 What EM optimizes Let O, H be a random variables representing the space of samples. Let be the parameter of a generative model with an associated probability
Lecture 12: Algorithms for HMMs
 Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 17 October 2016 updated 9 September 2017 Recap: tagging POS tagging is a
Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 17 October 2016 updated 9 September 2017 Recap: tagging POS tagging is a
Chapter 4 Dynamic Bayesian Networks Fall Jin Gu, Michael Zhang
 Chapter 4 Dynamic Bayesian Networks 2016 Fall Jin Gu, Michael Zhang Reviews: BN Representation Basic steps for BN representations Define variables Define the preliminary relations between variables Check
Chapter 4 Dynamic Bayesian Networks 2016 Fall Jin Gu, Michael Zhang Reviews: BN Representation Basic steps for BN representations Define variables Define the preliminary relations between variables Check
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
MACHINE LEARNING AND PATTERN RECOGNITION Fall 2006, Lecture 8: Latent Variables, EM Yann LeCun
 Y. LeCun: Machine Learning and Pattern Recognition p. 1/? MACHINE LEARNING AND PATTERN RECOGNITION Fall 2006, Lecture 8: Latent Variables, EM Yann LeCun The Courant Institute, New York University http://yann.lecun.com
Y. LeCun: Machine Learning and Pattern Recognition p. 1/? MACHINE LEARNING AND PATTERN RECOGNITION Fall 2006, Lecture 8: Latent Variables, EM Yann LeCun The Courant Institute, New York University http://yann.lecun.com
Statistical learning. Chapter 20, Sections 1 4 1
 Statistical learning Chapter 20, Sections 1 4 Chapter 20, Sections 1 4 1 Outline Bayesian learning Maximum a posteriori and maximum likelihood learning Bayes net learning ML parameter learning with complete
Statistical learning Chapter 20, Sections 1 4 Chapter 20, Sections 1 4 1 Outline Bayesian learning Maximum a posteriori and maximum likelihood learning Bayes net learning ML parameter learning with complete
Linear Dynamical Systems
 Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
Human Mobility Pattern Prediction Algorithm using Mobile Device Location and Time Data
 Human Mobility Pattern Prediction Algorithm using Mobile Device Location and Time Data 0. Notations Myungjun Choi, Yonghyun Ro, Han Lee N = number of states in the model T = length of observation sequence
Human Mobility Pattern Prediction Algorithm using Mobile Device Location and Time Data 0. Notations Myungjun Choi, Yonghyun Ro, Han Lee N = number of states in the model T = length of observation sequence
Hidden Markov Models
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 22 April 2, 2018 1 Reminders Homework
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 22 April 2, 2018 1 Reminders Homework
Lecture 12: Algorithms for HMMs
 Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Sequence labeling. Taking collective a set of interrelated instances x 1,, x T and jointly labeling them
 HMM, MEMM and CRF 40-957 Special opics in Artificial Intelligence: Probabilistic Graphical Models Sharif University of echnology Soleymani Spring 2014 Sequence labeling aking collective a set of interrelated
HMM, MEMM and CRF 40-957 Special opics in Artificial Intelligence: Probabilistic Graphical Models Sharif University of echnology Soleymani Spring 2014 Sequence labeling aking collective a set of interrelated
Learning with Noisy Labels. Kate Niehaus Reading group 11-Feb-2014
 Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
p(d θ ) l(θ ) 1.2 x x x
 l(θ ) 1.2 x x x") p(d θ ).2 x 0-7 0.8 x 0-7 0.4 x 0-7 l(θ ) -20-40 -60-80 -00 2 3 4 5 6 7 θ ˆ 2 3 4 5 6 7 θ ˆ 2 3 4 5 6 7 θ θ x FIGURE 3.. The top graph shows several training points in one dimension, known or assumed to
p(d θ ).2 x 0-7 0.8 x 0-7 0.4 x 0-7 l(θ ) -20-40 -60-80 -00 2 3 4 5 6 7 θ ˆ 2 3 4 5 6 7 θ ˆ 2 3 4 5 6 7 θ θ x FIGURE 3.. The top graph shows several training points in one dimension, known or assumed to
Graphical Models for Collaborative Filtering
 Graphical Models for Collaborative Filtering Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Sequence modeling HMM, Kalman Filter, etc.: Similarity: the same graphical model topology,
Graphical Models for Collaborative Filtering Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Sequence modeling HMM, Kalman Filter, etc.: Similarity: the same graphical model topology,
STAD68: Machine Learning
 STAD68: Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! h0p://www.cs.toronto.edu/~rsalakhu/ Lecture 1 Evalua;on 3 Assignments worth 40%. Midterm worth 20%. Final
STAD68: Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! h0p://www.cs.toronto.edu/~rsalakhu/ Lecture 1 Evalua;on 3 Assignments worth 40%. Midterm worth 20%. Final
Study Notes on the Latent Dirichlet Allocation
 Study Notes on the Latent Dirichlet Allocation Xugang Ye 1. Model Framework A word is an element of dictionary {1,,}. A document is represented by a sequence of words: =(,, ), {1,,}. A corpus is a collection
Study Notes on the Latent Dirichlet Allocation Xugang Ye 1. Model Framework A word is an element of dictionary {1,,}. A document is represented by a sequence of words: =(,, ), {1,,}. A corpus is a collection
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Bayesian Nonparametrics for Speech and Signal Processing
 Bayesian Nonparametrics for Speech and Signal Processing Michael I. Jordan University of California, Berkeley June 28, 2011 Acknowledgments: Emily Fox, Erik Sudderth, Yee Whye Teh, and Romain Thibaux Computer
Bayesian Nonparametrics for Speech and Signal Processing Michael I. Jordan University of California, Berkeley June 28, 2011 Acknowledgments: Emily Fox, Erik Sudderth, Yee Whye Teh, and Romain Thibaux Computer
Generative Model (Naïve Bayes, LDA)
") Generative Model (Naïve Bayes, LDA) IST557 Data Mining: Techniques and Applications Jessie Li, Penn State University Materials from Prof. Jia Li, sta3s3cal learning book (Has3e et al.), and machine learning
Generative Model (Naïve Bayes, LDA) IST557 Data Mining: Techniques and Applications Jessie Li, Penn State University Materials from Prof. Jia Li, sta3s3cal learning book (Has3e et al.), and machine learning
Data Preprocessing. Cluster Similarity
 1 Cluster Similarity Similarity is most often measured with the help of a distance function. The smaller the distance, the more similar the data objects (points). A function d: M M R is a distance on M
1 Cluster Similarity Similarity is most often measured with the help of a distance function. The smaller the distance, the more similar the data objects (points). A function d: M M R is a distance on M
Machine Learning. CUNY Graduate Center, Spring Lectures 11-12: Unsupervised Learning 1. Professor Liang Huang.
 Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
Machine Learning for Signal Processing Expectation Maximization Mixture Models. Bhiksha Raj 27 Oct /
 Machine Learning for Signal rocessing Expectation Maximization Mixture Models Bhiksha Raj 27 Oct 2016 11755/18797 1 Learning Distributions for Data roblem: Given a collection of examples from some data,
Machine Learning for Signal rocessing Expectation Maximization Mixture Models Bhiksha Raj 27 Oct 2016 11755/18797 1 Learning Distributions for Data roblem: Given a collection of examples from some data,
Machine Learning and Bayesian Inference. Unsupervised learning. Can we find regularity in data without the aid of labels?
 Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
AN INTRODUCTION TO TOPIC MODELS
 AN INTRODUCTION TO TOPIC MODELS Michael Paul December 4, 2013 600.465 Natural Language Processing Johns Hopkins University Prof. Jason Eisner Making sense of text Suppose you want to learn something about
AN INTRODUCTION TO TOPIC MODELS Michael Paul December 4, 2013 600.465 Natural Language Processing Johns Hopkins University Prof. Jason Eisner Making sense of text Suppose you want to learn something about
Lecture 13 : Variational Inference: Mean Field Approximation
 10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
ECE521 Lecture 19 HMM cont. Inference in HMM
 ECE521 Lecture 19 HMM cont. Inference in HMM Outline Hidden Markov models Model definitions and notations Inference in HMMs Learning in HMMs 2 Formally, a hidden Markov model defines a generative process
ECE521 Lecture 19 HMM cont. Inference in HMM Outline Hidden Markov models Model definitions and notations Inference in HMMs Learning in HMMs 2 Formally, a hidden Markov model defines a generative process